
 | ||
Similar Lobelanine, Enol, Carnitine biosynthesis | ||
Biosynthesis (also called biogenesis or anabolism) is a multi-step, enzyme-catalyzed process where substrates are converted into more complex products in living organisms. In biosynthesis, simple compounds are modified, converted into other compounds, or joined together to form macromolecules. This process often consists of metabolic pathways. Some of these biosynthetic pathways are located within a single cellular organelle, while others involve enzymes that are located within multiple cellular organelles. Examples of these biosynthetic pathways include the production of lipid membrane components and nucleotides.
Contents
- Properties of chemical reactions
- Lipids
- Phospholipids
- Sphingolipids
- Cholesterol
- Nucleotides
- Purine nucleotides
- Pyrimidine nucleotides
- DNA
- Amino acids
- Amino acid basic structure
- Nitrogen source
- The glutamate family of amino acids
- The serine family of amino acids
- The aspartate family of amino acids
- Proteins
- Additional background
- Translation in steps
- Step 1 Initiation
- Step 2 Elongation
- Step 3 Termination
- Diseases associated with macromolecule deficiency
- References
The prerequisite elements for biosynthesis include: precursor compounds, chemical energy (e.g. ATP), and catalytic enzymes which may require coenzymes (e.g.NADH, NADPH). These elements create monomers, the building blocks for macromolecules. Some important biological macromolecules include: proteins, which are composed of amino acid monomers joined via peptide bonds, and DNA molecules, which are composed of nucleotides joined via phosphodiester bonds.
Properties of chemical reactions
Biosynthesis occurs due to a series of chemical reactions. For these reactions to take place, the following elements are necessary:
In the simplest sense, the reactions that occur in biosynthesis have the following format:
Some variations of this basic equation which will be discussed later in more detail are:
- Simple compounds which are converted into other compounds, usually as part of a multiple step reaction pathway. Two examples of this type of reaction occur during the formation of nucleic acids and the charging of tRNA prior to translation. For some of these steps, chemical energy is required:
- Simple compounds that are converted into other compounds with the assistance of cofactors. For example, the synthesis of phospholipids requires acetyl CoA, while the synthesis of another membrane component, shingolipids, requires NADH and FADH for the formation the sphingosine backbone. The general equation for these examples is:
- Simple compounds that join together to create a macromolecule. For example, fatty acids join together to form phopspholipids. In turn, phospholipids and cholesterol interact noncovalently in order to form the lipid bilayer. This reaction may be depicted as follows:
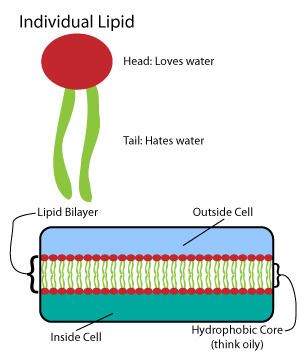
Lipids
Many intricate macromolecules are synthesized in a pattern of simple, repeated structures. For example, the simplest structures of lipids are fatty acids. Fatty acids are hydrocarbon derivatives; they contain a carboxyl group “head” and a hydrocarbon chain “tail.” These fatty acids create larger components, which in turn incorporate noncovalent interactions to form the lipid bilayer. Fatty acid chains are found in two major components of membrane lipids: phospholipids and sphingolipids. A third major membrane component, cholesterol, does not contain these fatty acid units.
Phospholipids
The foundation of all biomembranes consists of a bilayer structure of phospholipids. The phospholipid molecule is amphipathic; it contains a hydrophilic polar head and a hydrophobic nonpolar tail. The phospholipid heads interact with each other and aqueous media, while the hydrocarbon tails orient themselves in the center, away from water. These latter interactions drive the bilayer structure that acts as a barrier for ions and molecules.
There are various types of phospholipids; consequently, their synthesis pathways differ. However, the first step in phospholipid synthesis involves the formation of phosphatidate or diacylglycerol 3-phosphate at the endoplasmic reticulum and outer mitochondrial membrane. The synthesis pathway is found below:
The pathway starts with glycerol 3-phosphate, which gets converted to lysophosphatidate via the addition of a fatty acid chain provided by acyl coenzyme A. Then, lysophosphatidate is converted to phosphatidate via the addition of another fatty acid chain contributed by a second acyl CoA; all of these steps are catalyzed by the glycerol phosphate acyltransferase enzyme. Phospholipid synthesis continues in the endoplasmic reticulum, and the biosynthesis pathway diverges depending on the components of the particular phospholipid.
Sphingolipids
Like phospholipids, these fatty acid derivatives have a polar head and nonpolar tails. Unlike phospholipids, sphingolipids have a sphingosine backbone. Sphingolipids exist in eukaryotic cells and are particularly abundant in the central nervous system. For example, sphingomyelin is part of the myelin sheath of nerve fibers.
Sphingolipids are formed from ceramides that consist of a fatty acid chain attached to the amino group of a sphingosine backbone. These ceramides are synthesized from the acylation of sphingosine. The biosynthetic pathway for sphingosine is found below:
As the image denotes, during sphingosine synthesis, palmitoyl CoA and serine undergo a condensation reaction which results in the formation of dehydrosphingosine. This product is then reduced to form dihydrospingosine, which is converted to sphingosine via the oxidation reaction by FAD.
Cholesterol
This lipid belongs to a class of molecules called sterols. Sterols have four fused rings and a hydroxyl group. Cholesterol is a particularly important molecule. Not only does it serve as a component of lipid membranes, it is also a precursor to several steroid hormones, including cortisol, testosterone, and estrogen.
Cholesterol is synthesized from acetyl CoA. The pathway is shown below:
More generally, this synthesis occurs in three stages, with the first stage taking place in the cytoplasm and the second and third stages occurring in the endoplasmic reticulum. The stages are as follows:
Nucleotides
The biosynthesis of nucleotides involves enzyme-catalyzed reactions that convert substrates into more complex products. Nucleotides are the building blocks of DNA and RNA. Nucleotides are composed of a five-membered ring formed from ribose sugar in RNA, and deoxyribose sugar in DNA; these sugars are linked to a purine or pyrimidine base with a glycosidic bond and a phosphate group at the 5’ location of the sugar.
Purine nucleotides
The DNA nucleosides adenosine and guanosine consist of a purine base attached to a ribose sugar with a glycosidic bond. In the case of RNA nucleotides deoxyadenosine and deoxyguanosine, the purine bases are attached to a deoxyribose sugar with a glycosidic bond. The purine bases on DNA and RNA nucleotides are synthesized in a twelve-step reaction mechanism present in most single-celled organisms. Higher eukaryotes employ a similar reaction mechanism in ten reaction steps. Purine bases are synthesized by converting phosphoribosyl pyrophosphate (PRPP) to inosine monophosphate (IMP), which is the first key intermediate in purine base biosynthesis. Further enzymatic modification of IMP produces the adenosine and guanosine bases of nucleotides.
- The first step in purine biosynthesis is a condensation reaction, performed by glutamine-PRPP amidotransferase. This enzyme transfers the amino group from glutamine to PRPP, forming 5-phosphoribosylamine. The following step requires the activation of glycine by the addition of a phosphate group from ATP.
- GAR synthetase performs the condensation of activated glycine onto PRPP, forming glycineamide ribonucleotide (GAR).
- GAR transformylase adds a formyl group onto the amino group of GAR, forming formylglycinamide ribonucleotide (FGAR).
- FGAR amidotransferase catalyzes the addition of a nitrogen group to FGAR, forming formylglycinamidine ribonucleotide (FGAM).
- FGAM cyclase catalyzes ring closure, which involves removal of a water molecule, forming the 5-membered imidazole ring 5-aminoimidazole ribonucleotide (AIR).
- N5-CAIR synthetase transfers a carboxyl group, forming the intermediate N5-carboxyaminoimidazole ribonucleotide (N5-CAIR).
- N5-CAIR mutase rearranges the carboxyl functional group and transfers it onto the imidazole ring, forming carboxyamino- imidazole ribonucleotide (CAIR). The two step mechanism of CAIR formation from AIR is mostly found in single celled organisms. Higher eukaryotes contain the enzyme AIR carboxylase, which transfers a carboxyl group directly to AIR imidazole ring, forming CAIR.
- SAICAR synthetase forms a peptide bond between aspartate and the added carboxyl group of the imidazole ring, forming N-succinyl-5-aminoimidazole-4-carboxamide ribonucleotide (SAICAR).
- SAICAR lyase removes the carbon skeleton of the added aspartate, leaving the amino group and forming 5-aminoimidazole-4-carboxamide ribonucleotide (AICAR).
- AICAR transformylase transfers a carbonyl group to AICAR, forming N-formylaminoimidazole- 4-carboxamide ribonucleotide (FAICAR).
- The final step involves the enzyme IMP synthase, which performs the purine ring closure and forms the inosine monophosphate (IMP) intermediate.
Pyrimidine nucleotides
Other DNA and RNA nucleotide bases that are linked to the ribose sugar via a glycosidic bond are thymine, cytosine and uracil (which is only found in RNA). Uridine monophosphate biosynthesis involves an enzyme that is located in the mitochondrial inner membrane and multifunctional enzymes that are located in the cytosol.
- The first step involves the enzyme carbamoyl phosphate synthase combining glutamine with CO2 in an ATP dependent reaction to form carbamoyl phosphate.
- Aspartate carbamoyltransferase condenses carbamoyl phosphate with aspartate to form uridosuccinate.
- Dihydroorotase performs ring closure, a reaction that loses water, to form dihydroorotate.
- Dihydroorotate dehydrogenase, located within the mitochondrial inner membrane, oxidizes dihydroorotate to orotate.
- Orotate phosphoribosyl hydrolase (OMP pyrophosphorylase) condenses orotate with PRPP to form orotidine-5’-phosphate.
- OMP decarboxylase catalyzes the conversion of orotidine-5’-phosphate to UMP.
After the uridine nucleotide base is synthesized, the other bases, cytosine and thymine are synthesized. Cytosine biosynthesis is a two-step reaction which involves the conversion of UMP to UTP. Phosphate addition to UMP is catalyzed by a kinase enzyme. The enzyme CTP synthase catalyzes the next reaction step: the conversion of UTP to CTP by transferring an amino group from glutamine to uridine; this forms the cytosine base of CTP. The mechanism, which depicts the reaction UTP + ATP + glutamine ⇔ CTP + ADP + glutamate, is below:
Cytosine is a nucleotide that is present in both DNA and RNA. However, uracil is only found in RNA. Therefore, after UTP is synthesized, it is must be converted into a deoxy form to be incorporated into DNA. This conversion involves the enzyme ribonucleoside triphosphate reductase. This reaction that removes the 2’-OH of the ribose sugar to generate deoxyribose is not affected by the bases attached to the sugar. This non-specificity allows ribonucleoside triphosphate reductase to convert all nucleotide triphosphates to deoxyribonucleotide by a similar mechanism.
In contrast to uracil, thymine bases are found mostly in DNA, not RNA. Cells do not normally contain thymine bases that are linked to ribose sugars in RNA, thus indicating that cells only synthesize deoxyribose-linked thymine. The enzyme thymidylate synthetase is responsible for synthesizing thymine residues from dUMP to dTMP. This reaction transfers a methyl group onto the uracil base of dUMP to generate dTMP. The thymidylate synthase reaction, dUMP + 5,10-methylenetetrahydrofolate ⇔ dTMP + dihydrofolate, is shown to the right.
DNA
Although there are differences between eukaryotic and prokaryotic DNA synthesis, the following section denotes key characteristics of DNA replication shared by both organisms.
DNA is composed of nucleotides that are joined by phosphodiester bonds. DNA synthesis, which takes place in the nucleus, is a semiconservative process, which means that the resulting DNA molecule contains an original strand from the parent structure and a new strand. DNA synthesis is catalyzed by a family of DNA polymerases that require four deoxynucleoside triphosphates, a template strand, and a primer with a free 3’OH in which to incorporate nucleotides.
In order for DNA replication to occur, a replication fork is created by enzymes called helicases which unwind the DNA helix. Topoisomerases at the replication fork remove supercoils caused by DNA unwinding, and single-stranded DNA binding proteins maintain the two single-stranded DNA templates stabilized prior to replication.
DNA synthesis is initiated by the RNA polymerase primase, which makes an RNA primer with a free 3’OH. This primer is attached to the single-stranded DNA template, and DNA polymerase elongates the chain by incorporating nucleotides; DNA polymerase also proofreads the newly synthesized DNA strand.
During the polymerization reaction catalyzed by DNA polymerase, a nucleophilic attack occurs by the 3’OH of the growing chain on the innermost phosphorus atom of a deoxynucleoside triphosphate; this yields the formation of a phosphodiester bridge that attaches a new nucleotide and releases pyrophosphate.
Two types of strands are created simultaneously during replication: the leading strand, which is synthesized continuously and grows towards the replication fork, and the lagging strand, which is made discontinuously in Okazaki fragments and grows away from the replication fork. Okazaki fragments are covalently joined by DNA ligase to form a continuous strand. Then, to complete DNA replication, RNA primers are removed, and the resulting gaps are replaced with DNA and joined via DNA ligase.
Amino acids
A protein is a polymer that is composed from amino acids that are linked by peptide bonds. There are more than 300 amino acids found in nature of which only twenty, known as the standard amino acids, are the building blocks for protein. Only green plants and most microbes are able to synthesize all of the 20 standard amino acids that are needed by all living species. Mammals can only synthesize ten of the twenty standard amino acids. The other amino acids, valine, methionine, leucine, isoleucine, phenylalanine, lysine, threonine and tryptophan for adults and histidine, and arginine for babies are obtained through diet.
Amino acid basic structure
The general structure of the standard amino acids includes a primary amino group, a carboxyl group and the functional group attached to the α-carbon. The different amino acids are identified by the functional group. As a result of the three different groups attached to the α-carbon, amino acids are asymmetrical molecules. For all standard amino acids, except glycine, the α-carbon is a chiral center. In the case of glycine, the α-carbon has two hydrogen atoms, thus adding symmetry to this molecule. With the exception of proline, all of the amino acids found in life have the L-isoform conformation. Proline has a functional group on the α-carbon that forms a ring with the amino group.
Nitrogen source
One major step in amino acid biosynthesis involves incorporating a nitrogen group onto the α-carbon. In cells, there are two major pathways of incorporating nitrogen groups. One pathway involves the enzyme glutamine oxoglutarate aminotransferase (GOGAT) which removes the amide amino group of glutamine and transfers it onto 2-oxoglutarate, producing two glutamate molecules. In this catalysis reaction, glutamine serves as the nitrogen source. An image illustrating this reaction is found to the right.
The other pathway for incorporating nitrogen onto the α-carbon of amino acids involves the enzyme glutamate dehydrogenase (GDH). GDH is able to transfer ammonia onto 2-oxoglutarate and form glutamate. Furthermore, the enzyme glutamine synthetase (GS) is able to transfer ammonia onto glutamate and synthesize glutamine, replenishing glutamine.
The glutamate family of amino acids
The glutamate family of amino acids includes the amino acids that derive from the amino acid glutamate. This family includes: glutamate, glutamine, proline, and arginine. This family also includes the amino acid lysine, which is derived from α-ketoglutarate.
The biosynthesis of glutamate and glutamine is a key step in the nitrogen assimilation discussed above. The enzymes GOGAT and GDH catalyze the nitrogen assimilation reactions.
In bacteria, the enzyme glutamate 5-kinase initiates the biosynthesis of proline by transferring a phosphate group from ATP onto glutamate. The next reaction is catalyzed by the enzyme pyrroline-5-carboxylate synthase (P5CS), which catalyzes the reduction of the ϒ-carboxyl group of L-glutamate 5-phosphate. This results in the formation of glutamate semialdehyde, which spontaneously cyclizes to pyrroline-5-carboxylate. Pyrroline-5-carboxylate is further reduced by the enzyme pyrroline-5-carboxylate reductase (P5CR) to yield a proline amino acid.
In the first step of arginine biosynthesis in bacteria, glutamate is acetylated by transferring the acetyl group from acetyl-CoA at the N-α position; this prevents spontaneous cyclization. The enzyme N-acetylglutamate synthase (glutamate N-acetyltransferase) is responsible for catalyzing the acetylation step. Subsequent steps are catalyzed by the enzymes N-acetylglutamate kinase, N-acetyl-gamma-glutamyl-phosphate reductase, and acetylornithine/succinyldiamino pimelate aminotransferase and yield the N-acetyl-L-ornithine. The acetyl group of acetylornithine is removed by the enzyme acetylornithinase (AO) or ornithine acetyltransferase (OAT), and this yields ornithine. Then, the enzymes citrulline and argininosuccinate convert ornithine to arginine.
There are two distinct lysine biosynthetic pathways: the diaminopimelic acid pathway and the α-aminoadipate pathway. The most common of the two synthetic pathways is the diaminopimelic acid pathway; it consists of several enzymatic reactions that add carbon groups to aspartate to yield lysine:
- Aspartate kinase initiates the diaminopimelic acid pathway by phosphorylating aspartate and producing aspartyl phosphate.
- Aspartate semialdehyde dehydrogenase catalyzes the NADPH-dependent reduction of aspartyl phosphate to yield aspartate semialdehyde.
- 4-hydroxy-tetrahydrodipicolinate synthase adds a pyruvate group to the β-aspartyl-4-semialdehyde, and a water molecule is removed. This causes cyclization and gives rise to (2S,4S)-4-hydroxy-2,3,4,5-tetrahydrodipicolinate.
- 4-hydroxy-tetrahydrodipicolinate reductase catalyzes the reduction of (2S,4S)-4-hydroxy-2,3,4,5-tetrahydrodipicolinate by NADPH to yield Δ’-piperideine-2,6-dicarboxylate (2,3,4,5-tetrahydrodipicolinate) and H2O.
- Tetrahydrodipicolinate acyltransferase catalyzes the acetylation reaction that results in ring opening and yields N-acetyl α-amino-ε-ketopimelate.
- N-succinyl-α-amino-ε-ketopimelate-glutamate aminotransaminase catalyzes the transamination reaction that removes the keto group of N-acetyl α-amino-ε-ketopimelate and replaces it with an amino group to yield N-succinyl-L-diaminopimelate.
- N-acyldiaminopimelate deacylase catalyzes the deacylation of N-succinyl-L-diaminopimelate to yield L,L-diaminopimelate.
- DAP epimerase catalyzes the conversion of L,L-diaminopimelate to the meso form of L,L-diaminopimelate.
- DAP decarboxylase catalyzes the removal of the carboxyl group, yielding L-lysine.
The serine family of amino acids
The serine family of amino acid includes: serine, cysteine, and glycine. Most microorganisms and plants obtain the sulfur for synthesizing methionine from the amino acid cysteine. Furthermore, the conversion of serine to glycine provides the carbons needed for the biosynthesis of the methionine and histidine.
During serine biosynthesis, the enzyme phosphoglycerate dehydrogenase catalyzes the initial reaction that oxidizes 3-phospho-D-glycerate to yield 3-phosphonooxypyruvate. The following reaction is catalyzed by the enzyme phosphoserine aminotransferase, which transfers an amino group from glutamate onto 3-phosphonooxypyruvate to yield L-phosphoserine. The final step is catalyzed by the enzyme phosphoserine phosphatase, which dephosphorylates L-phosphoserine to yield L-serine.
There are two known pathways for the biosynthesis of glycine. Organisms that use ethanol and acetate as the major carbon source utilize the glyconeogenic pathway to synthesize glycine. The other pathway of glycine biosynthesis is known as the glycolytic pathway. This pathway converts serine synthesized from the intermediates of glycolysis to glycine. In the glycolytic pathway, the enzyme serine hydroxymethyltransferase catalyzes the cleavage of serine to yield glycine and transfers the cleaved carbon group of serine onto tetrahydrofolate, forming 5,10-methylene-tetrahydrofolate.
Cysteine biosynthesis is a two-step reaction that involves the incorporation of inorganic sulfur. In microorganisms and plants, the enzyme serine acetyltransferase catalyzes the transfer of acetyl group from acetyl-CoA onto L-serine to yield O-acetyl-L-serine. The following reaction step, catalyzed by the enzyme O-acetyl serine (thiol) lyase, replaces the acetyl group of O-acetyl-L-serine with sulfide to yield cysteine.
The aspartate family of amino acids
The aspartate family of amino acids includes: threonine, lysine, methionine, isoleucine, and aspartate. Lysine and isoleucine are considered part of the aspartate family even though part of their carbon skeleton is derived from pyruvate. In the case of methionine, the methyl carbon is derived from serine and the sulfur group, but in most organisms, it is derived from cysteine.
The biosynthesis of aspartate is a one step reaction that is catalyzed by a single enzyme. The enzyme aspartate aminotransferase catalyzes the transfer of an amino group from aspartate onto α-ketoglutarate to yield glutamate and oxaloacetate. Asparagine is synthesized by an ATP-dependent addition of an amino group onto aspartate; asparagine synthetase catalyzes the addition of nitrogen from glutamine or soluble ammonia to aspartate to yield asparagine.
The diaminopimelic acid biosynthetic pathway of lysine belongs to the aspartate family of amino acids. This pathway involves nine enzyme-catalyzed reactions that convert aspartate to lysine.
- Aspartate kinase catalyzes the initial step in the diaminopimelic acid pathway by transferring a phosphoryl from ATP onto the carboxylate group of aspartate, which yields aspartyl-β-phosphate.
- Aspartate-semialdehyde dehydrogenase catalyzes the reduction reaction by dephosphorylation of aspartyl-β-phosphate to yield aspartate-β-semialdehyde.
- Dihydrodipicolinate synthase catalyzes the condensation reaction of aspartate-β-semialdehyde with pyruvate to yield dihydrodipicolinic acid.
- 4-hydroxy-tetrahydrodipicolinate reductase catalyzes the reduction of dihydrodipicolinic acid to yield tetrahydrodipicolinic acid.
- Tetrahydrodipicolinate N-succinyltransferase catalyzes the transfer of a succinyl group from succinyl-CoA on to tetrahydrodipicolinic acid to yield N-succinyl-L-2,6-diaminoheptanedioate.
- N-succinyldiaminopimelate aminotransferase catalyzes the transfer of an amino group from glutamate onto N-succinyl-L-2,6-diaminoheptanedioate to yield N-succinyl-L,L-diaminopimelic acid.
- Succinyl-diaminopimelate desuccinylase catalyzes the removal of acyl group from N-succinyl-L,L-diaminopimelic acid to yield L,L-diaminopimelic acid.
- Diaminopimelate epimerase catalyzes the inversion of the α-carbon of L,L-diaminopimelic acid to yield meso-diaminopimelic acid.
- Siaminopimelate decarboxylase catalyzes the final step in lysine biosynthesis that removes the carbon dioxide group from meso-diaminopimelic acid to yield L-lysine.
Proteins
Protein synthesis occurs via a process called translation. During translation, genetic material called mRNA is read by ribosomes to generate a protein polypeptide chain. This process requires transfer RNA (tRNA) which serves as an adaptor by binding amino acids on one end and interacting with mRNA at the other end; the latter pairing between the tRNA and mRNA ensures that the correct amino acid is added to the chain. Protein synthesis occurs in three phases: initiation, elongation, and termination. Prokaryotic translation differs from eukaryotic translation; however, this section will mostly focus on the commonalities between the two organisms.
Additional background
Before translation can begin, the process of binding a specific amino acid to its corresponding tRNA must occur. This reaction, called tRNA charging, is catalyzed by aminoacyl tRNA synthetase. A specific tRNA synthetase is responsible for recognizing and charging a particular amino acid. Furthermore, this enzyme has special discriminator regions to ensure the correct binding between tRNA and its cognate amino acid. The first step for joining an amino acid to its corresponding tRNA is the formation of aminoacyl-AMP:
This is followed by the transfer of the aminoacyl group from aminoacyl-AMP to a tRNA molecule. The resulting molecule is aminoacyl-tRNA:
The combination of these two steps, both of which are catalyzed by aminoacyl tRNA synthetase, produces a charged tRNA that is ready to add amino acids to the growing polypeptide chain.
In addition to binding an amino acid, tRNA has a three nucleotide unit called an anticodon that base pairs with specific nucleotide triplets on the mRNA called codons; codons encode a specific amino acid. This interaction is possible thanks to the ribosome, which serves as the site for protein synthesis. The ribosome possesses three tRNA binding sites: the aminoacyl site (A site), the peptidyl site (P site), and the exit site (E site).
There are numerous codons within an mRNA transcript, and it is very common for an amino acid to be specified by more than one codon; this phenomenon is called degeneracy. In all, there are 64 codons, 61 of each code for one of the 20 amino acids, while the remaining codons specify chain termination.
Translation in steps
As previously mentioned, translation occurs in three phases: initiation, elongation, and termination.
Step 1: Initiation
The completion of the initiation phase is dependent on the following three events:
1. The recruitment of the ribosome to mRNA
2. The binding of a charged initiator tRNA into the P site of the ribosome
3. The proper alignment of the ribosome with mRNA’s start codon
Step 2: Elongation
Following initiation, the polypeptide chain is extended via anticodon:codon interactions, with the ribosome adding amino acids to the polypeptide chain one at a time. The following steps must occur to ensure the correct addition of amino acids:
1. The binding of the correct tRNA into the A site of the ribosome
2. The formation of a peptide bond between the tRNA in the A site and the polypeptide chain attached to the tRNA in the P site
3. Translocation or advancement of the tRNA-mRNA complex by three nucleotides
Translocation “kicks off” the tRNA at the E site and shifts the tRNA from the A site into the P site, leaving the A site free for an incoming tRNA to add another amino acid.
Step 3: Termination
The last stage of translation occurs when a stop codon enters the A site. Then, the following steps occur:
1. The recognition of codons by release factors, which causes the hydrolysis of the polypeptide chain from the tRNA located in the P site
2. The release of the polypeptide chain
3. The dissociation and "recycling" of the ribosome for future translation processes
A summary table of the key players in translation is found below:
Diseases associated with macromolecule deficiency
Errors in biosynthetic pathways can have deleterious consequences including the malformation of macromolecules or the underproduction of functional molecules. Below are examples that illustrate the disruptions that occur due to these inefficiencies.