
 | ||
Nucleic acids are biopolymers, or large biomolecules, essential to all known forms of life. They are composed of monomers, which are nucleotides made of three components: a 5-carbon sugar, a phosphate group, and a nitrogenous base. If the sugar is a simple ribose, the polymer is RNA (ribonucleic acid); if the sugar is derived from ribose as deoxyribose, the polymer is DNA (deoxyribonucleic acid).
Contents
- History of nucleic acids
- Occurrence and nomenclature
- Molecular composition and size
- Topology
- Nucleic acid sequences
- Deoxyribonucleic acid
- Ribonucleic acid
- Artificial nucleic acid
- References
Nucleic acids are arguably the most important of all biomolecules. They are found in abundance in all living things, where they function to create and encode and then store information in the nucleus of every living cell of every life-form organism on Earth. In turn, they function to transmit and express that information inside and outside the cell nucleus—to the interior operations of the cell and ultimately to the next generation of each living organism. The encoded information is contained and conveyed via the nucleic acid sequence, which provides the 'ladder-step' ordering of nucleotides within the molecules of RNA and DNA.
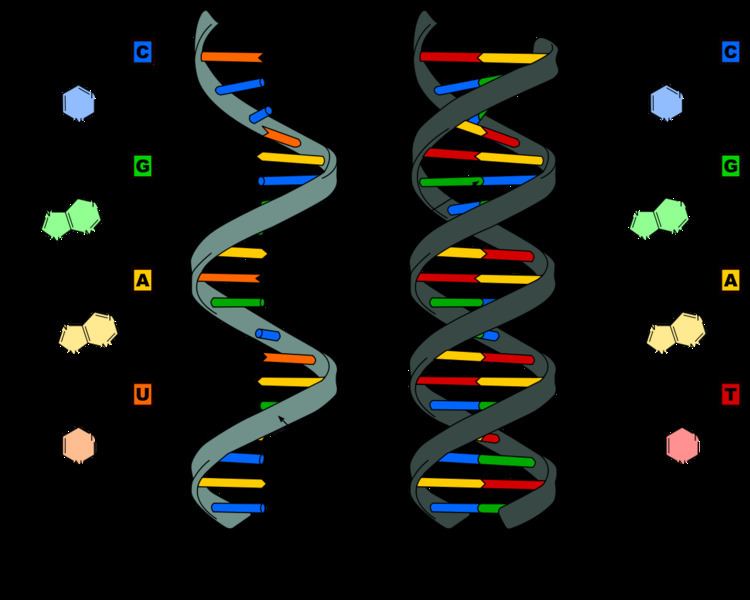
Strings of nucleotides are bonded to form helical backbones—typically, one for RNA, two for DNA—and assembled into chains of base-pairs selected from the five primary, or canonical, nucleobases, which are: adenine, cytosine, guanine, thymine, and uracil; note, thymine occurs only in DNA and uracil only in RNA. Using amino acids and the process known as protein synthesis, the specific sequencing in DNA of these nucleobase-pairs enables storing and transmitting coded instructions as genes. In RNA, base-pair sequencing provides for manufacturing new proteins that determine the frames and parts and most chemical processes of all life forms.
History of nucleic acids
Experimental studies of nucleic acids constitute a major part of modern biological and medical research, and form a foundation for genome and forensic science, and the biotechnology and pharmaceutical industries.
Occurrence and nomenclature
The term nucleic acid is the overall name for DNA and RNA, members of a family of biopolymers, and is synonymous with polynucleotide. Nucleic acids were named for their initial discovery within the nucleus, and for the presence of phosphate groups (related to phosphoric acid). Although first discovered within the nucleus of eukaryotic cells, nucleic acids are now known to be found in all life forms including within bacteria, archaea, mitochondria, chloroplasts, viruses, and viroids. (note: there is debate as to whether viruses are living or non-living). All living cells contain both DNA and RNA (except some cells such as mature red blood cells), while viruses contain either DNA or RNA, but usually not both. The basic component of biological nucleic acids is the nucleotide, each of which contains a pentose sugar (ribose or deoxyribose), a phosphate group, and a nucleobase. Nucleic acids are also generated within the laboratory, through the use of enzymes (DNA and RNA polymerases) and by solid-phase chemical synthesis. The chemical methods also enable the generation of altered nucleic acids that are not found in nature, for example peptide nucleic acids.
Molecular composition and size
Nucleic acids are generally very large molecules. Indeed, DNA molecules are probably the largest individual molecules known. Well-studied biological nucleic acid molecules range in size from 21 nucleotides (small interfering RNA) to large chromosomes (human chromosome 1 is a single molecule that contains 247 million base pairs).
In most cases, naturally occurring DNA molecules are double-stranded and RNA molecules are single-stranded. There are numerous exceptions, however—some viruses have genomes made of double-stranded RNA and other viruses have single-stranded DNA genomes, and, in some circumstances, nucleic acid structures with three or four strands can form.
Nucleic acids are linear polymers (chains) of nucleotides. Each nucleotide consists of three components: a purine or pyrimidine nucleobase (sometimes termed nitrogenous base or simply base), a pentose sugar, and a phosphate group. The substructure consisting of a nucleobase plus sugar is termed a nucleoside. Nucleic acid types differ in the structure of the sugar in their nucleotides–DNA contains 2'-deoxyribose while RNA contains ribose (where the only difference is the presence of a hydroxyl group). Also, the nucleobases found in the two nucleic acid types are different: adenine, cytosine, and guanine are found in both RNA and DNA, while thymine occurs in DNA and uracil occurs in RNA.
The sugars and phosphates in nucleic acids are connected to each other in an alternating chain (sugar-phosphate backbone) through phosphodiester linkages. In conventional nomenclature, the carbons to which the phosphate groups attach are the 3'-end and the 5'-end carbons of the sugar. This gives nucleic acids directionality, and the ends of nucleic acid molecules are referred to as 5'-end and 3'-end. The nucleobases are joined to the sugars via an N-glycosidic linkage involving a nucleobase ring nitrogen (N-1 for pyrimidines and N-9 for purines) and the 1' carbon of the pentose sugar ring.
Non-standard nucleosides are also found in both RNA and DNA and usually arise from modification of the standard nucleosides within the DNA molecule or the primary (initial) RNA transcript. Transfer RNA (tRNA) molecules contain a particularly large number of modified nucleosides.
Topology
Double-stranded nucleic acids are made up of complementary sequences, in which extensive Watson-Crick base pairing results in a highly repeated and quite uniform double-helical three-dimensional structure. In contrast, single-stranded RNA and DNA molecules are not constrained to a regular double helix, and can adopt highly complex three-dimensional structures that are based on short stretches of intramolecular base-paired sequences including both Watson-Crick and noncanonical base pairs, and a wide range of complex tertiary interactions.
Nucleic acid molecules are usually unbranched, and may occur as linear and circular molecules. For example, bacterial chromosomes, plasmids, mitochondrial DNA, and chloroplast DNA are usually circular double-stranded DNA molecules, while chromosomes of the eukaryotic nucleus are usually linear double-stranded DNA molecules. Most RNA molecules are linear, single-stranded molecules, but both circular and branched molecules can result from RNA splicing reactions.
Nucleic acid sequences
One DNA or RNA molecule differs from another primarily in the sequence of nucleotides. Nucleotide sequences are of great importance in biology since they carry the ultimate instructions that encode all biological molecules, molecular assemblies, subcellular and cellular structures, organs, and organisms, and directly enable cognition, memory, and behavior (See: Genetics). Enormous efforts have gone into the development of experimental methods to determine the nucleotide sequence of biological DNA and RNA molecules, and today hundreds of millions of nucleotides are sequenced daily at genome centers and smaller laboratories worldwide. In addition to maintaining the GenBank nucleic acid sequence database, the National Center for Biotechnology Information (NCBI, http://www.ncbi.nlm.nih.gov) provides analysis and retrieval resources for the data in GenBank and other biological data made available through the NCBI Web site
Deoxyribonucleic acid
Deoxyribonucleic acid (DNA) is a nucleic acid containing the genetic instructions used in the development and functioning of all known living organisms. The DNA segments carrying this genetic information are called genes. Likewise, other DNA sequences have structural purposes, or are involved in regulating the use of this genetic information. Along with RNA and proteins, DNA is one of the three major macromolecules that are essential for all known forms of life. DNA consists of two long polymers of simple units called nucleotides, with backbones made of sugars and phosphate groups joined by ester bonds. These two strands run in opposite directions to each other and are, therefore, anti-parallel. Attached to each sugar is one of four types of molecules called nucleobases (informally, bases). It is the sequence of these four nucleobases along the backbone that encodes information. This information is read using the genetic code, which specifies the sequence of the amino acids within proteins. The code is read by copying stretches of DNA into the related nucleic acid RNA in a process called transcription. Within cells DNA is organized into long structures called chromosomes. During cell division these chromosomes are duplicated in the process of DNA replication, providing each cell its own complete set of chromosomes. Eukaryotic organisms (animals, plants, fungi, and protists) store most of their DNA inside the cell nucleus and some of their DNA in organelles, such as mitochondria or chloroplasts. In contrast, prokaryotes (bacteria and archaea) store their DNA only in the cytoplasm. Within the chromosomes, chromatin proteins such as histones compact and organize DNA. These compact structures guide the interactions between DNA and other proteins, helping control which parts of the DNA are transcribed.
Ribonucleic acid
Ribonucleic acid (RNA) functions in converting genetic information from genes into the amino acid sequences of proteins. The three universal types of RNA include transfer RNA (tRNA), messenger RNA (mRNA), and ribosomal RNA (rRNA). Messenger RNA acts to carry genetic sequence information between DNA and ribosomes, directing protein synthesis. Ribosomal RNA is a major component of the ribosome, and catalyzes peptide bond formation. Transfer RNA serves as the carrier molecule for amino acids to be used in protein synthesis, and is responsible for decoding the mRNA. In addition, many other classes of RNA are now known.
Artificial nucleic acid
Artificial nucleic acid analogues have been designed and synthesized by chemists, and include peptide nucleic acid, morpholino- and locked nucleic acid, glycol nucleic acid, and threose nucleic acid. Each of these is distinguished from naturally occurring DNA or RNA by changes to the backbone of the molecules.