
 | ||
In probability theory and information theory, the mutual information (MI) of two random variables is a measure of the mutual dependence between the two variables. More specifically, it quantifies the "amount of information" (in units such as bits) obtained about one random variable, through the other random variable. The concept of mutual information is intricately linked to that of entropy of a random variable, a fundamental notion in information theory, that defines the "amount of information" held in a random variable.
Contents
- Definition
- Relation to other quantities
- Variations
- Metric
- Conditional mutual information
- Multivariate mutual information
- Applications
- Directed information
- Normalized variants
- Weighted variants
- Adjusted mutual information
- Absolute mutual information
- Linear correlation
- For discrete data
- References
Not limited to real-valued random variables like the correlation coefficient, MI is more general and determines how similar the joint distribution p(X,Y) is to the products of factored marginal distribution p(X)p(Y). MI is the expected value of the pointwise mutual information (PMI). The most common unit of measurement of mutual information is the bit.
Definition
Formally, the mutual information of two discrete random variables X and Y can be defined as:
where p(x,y) is the joint probability distribution function of X and Y, and
In the case of continuous random variables, the summation is replaced by a definite double integral:
where p(x,y) is now the joint probability density function of X and Y, and
If the log base 2 is used, the units of mutual information are the bit.
Intuitively, mutual information measures the information that X and Y share: it measures how much knowing one of these variables reduces uncertainty about the other. For example, if X and Y are independent, then knowing X does not give any information about Y and vice versa, so their mutual information is zero. At the other extreme, if X is a deterministic function of Y and Y is a deterministic function of X then all information conveyed by X is shared with Y: knowing X determines the value of Y and vice versa. As a result, in this case the mutual information is the same as the uncertainty contained in Y (or X) alone, namely the entropy of Y (or X). Moreover, this mutual information is the same as the entropy of X and as the entropy of Y. (A very special case of this is when X and Y are the same random variable.)
Mutual information is a measure of the inherent dependence expressed in the joint distribution of X and Y relative to the joint distribution of X and Y under the assumption of independence. Mutual information therefore measures dependence in the following sense: I(X; Y) = 0 if and only if X and Y are independent random variables. This is easy to see in one direction: if X and Y are independent, then p(x,y) = p(x) p(y), and therefore:
Moreover, mutual information is nonnegative (i.e. I(X;Y) ≥ 0; see below) and symmetric (i.e. I(X;Y) = I(Y;X)).
Relation to other quantities
Mutual information can be equivalently expressed as
where
Using Jensen's inequality on the definition of mutual information we can show that I(X;Y) is non-negative, consequently,
The proofs of the other identities above are similar.
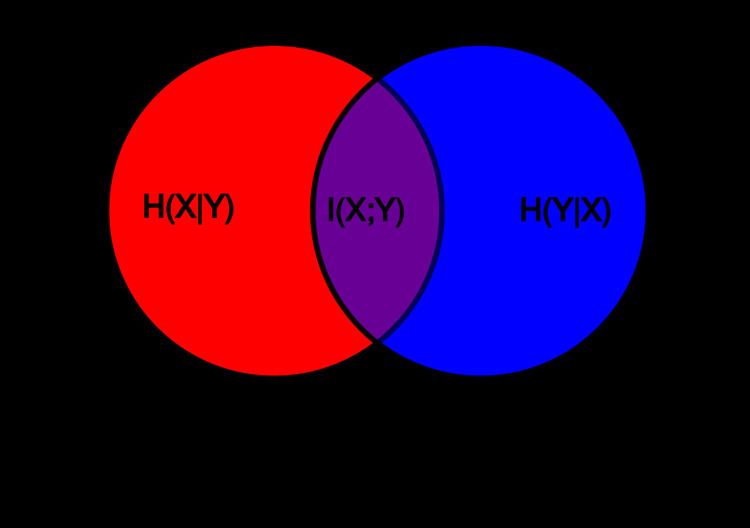
Intuitively, if entropy H(Y) is regarded as a measure of uncertainty about a random variable, then H(Y|X) is a measure of what X does not say about Y. This is "the amount of uncertainty remaining about Y after X is known", and thus the right side of the first of these equalities can be read as "the amount of uncertainty in Y, minus the amount of uncertainty in Y which remains after X is known", which is equivalent to "the amount of uncertainty in Y which is removed by knowing X". This corroborates the intuitive meaning of mutual information as the amount of information (that is, reduction in uncertainty) that knowing either variable provides about the other.
Note that in the discrete case H(X|X) = 0 and therefore H(X) = I(X;X). Thus I(X;X) ≥ I(X;Y), and one can formulate the basic principle that a variable contains at least as much information about itself as any other variable can provide.
Mutual information can also be expressed as a Kullback–Leibler divergence of the product p(x) × p(y) of the marginal distributions of the two random variables X and Y, from p(x,y) the random variables' joint distribution:
Furthermore, let p(x|y) = p(x, y) / p(y). Then
Note that here the Kullback-Leibler divergence involves integration with respect to the random variable X only and the expression
Variations
Several variations on mutual information have been proposed to suit various needs. Among these are normalized variants and generalizations to more than two variables.
Metric
Many applications require a metric, that is, a distance measure between pairs of points. The quantity
satisfies the properties of a metric (triangle inequality, non-negativity, indiscernability and symmetry). This distance metric is also known as the Variation of information.
If
The metric D is a universal metric, in that if any other distance measure places X and Y close-by, then the D will also judge them close.
Plugging in the definitions shows that
In a set-theoretic interpretation of information (see the figure for Conditional entropy), this is effectively the Jaccard distance between X and Y.
Finally,
is also a metric.
Conditional mutual information
Sometimes it is useful to express the mutual information of two random variables conditioned on a third.
which can be simplified as
Conditioning on a third random variable may either increase or decrease the mutual information, but it is always true that
for discrete, jointly distributed random variables X, Y, Z. This result has been used as a basic building block for proving other inequalities in information theory.
Multivariate mutual information
Several generalizations of mutual information to more than two random variables have been proposed, such as total correlation and interaction information. If Shannon entropy is viewed as a signed measure in the context of information diagrams, as explained in the article Information theory and measure theory, then the only definition of multivariate mutual information that makes sense is as follows:
and for
where (as above) we define
(This definition of multivariate mutual information is identical to that of interaction information except for a change in sign when the number of random variables is odd.)
Applications
Applying information diagrams blindly to derive the above definition has been criticised, and indeed it has found rather limited practical application since it is difficult to visualize or grasp the significance of this quantity for a large number of random variables. It can be zero, positive, or negative for any odd number of variables
One high-dimensional generalization scheme which maximizes the mutual information between the joint distribution and other target variables is found to be useful in feature selection.
Mutual information is also used in the area of signal processing as a measure of similarity between two signals. For example, FMI metric is an image fusion performance measure that makes use of mutual information in order to measure the amount of information that the fused image contains about the source images. The Matlab code for this metric can be found at.
Directed information
Directed information,
Note that if
Normalized variants
Normalized variants of the mutual information are provided by the coefficients of constraint, uncertainty coefficient or proficiency:
The two coefficients are not necessarily equal. In some cases a symmetric measure may be desired, such as the following redundancy measure:
which attains a minimum of zero when the variables are independent and a maximum value of
when one variable becomes completely redundant with the knowledge of the other. See also Redundancy (information theory). Another symmetrical measure is the symmetric uncertainty (Witten & Frank 2005), given by
which represents the harmonic mean of the two uncertainty coefficients
If we consider mutual information as a special case of the total correlation or dual total correlation, the normalized version are respectively,
This normalized version also known as Information Quality Ratio (IQR) which quantifies the amount of information of a variable based on another variable against total uncertainty:
There's a normalization which derives from first thinking of mutual information as an analogue to covariance (thus Shannon entropy is analogous to variance). Then the normalized mutual information is calculated akin to the Pearson correlation coefficient,
Weighted variants
In the traditional formulation of the mutual information,
each event or object specified by
For example, the deterministic mapping
which places a weight
Adjusted mutual information
A probability distribution can be viewed as a partition of a set. One may then ask: if a set were partitioned randomly, what would the distribution of probabilities be? What would the expectation value of the mutual information be? The adjusted mutual information or AMI subtracts the expectation value of the MI, so that the AMI is zero when two different distributions are random, and one when two distributions are identical. The AMI is defined in analogy to the adjusted Rand index of two different partitions of a set.
Absolute mutual information
Using the ideas of Kolmogorov complexity, one can consider the mutual information of two sequences independent of any probability distribution:
To establish that this quantity is symmetric up to a logarithmic factor (
Linear correlation
Unlike correlation coefficients, such as the product moment correlation coefficient, mutual information contains information about all dependence—linear and nonlinear—and not just linear dependence as the correlation coefficient measures. However, in the narrow case that both marginal distributions for X and Y are normally distributed and their joint distribution is a bivariate normal distribution, there is an exact relationship between I and the correlation coefficient
For discrete data
When X and Y are limited to be in a discrete number of states, observation data is summarized in a contingency table, with row variable X (or i) and column variable Y (or j). Mutual information is one of the measures of association or correlation between the row and column variables. Other measures of association include Pearson's chi-squared test statistics, G-test statistics, etc. In fact, mutual information is equal to G-test statistics divided by 2N where N is the sample size.
In the special case where the number of states for both row and column variables is 2 (i,j=1,2), the degrees of freedom of the Pearson's chi-squared test is 1. Out of the four terms in the summation:
only one is independent. It is the reason that mutual information function has an exact relationship with the correlation function
Applications
In many applications, one wants to maximize mutual information (thus increasing dependencies), which is often equivalent to minimizing conditional entropy. Examples include: