
 | ||
Sparse distributed memory (SDM) is a mathematical model of human long-term memory introduced by Pentti Kanerva in 1988 while he was at NASA Ames Research Center. It is a generalized random-access memory (RAM) for long (e.g., 1,000 bit) binary words. These words serve as both addresses to and data for the memory. The main attribute of the memory is sensitivity to similarity, meaning that a word can be read back not only by giving the original write address but also by giving one close to it, as measured by the number of mismatched bits (i.e., the Hamming distance between memory addresses).
Contents
- Definition
- The binary space N
- As neural network
- Neuron model
- Neuron as address decoder
- Memory location
- Address pattern
- Data pattern
- Writing
- Reading
- Pointer chains
- Critical distance
- Probabilistic interpretation
- Biological plausibility
- Quantum mechanical interpretation
- Applications
- The Best Match Search
- Speech recognition
- Realizing forgetting
- Genetic sparse distributed memory
- Statistical prediction
- Artificial general intelligence
- Reinforcement learning
- Object indexing in computer vision
- Extensions
- Related patents
- Implementation
- Related models
- References
SDM implements transformation from logical space to physical space using distributed data representation and storage, similarly to encoding processes in human memory. A value corresponding to a logical address is stored into many physical addresses. This way of storing is robust and not deterministic. A memory cell is not addressed directly. If input data (logical addresses) are partially damaged at all, we can still get correct output data.
The theory of the memory is mathematically complete and has been verified by computer simulation. It arose from the observation that the distances between points of a high-dimensional space resemble the proximity relations between concepts in human memory. The theory is also practical in that memories based on it can be implemented with conventional RAM-memory elements.
Definition
Human memory has a tendency to congregate memories based on similarities between them(although they may not be related), such as "firetrucks are red and apples are red". Sparse distributed memory is a mathematical representation of human memory, and uses high-dimensional space to help model the large amounts of memory that mimics that of the human neural network. An important property of such high dimensional spaces is that two randomly chosen vectors are relatively far away from each other, meaning that they are uncorrelated. SDM can be considered a realization of Locality-sensitive hashing.
The underlying idea behind a SDM is the mapping of a huge binary memory onto a smaller set of physical locations, so-called hard locations. As a general guideline, those hard locations should be uniformly distributed in the virtual space, to mimic the existence of the larger virtual space as accurately as possible. Every datum is stored distributed by a set of hard locations, and retrieved by averaging those locations. Therefore, recall may not be perfect, accuracy depending on the saturation of the memory.
Kanerva's proposal is based on four basic ideas:
The binary space N
The SDM works with n-dimensional vectors with binary components. Depending on the context, the vectors are called points, patterns, addresses, words, memory items, data, or events. This section is mostly about the properties of the vector space N =
Concepts Related to the space N:
Properties of the space N:
The space N can be represented by the vertices of the unit cube in n-dimensional Euclidean space. The vertices lie on the surface of an n-dimensional sphere with (Euclidean-metric) radius
The surface of a sphere (in Euclidean 3d-space) clearly is spherical. According to definition, N is also spherical, since y ⊕ x ⊕ (…) is an automorphism that maps x to y. Because N is spherical, it is helpful to think of it as the surface of a sphere with circumference 2n. All points of N are equally qualified as points of origin, and a point and its complement are like two poles at distance n from each other, with the entire space in between. The points halfway between the poles and perpendicular to them are like the equator.
Distribution of the space N
The number of points that are exactly d bits form an arbitrary point x (say, from the point 0) is the number of ways to choose d coordinates from a total of n coordinates, and is therefore given by the binomial coefficient:
The distribution of N thus is the binomial distribution with parameters n and p, where p = 1/2. The mean of the binomial distribution is n/2, and the variance is n/4. This distribution function will be denoted by N(d). The normal distribution F with mean n/2 and standard deviation
Tendency to orthogonality
An outstanding property of N is that most of it lies at approximately the mean (indifference) distance n/2 from a point (and its complement). In other words, most of the space is nearly orthogonal to any given point, and the larger n is, the more pronounced is this effect.
As neural network
The SDM may be regarded either as a content-addressable extension of a classical random-access memory (RAM) or as a special type of three layer feedforward neural network. The main SDM alterations to the RAM are:
Neuron model
An idealized description of neuron is as follows: a neuron has a cell body with two kinds of branches: dendrites and an axon. It receives input signals from other neurons via dendrites, integrates (sums) them and generates its own (electric) output signal which is sent to outside neurons via axon. The points of electric contact between neurons are called synapses.
When a neuron generates signal it is firing and after firing it must recover before it fires again. The relative importance of a synapse to the firing of neuron is called synaptic weight (or input coefficient). There are two kinds of synapses: excitatory that trigger neuron to fire and inhibitory that hinder firing. The neuron is either excitatory or inhibitory according to the kinds of synapses its axon makes.
in addition to input the firing of neuron depends on threshold. The higher the threshold the more important it is that excitatory synapses have input while inhibitory ones do not. Whether a recovered neuron actually fires depends on whether it received sufficient excitatory input (beyond the threshold) and not too much of inhibitory input within a certain period.
The formal model of neuron makes further simplifying assumptions. An n-input neuron is modeled by a linear threshold function
For
The weighted sum of the inputs at time t is defined by
The neuron output at time t is then defined as a boolean function:
Where Ft=1 means that the neuron fires at time t and Ft=0 that it doesn't, i.e. in order for neuron to fire the weighted sum must reach or exceed the threshold . Excitatory inputs increase the sum and inhibitory inputs decrease it.
Neuron as address-decoder
Kanerva's key thesis is that certain neurons could have their input coefficients and thresholds fixed over entire life of an organism and used as address decoders where n-tuple of input coefficients (the pattern to which neurons respond most readily) determines the n-bit memory address, and the threshold controls the size of the region of similar address patterns to which the neuron responds.
This mechanism is complementary to adjustable synapses or adjustable weights in a neural network (perceptron convergence learning), as this fixed accessing mechanism would be a permanent frame of reference which allows to select the synapses in which the information is stored and from which it is retrieved under given set of circumstances. Furthermore, an encoding of the present circumstance would serve as an address.
The address a of a neuron with input coefficients w where
The maximum weighted sum
And the minimum weighted sum
When the threshold c is in range
Memory location
SDM is designed to cope with address patterns that span an enormous address space (order of
Every hard location has associated with it two items:
In SDM a word could be stored in memory by writing it in a free storage location and at the same time providing the location with the appropriate address decoder. A neuron as an address decoder would select a location based on similarity of the location's address to the retrieval cue. Unlike conventional Turing machines SDM is taking advantage of parallel computing by the address decoders. The mere accessing the memory is regarded as computing, the amount of which increases with memory size.
Address pattern
An N-bit vector used in writing to and reading from the memory. The address pattern is a coded description of an environmental state. (e.g. N = 256.)
Data pattern
An M-bit vector that is the object of the writing and reading operations. Like the address pattern, it is a coded description of an environmental state. (e.g. M = 256.)
Writing
Writing is the operation of storing a data pattern into the memory using a particular address pattern. During a write, the input to the memory consists of an address pattern and a data pattern. The address pattern is used to select hard memory locations whose hard addresses are within a certain cutoff distance from the address pattern. The data pattern is stored into each of the selected locations.
Reading
Reading is the operation of retrieving a data pattern from the memory using a particular address pattern. During a read, an address pattern is used to select a certain number of hard memory locations (just like during a write). The contents of the selected locations are bitwise summed and thresholded to derive an M-bit data pattern. This serves as the output read from the memory.
Pointer chains
All of the items are linked in a single list (or array) of pointers to memory locations, and are stored in RAM. Each address in an array points to an individual line in the memory. That line is then returned if it is similar to other lines. Neurons are utilized as address decoders and encoders, similar to the way neurons work in the brain, and return items from the array that match or are similar.
Critical distance
Kanerva's model of memory has a concept of a critical point: prior to this point, a previously stored item can be easily retrieved; but beyond this point an item cannot be retrieved. Kanerva has methodically calculated this point for a particular set of (fixed) parameters. The corresponding critical distance of a Sparse Distributed Memory can be approximately evaluated minimizing the following equation with the restriction
Where:
Probabilistic interpretation
An associative memory system using sparse, distributed representations can be reinterpreted as an importance sampler, a Monte Carlo method of approximating Bayesian inference. The SDM can be considered a Monte Carlo approximation to a multidimensional conditional probability integral. The SDM will produce acceptable responses from a training set when this approximation is valid, that is, when the training set contains sufficient data to provide good estimates of the underlying joint probabilities and there are enough Monte Carlo samples to obtain an accurate estimate of the integral.
Biological plausibility
Sparse coding may be a general strategy of neural systems to augment memory capacity. To adapt to their environments, animals must learn which stimuli are associated with rewards or punishments and distinguish these reinforced stimuli from similar but irrelevant ones. Such task requires implementing stimulus-specific associative memories in which only a few neurons out of a population respond to any given stimulus and each neuron responds to only a few stimuli out of all possible stimuli.
Theoretical work on SDM by Kanerva has suggested that sparse coding increases the capacity of associative memory by reducing overlap between representations. Experimentally, sparse representations of sensory information have been observed in many systems, including vision, audition, touch, and olfaction. However, despite the accumulating evidence for widespread sparse coding and theoretical arguments for its importance, a demonstration that sparse coding improves the stimulus-specificity of associative memory has been lacking until recently.
Some progress has been made in 2014 by Gero Miesenböck's lab at the University of Oxford analyzing Drosophila Olfactory system. In Drosophila, sparse odor coding by the Kenyon cells of the mushroom body is thought to generate a large number of precisely addressable locations for the storage of odor-specific memories. Lin et al. demonstrated that sparseness is controlled by a negative feedback circuit between Kenyon cells and the GABAergic anterior paired lateral (APL) neuron. Systematic activation and blockade of each leg of this feedback circuit show that Kenyon cells activate APL and APL inhibits Kenyon cells. Disrupting the Kenyon cell-APL feedback loop decreases the sparseness of Kenyon cell odor responses, increases inter-odor correlations, and prevents flies from learning to discriminate similar, but not dissimilar, odors. These results suggest that feedback inhibition suppresses Kenyon cell activity to maintain sparse, decorrelated odor coding and thus the odor-specificity of memories.
Quantum-mechanical interpretation
Quantum superposition states that any physical system simultaneously exists in all of its possible states, the number of which is exponential in the number of entities composing the system. The strength of presence of each possible state in the superposition — i.e., the probability with which it would be observed if measured — is represented by its probability amplitude coefficient. The assumption that these coefficients must be represented physically disjointly from each other, i.e., localistically, is nearly universal in the quantum theory/quantum computing literature. Alternatively, as suggested recently by Gerard Rinkus at Brandeis University, these coefficients can be represented using sparse distributed representations (SDR) inline with Kanerva's SDM design, wherein each coefficient is represented by a small subset of an overall population of representational units and the subsets can overlap.
Specifically, If we consider an SDR model in which the overall population consists of Q clusters, each having K binary units, so that each coefficient is represented by a set of Q units, one per cluster. We can then consider the particular world state, X, whose coefficient's representation, R(X), is the set of Q units active at time t to have the maximal probability and the probabilities of all other states, Y, to correspond to the size of the intersection of R(Y) and R(X). Thus, R(X) simultaneously serves both as the representation of the particular state, X, and as a probability distribution over all states. When any given code, e.g., R(A), is active, all other codes stored in the model are also physically active in proportion to their intersection with R(A). Thus, SDR provides a classical realization of quantum superposition in which probability amplitudes are represented directly and implicitly by sizes of set intersections. If algorithms exist for which the time it takes to store (learn) new representations and to find the closest-matching stored representation (probabilistic inference) remains constant as additional representations are stored, this would meet the criterion of quantum computing. (Also see Quantum cognition and Quantum associative memory)
Applications
In applications of the memory, the words are patterns of features. Some features are produced by a sensory system, others control a motor system. There is a current pattern (of e.g. 1000 bits), which is the current contents of the system's focus. The sensors feed into the focus, the motors are driven from the focus, and the memory is accessed through the focus.
What goes on in the world-the system's "subjective" experience-is represented internally by a sequence of patterns in the focus. The memory stores this sequence and can recreate it later in the focus if addressed with a pattern similar to one encountered in the past. Thus, the memory learns to predict what is about to happen. Wide applications of the memory would be in systems that deal with real-world information in real time.
The applications include vision - detecting and identifying objects in a scene and anticipating subsequent scenes - robotics, signal detection and verification, and adaptive learning and control. On the theoretical side, the working of the memory may help us understand memory and learning in humans and animals.
The Best Match Search
SDM can be applied to the problem of finding the best match to a test word in a dataset of stored words. or, in other words, the Nearest neighbor search problem.
Consider a memory with N locations where
To file the data in memory, start by setting
Finding the best match for a test word z, involves placing z in the address register and finding the least distance d for which there is an occupied location. We can start the search by setting
With 100-bit words 2100 locations would be needed, i.e. an enormously large memory. However if we construct the memory as we store the words of the dataset we need only one location (and one address decoder) for each word of the data set. None of the unoccupied locations need to be present. This represents the aspect of sparseness in SDM.
Speech recognition
SDM can be applied in transcribing speech, with the training consisting of "listening" to a large corpus of spoken language. Two hard problems with natural speech are how to detect word boundaries and how to adjust to different speakers. The memory should be able to handle both. First, it stores sequences of patterns as pointer chains. In training—in listening to speech—it will build a probabilistic structure with the highest incidence of branching at word boundaries. In transcribing speech, these branching points are detected and tend to break the stream into segments that correspond to words. Second, the memory's sensitivity to similarity is its mechanism for adjusting to different speakers—and to the variations in the voice of the same speaker.
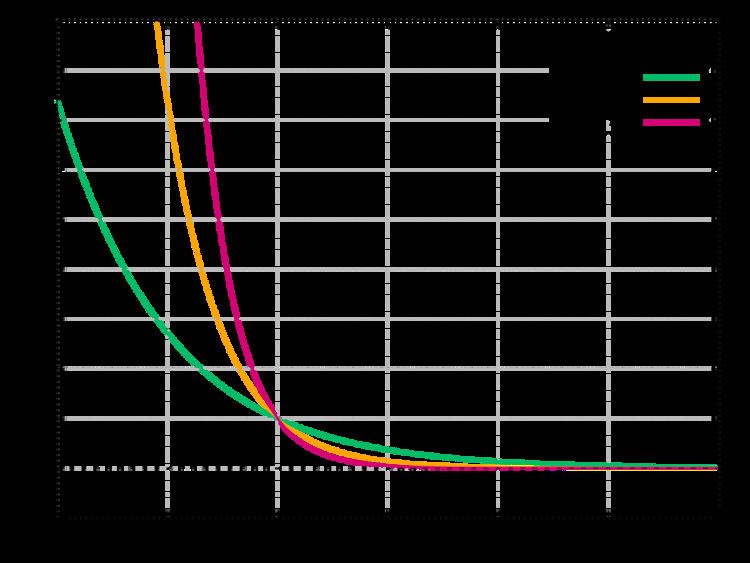
"Realizing forgetting"
At the University of Memphis, Uma Ramamurthy, Sidney K. D'Mello, and Stan Franklin created a modified version of the sparse distributed memory system that represents "realizing forgetting." It uses a decay equation to better show interference in data. The sparse distributed memory system distributes each pattern into approximately one hundredth of the locations, so interference can have detrimental results.
Two possible examples of decay from this modified sparse distributed memory are presented
Exponential decay mechanism:
Negated-translated sigmoid decay mechanism:
In the exponential decay function, it approaches zero more quickly as x increases, and a is a constant(usually between 3-9) and c is a counter. For the negated-translated sigmoid function, the decay is similar to the exponential decay function when a is greater than 4.
As the graph approaches 0, it represents how the memory is being forgotten using decay mechanisms.
Genetic sparse distributed memory
Ashraf Anwar, Stan Franklin, and Dipankar Dasgupta at The University of Memphis; proposed a model for SDM initialization using Genetic Algorithms and Genetic Programming (1999).
Genetic memory uses genetic algorithm and sparse distributed memory as a pseudo artificial neural network. It has been considered for use in creating artificial life.
Statistical prediction
SDM has been applied to statistical prediction, the task of associating extremely large perceptual state vectors with future events. In conditions of near- or over- capacity, where the associative memory behavior of the model breaks down, the processing performed by the model can be interpreted as that of a statistical predictor and each data counter in an SDM can be viewed as an independent estimate of the conditional probability of a binary function f being equal to the activation set defined by the counter's memory location.
Artificial general intelligence
(Also see Cognitive architecture & Artificial General Intelligence for a list of SDM related projects)
Reinforcement learning
SDMs provide a linear, local function approximation scheme, designed to work when a very large/high-dimensional input (address) space has to be mapped into a much smaller physical memory. In general, local architectures, SDMs included, can be subject to the curse of dimensionality, as some target functions may require, in the worst case, an exponential number of local units to be approximated accurately across the entire input space. However, it is widely believed that most decision-making systems need high accuracy only around low-dimensional manifolds of the state space, or important state "highways". The work in Ratitch et al. combined the SDM memory model with the ideas from memory-based learning, which provides an approximator that can dynamically adapt its structure and resolution in order to locate regions of the state space that are "more interesting" and allocate proportionally more memory resources to model them accurately.
Object indexing in computer vision
Dana H. Ballard's lab demonstrated a general-purpose object indexing technique for computer vision that combines the virtues of principal component analysis with the favorable matching properties of high-dimensional spaces to achieve high precision recognition. The indexing algorithm uses an active vision system in conjunction with a modified form of SDM and provides a platform for learning the association between an object's appearance and its identity.
Extensions
Many extensions and improvements to SDM have been proposed, e.g.: