
 | ||
Ancestral reconstruction (also known as Character Mapping or Character Optimization) is the extrapolation back in time from measured characteristics of individuals (or populations) to their common ancestors. It is an important application of phylogenetics, the reconstruction and study of the evolutionary relationships among individuals, populations or species to their ancestors. In the context of evolutionary biology, ancestral reconstruction can be used to recover different kinds of ancestral character states of organisms that lived millions of years ago. These states include the genetic sequence (ancestral sequence reconstruction), the amino acid sequence of a protein, the composition of a genome (e.g., gene order), a measurable characteristic of an organism (phenotype), and the geographic range of an ancestral population or species (ancestral range reconstruction). This is desirable because it allows us to examine parts of phylogenetic trees corresponding to the distant past, clarifying the evolutionary history of the species in the tree. Since modern genetic sequences are essentially a variation of ancient ones, access to ancient sequences may identify other variations and organisms which could have arisen from those sequences. In addition to genetic sequences, one might attempt to track the changing of one character trait to another, such as fins turning to legs.
Contents
- History
- Methods and algorithms
- Maximum parsimony
- Maximum likelihood
- Marginal and joint likelihood
- Bayesian inference
- Empirical and hierarchical Bayes
- Calibration
- Models
- Discrete state models
- Example Binary state speciation and extinction model
- Continuous state models
- Character evolution
- Behavior and life history evolution
- Morphological and physiological character evolution
- Molecular evolution
- Spatial applications
- Linguistic Evolution
- Software
- Other character types
- Web applications
- Future directions
- References
Non-biological applications include the reconstruction of the vocabulary or phonemes of ancient languages, and cultural characteristics of ancient societies such as oral traditions or marriage practices.
Ancestral reconstruction relies on a sufficiently realistic statistical model of evolution to accurately recover ancestral states. These models use the genetic information already obtained through methods such as phylogenetics to determine the route that evolution has taken and when evolutionary events occurred. No matter how well the model approximates the actual evolutionary history, however, one's ability to accurately reconstruct an ancestor deteriorates with increasing evolutionary time between that ancestor and its observed descendants. Additionally, more realistic models of evolution are inevitably more complex and difficult to calculate. Progress in the field of ancestral reconstruction has relied heavily on the exponential growth of computing power and the concomitant development of efficient computational algorithms (e.g., a dynamic programming algorithm for the joint maximum likelihood reconstruction of ancestral sequences.) Methods of ancestral reconstruction are often applied to a given phylogenetic tree that has already been inferred from the same data. While convenient, this approach has the disadvantage that its results are contingent on the accuracy of a single phylogenetic tree. In contrast, some researchers advocate a more computationally intensive Bayesian approach that accounts for uncertainty in tree reconstruction by evaluating ancestral reconstructions over many trees.
History
The concept of ancestral reconstruction is often credited to Emile Zuckerkandl and Linus Pauling. Motivated by the development of techniques for determining the primary (amino acid) sequence of proteins by Frederick Sanger in 1955, Zuckerkandl and Pauling postulated that such sequences could be used to infer not only the phylogeny relating the observed protein sequences, but also the ancestral protein sequence at the earliest point (root) of this tree. However, the idea of reconstructing ancestors from measurable biological characteristics had already been developing in the field of cladistics, one of the precursors of modern phylogenetics. Cladistic methods, which appeared as early as 1901, infer the evolutionary relationships of species on the basis of the distribution of shared characteristics, of which some are inferred to be descended from common ancestors. Furthermore, Theodoseus Dobzhansky and Alfred Sturtevant articulated the principles of ancestral reconstruction in a phylogenetic context in 1938, when inferring the evolutionary history of chromosomal inversions in Drosophila pseudoobscura.
Thus, ancestral reconstruction has its roots in several disciplines. Today, computational methods for ancestral reconstruction continue to be extended and applied in a diversity of settings, so that ancestral states are being inferred not only for biological characteristics and the molecular sequences, but also for the structure or catalytic properties of ancient versus modern proteins, the geographic location of populations and species (phylogeography) and the higher-order structure of genomes. One of the most prominent examples is tracing the evolution that took place from ape to man.
Methods and algorithms
Any attempt at ancestral reconstruction begins with a phylogeny. In general, a phylogeny is a tree-based hypothesis about the order in which populations (referred to as taxa) are related by descent from common ancestors. Observed taxa are represented by the tips or terminal nodes of the tree that are progressively connected by branches to their common ancestors, which are represented by the branching points of the tree that are usually referred to as the ancestral or internal nodes. Eventually, all lineages converge to the most recent common ancestor of the entire sample of taxa. In the context of ancestral reconstruction, a phylogeny is often treated as though it were a known quantity (with Bayesian approaches being an important exception). Because there can be an enormous number of phylogenies that are nearly equally effective at explaining the data, reducing the subset of phylogenies supported by the data to a single representative, or point estimate, can be a convenient and sometimes necessary simplifying assumption.
Ancestral reconstruction can be thought of as the direct result of applying a hypothetical model of evolution to a given phylogeny. When the model contains one or more free parameters, the overall objective is to estimate these parameters on the basis of measured characteristics among the observed taxa (sequences) that descended from common ancestors. Parsimony is an important exception to this paradigm: though it has been shown that there are mathematical models for which it is the maximum likelihood estimator, at its core, it is simply based on the heuristic that changes in character state are rare, without attempting to quantify that rarity.
There are three different classes of method for ancestral reconstruction. In chronological order of discovery, these are maximum parsimony, maximum likelihood, and Bayesian Inference. Maximum parsimony considers all evolutionary events equally likely; maximum likelihood accounts for the differing likelihood of certain classes of event; and Bayeisan inference relates the conditional probability of an event to the likelihood of the tree, as well as the amount of uncertainty that is associated with that tree. Maximum parsimony and maximum likelihood yield a single most probable outcome, whereas Bayesian inference accounts for uncertainties in the data and yields a sample of possible trees.
Maximum parsimony
Parsimony, known colloquially as "Occam's razor", refers to the principle of selecting the simplest of competing hypotheses. In the context of ancestral reconstruction, parsimony endeavours to find the distribution of ancestral states within a given tree which minimizes the total number of character state changes that would be necessary to explain the states observed at the tips of the tree. This method of maximum parsimony is one of the earliest formalized algorithms for reconstructing ancestral states, as well as one of the simplest.
Maximum parsimony can be implemented by one of several algorithms. One of the earliest examples is Fitch's method, which assigns ancestral character states by parsimony via two traversals of a rooted binary tree. The first stage is a post-order traversal that proceeds from the tips toward the root of a tree by visiting descendant (child) nodes before their parents. Initially, we are determining the set of possible character states Si for the i-th ancestor based on the observed character states of its descendants. Each assignment is the set intersection of the character states of the ancestor's descendants; if the intersection is the empty set, then it is the set union. In the latter case, it is implied that a character state change has occurred between the ancestor and one of its two immediate descendants. Each such event counts towards the algorithm's cost function, which may be used to discriminate among alternative trees on the basis of maximum parsimony. Next, a pre-order traversal of the tree is performed, proceeding from the root towards the tips. Character states are then assigned to each descendant based on which character states it shares with its parent. Since the root has no parent node, one may be required to select a character state arbitrarily, specifically when more than one possible state has been reconstructed at the root.
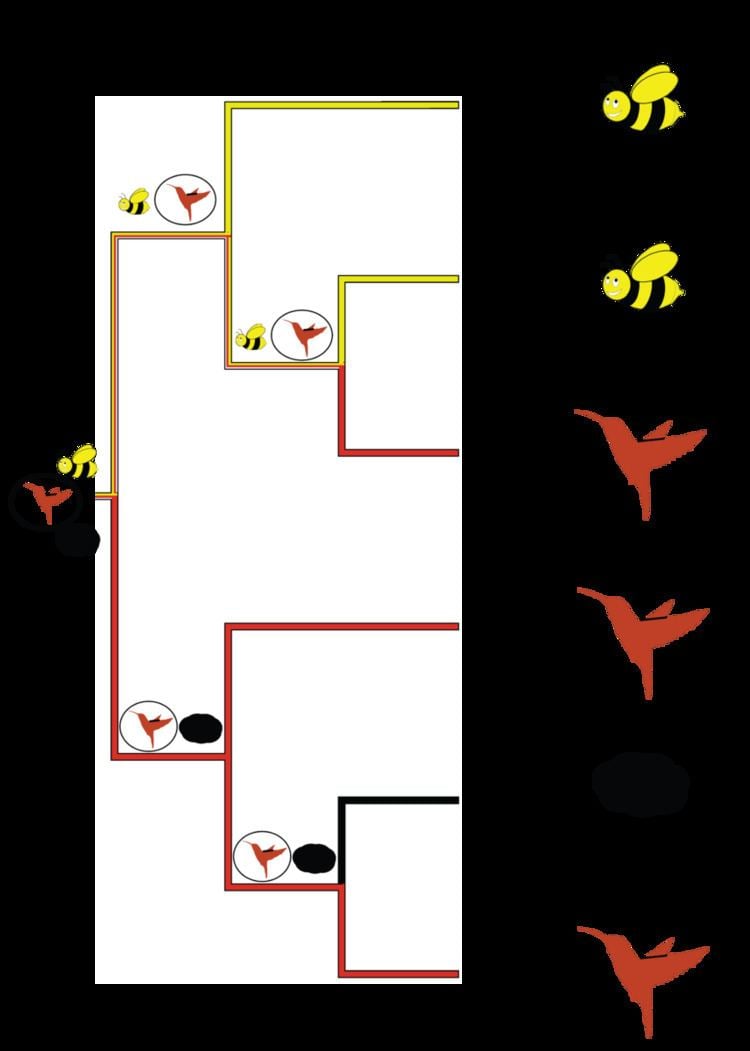
For example, consider a phylogeny recovered for a genus of plants containing 6 species A - F (Figure 1), where each plant is pollinated by either a "bee", "hummingbird" or "wind". One obvious question is what the pollinators at deeper nodes were in the phylogeny of this genus of plants. Under maximum parsimony, an ancestral state reconstruction for this clade reveals that "hummingbird" is the most parsimonious ancestral state for the lower clade (plants D, E, F), that the ancestral states for the nodes in the top clade (plants A, B, C) are equivocal and that both "hummingbird" or "bee" pollinators are equally plausible for the pollination state at the root of the phylogeny. Supposing we have strong evidence from the fossil record that the root state is "hummingbird". Resolution of the root to "hummingbird" would yield the pattern of ancestral state reconstruction depicted by the symbols at the nodes (Figure 1) with the state requiring the fewest number of changes circled.
Parsimony methods are intuitively appealing and highly efficient, such that they are still used in some cases to seed maximum likelihood optimization algorithms with an initial phylogeny. However, the underlying assumption that evolution attained a certain end result as fast as possible is inaccurate. Natural selection and evolution do not work towards a goal, they simply select for or against randomly occurring genetic changes. Parsimony methods impose six general assumptions: that the phylogenetic tree you are using is correct, that you have all of the relevant data, in which no mistakes were made in coding, that all branches of the phylogenetic tree are equally likely to change, that the rate of evolution is slow, and that the chance of losing or gaining a characteristic is the same. In reality, assumptions are often violated, leading to several issues:
- Variation in rates of evolution. Fitch's method assumes that changes between all character states are equally likely to occur; thus, any change incurs the same cost for a given tree. This assumption is often unrealistic and can limit the accuracy of such methods. For example, transitions tend to occur more often than transversions in the evolution of nucleic acids. This assumption can be relaxed by assigning differential costs to specific character state changes, resulting in a weighted parsimony algorithm.
- Rapid evolution. The upshot of the "minimum evolution" heuristic underlying such methods is that such methods assume that changes are rare, and thus are inappropriate in cases where change is the norm rather than the exception.
- Variation in time among lineages. Parsimony methods implicitly assume that the same amount of evolutionary time has passed along every branch of the tree. Thus, they do not account for variation in branch lengths in the tree, which are often used to quantify the passage of evolutionary or chronological time. This limitation makes the technique liable to infer that one change occurred on a very short branch rather than multiple changes occurring on a very long branch, for example. In addition, it is possible that some branches of the tree could be experiencing higher selection and change rates than others, perhaps due to changing environmental factors. Some periods of time may represent more rapid evolution than others, when this happens parsimony becomes inaccurate. This shortcoming is addressed by model-based methods (both maximum likelihood and Bayesian methods) that infer the stochastic process of evolution as it unfolds along each branch of a tree.
- Statistical justification. Without a statistical model underlying the method, its estimates do not have well-defined uncertainties.
- Convergent evolution. When considering a single character state, parsimony will automatically assume that two organisms that share that characteristic will be more closely related than those who don’t. For example, just because dogs and apes have fur does not mean that they are more closely related than apes are to humans.
Maximum likelihood
Maximum likelihood (ML) methods of ancestral state reconstruction treat the character states at internal nodes of the tree as parameters, and attempt to find the parameter values that maximize the probability of the data (the observed character states) given the hypothesis (a model of evolution and a phylogeny relating the observed sequences or taxa). In other words, this method assumes that the ancestral states are those which are statistically most likely, given the observed phenotypes. Some of the earliest ML approaches to ancestral reconstruction were developed in the context of genetic sequence evolution; similar models were also developed for the analogous case of discrete character evolution.
The use of a model of evolution accounts for the fact that not all events are equally likely to happen. For example, a transition, which is a type of point mutation from one purine to another, or from one pyrimidine to another is much more likely to happen than a transversion, which is the chance of a purine being switched to a pyrimidine, or vice versa. These differences are not captured by maximum parsimony. However, just because some events are more likely than others does not mean that they always happen. We know that throughout evolutionary history there have been times when there was a large gap between what was most likely to happen, and what actually occurred. When this is the case, maximum parsimony may actually be more accurate because it is more willing to make large, unlikely leaps than maximum likelihood is. Maximum likelihood has been shown to be quite reliable in reconstructing character states, but it does not do as good of a job at giving accurate estimations of the stability of proteins. Maximum likelihood always overestimates the stability of proteins, which makes sense since it assumes that the proteins that were made and used were the most stable and optimal. The merits of maximum likelihood have been subject to debate, with some having concluded that maximum likelihood test represents a good medium between accuracy and speed. However, other studies have complained that maximum likelihood takes too much time and computational power to be useful in some scenarios.
These approaches employ the same probabilistic framework as used to infer the phylogenetic tree. In brief, the evolution of a genetic sequence is modelled by a time-reversible continuous time Markov process. In the simplest of these, all characters undergo independent state transitions (such as nucleotide substitutions) at a constant rate over time. This basic model is frequently extended to allow different rates on each branch of the tree. In reality, mutation rates may also vary over time (due, for example, to environmental changes); this can be modelled by allowing the rate parameters to evolve along the tree, at the expense of having an increased number of parameters. A model defines transition probabilities from states i to j along a branch of length t (in units of evolutionary time). The likelihood of a phylogeny is computed from a nested sum of transition probabilities that corresponds to the hierarchical structure of the proposed tree. At each node, the likelihood of its descendants is summed over all possible ancestral character states at that node:
where we are computing the likelihood of the subtree rooted at node x with direct descendants y and z,
Marginal and joint likelihood
Rather than compute the overall likelihood for alternative trees, the problem for ancestral reconstruction is to find the combination of character states at each ancestral node with the highest marginal maximum likelihood. Generally speaking, there are two approaches to this problem. First, one may work upwards from the descendants of a tree to progressively assign the most likely character state to each ancestor taking into consideration only its immediate descendants. This approach is referred to as marginal reconstruction. It is akin to a greedy algorithm that makes the locally optimal choice at each stage of the optimization problem. While it can be highly efficient, it is not guaranteed to attain a globally optimal solution to the problem. Second, one may instead attempt to find the joint combination of ancestral character states throughout the tree which jointly maximizes the likelihood of the data. Thus, this approach is referred to as joint reconstruction. While it is not as rapid as marginal reconstruction, it is also less likely to be caught in the local optima in non-convex objective functions that modern optimization methods and heuristics are designed to avoid. In the context of ancestral reconstruction, this means that a marginal reconstruction may assign a character state to the immediate ancestor that is locally optimal, but deflects the joint distribution of ancestral character states away from the global optimum (for examples, see Pupko and colleagues). Not surprisingly, joint reconstruction is more computationally complex than marginal reconstruction. Nevertheless, efficient algorithms for joint reconstruction have been developed with a time complexity that is generally linear with the number of observed taxa or sequences.
ML-based methods of ancestral reconstruction tend to provide greater accuracy than MP methods in the presence of variation in rates of evolution among characters (or across sites in a genome). However, these methods are not yet able to accommodate variation in rates of evolution over time, otherwise known as heterotachy. If the rate of evolution for a specific character accelerates on a branch of the phylogeny, then the amount of evolution that has occurred on that branch will be underestimated for a given length of the branch and assuming a constant rate of evolution for that character. In addition to that, it is difficult to distinguish heterotachy from variation among characters in rates of evolution.
Since ML (unlike maximum parsimony) requires the investigator to specify a model of evolution, its accuracy may be affected by the use of a grossly incorrect model (model misspecification). Furthermore, ML can only provide a single reconstruction of character states (what is often referred to as a "point estimate") — when the likelihood surface is highly non-convex, comprising multiple peaks (local optima), then a single point estimate cannot provide an adequate representation, and a Bayesian approach may be more suitable.
Bayesian inference
Bayesian inference uses the likelihood of observed data to update the investigator's belief, or prior distribution, to yield the posterior distribution. In the context of ancestral reconstruction, the objective is to infer the posterior probabilities of ancestral character states at each internal node of a given tree. Moreover, one can integrate these probabilities over the posterior distributions over the parameters of the evolutionary model and the space of all possible trees. This can be expressed as an application of Bayes' theorem:
where S represents the ancestral states, D corresponds to the observed data, and
Bayesian inference is the method that many have argued is the most accurate. In general, Bayesian statistical methods allow investigators to combine pre-existing information with new hypothesis. In the case of evolution, it combines the likelihood of the data observed with the likelihood that the events happened in the order they did, while recognizing the potential for error and uncertainty. Overall, it is the most accurate method for reconstructing ancestral genetic sequences, as well as protein stability. Unlike the other two methods, Bayesian inference yields a distribution of possible trees, allowing for more accurate and easily interpretable estimates of the variance of possible outcomes.
We have given two formulations above to emphasize the two different applications of Bayes' theorem, which we discuss in the following section.
Empirical and hierarchical Bayes
One of the first implementations of a Bayesian approach to ancestral sequence reconstruction was developed by Yang and colleagues, where the maximum likelihood estimates of the evolutionary model and tree, respectively, were used to define the prior distributions. Thus, their approach is an example of an empirical Bayes method to compute the posterior probabilities of ancestral character states; this method was first implemented in the software package PAML. In terms of the above Bayesian rule formulation, the empirical Bayes method fixes
Empirical Bayes methods for ancestral reconstruction require the investigator to assume that the evolutionary model parameters and tree are known without error. When the size or complexity of the data makes this an unrealistic assumption, it may be more prudent to adopt the fully hierarchical Bayesian approach and infer the joint posterior distribution over the ancestral character states, model, and tree. Huelsenbeck and Bollback first proposed a hierarchical Bayes method to ancestral reconstruction by using Markov chain Monte Carlo (MCMC) methods to sample ancestral sequences from this joint posterior distribution. A similar approach was also used to reconstruct the evolution of symbiosis with algae in fungal species (lichenization). For example, the Metropolis-Hastings algorithm for MCMC explores the joint posterior distribution by accepting or rejecting parameter assignments on the basis of the ratio of posterior probabilities.
Put simply, the empirical Bayes approach calculates the probabilities of various ancestral states for a specific tree and model of evolution. By expressing the reconstruction of ancestral states as a set of probabilities, one can directly quantify the uncertainty for assigning any particular state to an ancestor. On the other hand, the hierarchical Bayes approach averages these probabilities over all possible trees and models of evolution, in proportion to how likely these trees and models are, given the data that has been observed.
Whether the hierarchical Bayes method confers a substantial advantage in practice remains controversial, however. Moreover, this fully Bayesian approach is limited to analyzing relatively small numbers of sequences or taxa because the space of all possible trees rapidly becomes too vast, making it computationally infeasible for chain samples to converge in a reasonable amount of time.
Calibration
Ancestral reconstruction can be informed by the observed states in historical samples of known age, such as fossils or archival specimens. Since the accuracy of ancestral reconstruction generally decays with increasing time, the use of such specimens provides data that are closer to the ancestors being reconstructed and will most likely improve the analysis, especially when rates of character change vary through time. This concept has been validated by an experimental evolutionary study in which replicate populations of bacteriophage T7 were propagated to generate an artificial phylogeny. In revisiting these experimental data, Oakley and Cunningham found that maximum parsimony methods were unable to accurately reconstruct the known ancestral state of a continuous character (plaque size); these results were verified by computer simulation. This failure of ancestral reconstruction was attributed to a directional bias in the evolution of plaque size (from large to small plaque diameters) that required the inclusion of "fossilized" samples to address.
Studies of both mammalian carnivores and fishes have demonstrated that without incorporating fossil data, the reconstructed estimates of ancestral body sizes are unrealistically large. Moreover, Graham Slater and colleagues showed using caniform carnivorans that incorporating fossil data into prior distributions improved both the Bayesian inference of ancestral states and evolutionary model selection, relative to analyses using only contemporaneous data.
Models
Many models have been developed to estimate ancestral states of discrete and continuous characters from extant descendants. Such models assume that the evolution of a trait through time may be modelled as a stochastic process. For discrete-valued traits (such as "pollinator type"), this process is typically taken to be a Markov chain; for continuous-valued traits (such as "brain size"), the process is frequently taken to be a Brownian motion or an Ornstein-Uhlenbeck process. Using this model as the basis for statistical inference, one can now use maximum likelihood methods or Bayesian inference to estimate the ancestral states.
Discrete-state models
Suppose the trait in question may fall into one of
In order to recover the state of a given ancestral node in the phylogeny (call this node
Because such models may have as many as
Example: Binary state speciation and extinction model
The binary state speciation and extinction model (BiSSE) is a discrete-space model that does not directly follow the framework of those mentioned above. It allows estimation of ancestral binary character states jointly with diversification rates associated with different character states; it may also be straightforwardly extended to a more general multiple-discrete-state model. In its most basic form, this model involves six parameters: two speciation rates (one each for lineages in states 0 and 1); similarly, two extinction rates; and two rates of character change. This model allows for hypothesis testing on the rates of speciation/extinction/character change, at the cost of increasing the number of parameters.
Continuous-state models
In the case where the trait instead takes non-discrete values, one must instead turn to a model where the trait evolves as some continuous process. Inference of ancestral states by maximum likelihood (or by Bayesian methods) would proceed as above, but with the likelihoods of transitions in state between adjacent nodes given by some other continuous probability distribution.
Character evolution
Ancestral reconstruction is widely used to infer the ecological, phenotypic, or biogeographic traits associated with ancestral nodes in a phylogenetic tree. It should be noted that all methods of ancestral trait reconstructions have pitfalls, as they use mathematical models to predict how traits have changed with large amounts of missing data. This missing data includes the states of extinct species, the relative rates of evolutionary changes, knowledge of initial character states, and the accuracy of phylogenetic trees. In all cases where ancestral trait reconstruction is used, findings should be justified with an examination of the biological data that supports model based conclusions. Griffith O.W. et al.
Ancestral reconstruction allows for the study of evolutionary pathways, adaptive selection, and functional divergence of the evolutionary past. For a review of biological and computational techniques of ancestral reconstruction see Chang et al.. For criticism of ancestral reconstruction computation methods see Williams P.D. et al..
Behavior and life history evolution
In horned lizards (genus Phrynosoma), viviparity (live birth) has evolved multiple times, based on ancestral reconstruction methods.
Diet reconstruction in Galapagos finches
Both phylogenetic and character data are available for the radiation of finches inhabiting the Galapagos Islands. These data allow testing of hypotheses concerning the timing and ordering of character state changes through time via ancestral state reconstruction. During the dry season, the diets of the 13 species of Galapagos finches may be assorted into three broad diet categories, first those that consume grain-like foods are considered "granivores", those that ingest arthropods are termed "insectivores" and those that consume vegetation are classified as "folivores". Dietary ancestral state reconstruction using maximum parsimony recover 2 major shifts from an insectivorous state: one to granivory, and one to folivory. Maximum-likelihood ancestral state reconstruction recovers broadly similar results, with one significant difference: the common ancestor of the tree finch (Camarhynchus) and ground finch (Geospiza) clades are most likely granivorous rather than insectivorous (as judged by parsimony). In this case, this difference between ancestral states returned by maximum parsimony and maximum likelihood likely occurs as a result of the fact that ML estimates consider branch lengths of the phylogenetic tree.
Morphological and physiological character evolution
Phrynosomatid lizards show remarkable morphological diversity, including in the relative muscle fiber type composition in their hindlimb muscles. Ancestor reconstruction based on squared-change parsimony (equivalent to maximum likelihood under Brownian motion character evolution) indicates that horned lizards, one of the three main subclades of the lineage, have undergone a major evolutionary increase in the proportion of fast-oxidative glycolytic fibers in their iliofibularis muscles.
Mammalian body mass
In an analysis of the body mass of 1,679 placental mammal species comparing stable models of continuous character evolution to Brownian motion models, Elliot and Mooers showed that the evolutionary process describing mammalian body mass evolution is best characterized by a stable model of continuous character evolution, which accommodates rare changes of large magnitude. Under a stable model, ancestral mammals retained a low body mass through early diversification, with large increases in body mass coincident with the origin of several Orders of large body massed species (e.g. ungulates). By contrast, simulation under a Brownian motion model recovered a less realistic, order of magnitude larger body mass among ancestral mammals, requiring significant reductions in body size prior to the evolution of Orders exhibiting small body size (e.g. Rodentia). Thus stable models recover a more realistic picture of mammalian body mass evolution by permitting large transformations to occur on a small subset of branches.
Phylogenetic comparative methods (inferences drawn through comparison of related taxa) are often used to identify biological characteristics that do not evolve independently, which can reveal an underlying dependence. For example, the evolution of the shape of a finch's beak may be associated with its foraging behaviour. However, it is not advisable to search for these associations by the direct comparison of measurements or genetic sequences because these observations are not independent because of their descent from common ancestors. For discrete characters, this problem was first addressed in the framework of maximum parsimony by evaluating whether two characters tended to undergo a change on the same branches of the tree. Felsenstein identified this problem for continuous character evolution and proposed a solution similar to ancestral reconstruction, in which the phylogenetic structure of the data was accommodated statistically by directing the analysis through computation of "independent contrasts" between nodes of the tree related by non-overlapping branches.
Molecular evolution
On a molecular level, amino acid residues at different locations of a protein may evolve non-independently because they have a direct physicochemical interaction, or indirectly by their interactions with a common substrate or through long-range interactions in the protein structure. Conversely, the folded structure of a protein could potentially be inferred from the distribution of residue interactions. One of the earliest applications of ancestral reconstruction, to predict the three-dimensional structure of a protein through residue contacts, was published by Shindyalov and colleagues. Phylogenies relating 67 different protein families were generated by a distance-based clustering method (unweighted pair group method with arithmetic mean, UPGMA), and ancestral sequences were reconstructed by parsimony. The authors reported a weak but significant tendency for co-evolving pairs of residues to be co-located in the known three-dimensional structure of the proteins.
The reconstruction of ancient proteins and DNA sequences has only recently become a significant scientific endeavour. The developments of extensive genomic sequence databases in conjunction with advances in biotechnology and phylogenetic inference methods have made ancestral reconstruction cheap, fast, and scientifically practical. This concept has been applied to identify co-evolving residues in protein sequences using more advanced methods for the reconstruction of phylogenies and ancestral sequences. For example, ancestral reconstruction has been used to identify co-evolving residues in proteins encoded by RNA virus genomes, particularly in HIV.
Ancestral protein and DNA reconstruction allows for the recreation of protein and DNA evolution in the laboratory so that it can be studied directly. With respect to proteins, this allows for the investigation of the evolution of present-day molecular structure and function. Additionally, ancestral protein reconstruction can lead to the discoveries of new biochemical functions that have been lost in modern proteins. It also allows insights into the biology and ecology of extinct organisms. Although the majority of ancestral reconstructions have dealt with proteins, it has also been used to test evolutionary mechanisms at the level of bacterial genomes and primate gene sequences.
Vaccine design
RNA viruses such as the human immunodeficiency virus (HIV) evolve at an extremely rapid rate, orders of magnitude faster than mammals or birds. For these organisms, ancestral reconstruction can be applied on a much shorter time scale; for example, in order to reconstruct the global or regional progenitor of an epidemic that has spanned decades rather than millions of years. A team around Brian Gaschen proposed that such reconstructed strains be used as targets for vaccine design efforts, as opposed to sequences isolated from patients in the present day. Because HIV is extremely diverse, a vaccine designed to work on one patient's viral population might not work for a different patient, because the evolutionary distance between these two viruses may be large. However, their most recent common ancestor is closer to each of the two viruses than they are to each other. Thus, a vaccine designed for a common ancestor could have a better chance of being effective for a larger proportion of circulating strains. Another team took this idea further by developing a center-of-tree reconstruction method to produce a sequence whose total evolutionary distance to contemporary strains is as small as possible. Strictly speaking, this method was not ancestral reconstruction, as the center-of-tree (COT) sequence does not necessarily represent a sequence that has ever existed in the evolutionary history of the virus. However, Rolland and colleagues did find that, in the case of HIV, the COT virus was functional when synthesized. Similar experiments with synthetic ancestral sequences obtained by maximum likelihood reconstruction have likewise shown that these ancestors are both functional and immunogenic, lending some credibility to these methods. Furthermore, ancestral reconstruction can potentially be used to infer the genetic sequence of the transmitted HIV variants that have gone on to establish the next infection, with the objective of identifying distinguishing characteristics of these variants (as a non-random selection of the transmitted population of viruses) that may be targeted for vaccine design.
Genome rearrangements
Rather than inferring the ancestral DNA sequence, one may be interested in the larger-scale molecular structure and content of an ancestral genome. This problem is often approached in a combinatorial framework, by modelling genomes as permutations of genes or homologous regions. Various operations are allowed on these permutations, such as an inversion (a segment of the permutation is reversed in-place), deletion (a segment is removed), transposition (a segment is removed from one part of the permutation and spliced in somewhere else), or gain of genetic content through recombination, duplication or horizontal gene transfer. The "genome rearrangement problem", first posed by Watterson and colleagues, asks: given two genomes (permutations) and a set of allowable operations, what is the shortest sequence of operations that will transform one genome into the other? A generalization of this problem applicable to ancestral reconstruction is the "multiple genome rearrangement problem": given a set of genomes and a set of allowable operations, find (i) a binary tree with the given genomes as its leaves, and (ii) an assignment of genomes to the internal nodes of the tree, such that the total number of operations across the whole tree is minimized. This approach is similar to parsimony, except that the tree is inferred along with the ancestral sequences. Unfortunately, even the single genome rearrangement problem is NP-hard, although it has received much attention in mathematics and computer science (for a review, see Fertin and colleagues).
The reconstruction of ancestral genomes is also called karyotype reconstruction. Chromosome painting is currently the main experimental technique. Recently, researchers have developed computational methods to reconstruct the ancestral karyotype by taking advantage of comparative genomics. Furthermore, comparative genomics and ancestral genome reconstruction has been applied to identify ancient horizontal gene transfer events at the last common ancestor of a lineage (e.g. Candidatus Accumulibacter phosphatis) to identify the evolutionary basis for trait acquisition.
Spatial applications
Migration
Ancestral reconstruction is not limited to biological traits. Spatial location is also a trait, and ancestral reconstruction methods can infer the locations of ancestors of the individuals under consideration. Such techniques were used by Lemey and colleagues to geographically trace the ancestors of 192 Avian influenza A-H5N1 strains sampled from twenty localities in Europe and Asia, and for 101 rabies virus sequences sampled across twelve African countries.
Treating locations as discrete states (countries, cities, etc.) allows for the application of the discrete-state models described above. However, unlike in a model where the state space for the trait is small, there may be many locations, and transitions between certain pairs of states may rarely or never occur; for example, migration between distant locales may never happen directly if air travel between the two places does not exist, so such migrations must pass through intermediate locales first. This means that there could be many parameters in the model which are zero or close to zero. To this end, Lemey and colleagues used a Bayesian procedure to not only estimate the parameters and ancestral states, but also to select which migration parameters are not zero; their work suggests that this procedure does lead to more efficient use of the data. They also explore the use of prior distributions that incorporate geographical structure or hypotheses about migration dynamics, finding that those they considered had little effect on the findings.
Using this analysis, the team around Lemey found that the most likely hub of diffusion of A-H5N1 is Guangdong, with Hong Kong also receiving posterior support. Further, their results support the hypothesis of long-standing presence of African rabies in West Africa.
Species ranges
Inferring historical biogeographic patterns often requires reconstructing ancestral ranges of species on phylogenetic trees. For instance, a well-resolved phylogeny of plant species in the genus Cyrtandra was used together with information of their geographic ranges to compare four methods of ancestral range reconstruction. The team compared Fitch parsimony, (FP; parsimony) stochastic mapping (SM; maximum likelihood), dispersal-vicariance analysis (DIVA; parsimony), and dispersal-extinction-cladogenesis (DEC; maximum-likelihood). Results indicated that both parsimony methods performed poorly, which was likely due to the fact that parsimony methods do not consider branch lengths. Both maximum-likelihood methods performed better; however, DEC analyses that additionally allow incorporation of geological priors gave more realistic inferences about range evolution in Cyrtandra relative to other methods.
Another maximum likelihood method recovers the phylogeographic history of a gene by reconstructing the ancestral locations of the sampled taxa. This method assumes a spatially explicit random walk model of migration to reconstruct ancestral locations given the geographic coordinates of the individuals represented by the tips of the phylogenetic tree. When applied to a phylogenetic tree of chorus frogs Pseudacris feriarum, this method recovered recent northward expansion, higher per-generation dispersal distance in the recently colonized region, a non-central ancestral location, and directional migration.
The first consideration of the multiple genome rearrangement problem, long before its formalization in terms of permutations, was presented by Sturtevant and Dobzhansky in 1936. They examined genomes of several strains of fruit fly from different geographic locations, and observed that one configuration, which they called "standard", was the most common throughout all the studied areas. Remarkably, they also noticed that four different strains could be obtained from the standard sequence by a single inversion, and two others could be related by a second inversion. This allowed them to hypothesize a phylogeny for the sequences, and to infer that the standard sequence was probably also the ancestral one.
Linguistic Evolution
Reconstructions of the words and phenomes of ancient proto-languages such as Proto-Indo-European have been performed based on the observed analogues in present-day languages. Typically, these analyses are carried out manually using the "comparative method". First, words from different languages with a common etymology (cognates) are identified in the contemporary languages under study, analogous to the identification of orthologous biological sequences. Second, correspondences between individual sounds in the cognates are identified, a step similar to biological sequence alignment, although performed manually. Finally, likely ancestral sounds are hypothesised by manual inspection and various heuristics (such as the fact that most languages have both nasal and non-nasal vowels).
Software
There are many software packages available which can perform ancestral state reconstruction. Generally, these software packages have been developed and maintained through the efforts of scientists in related fields and released under free software licenses. The following table is not meant to be a comprehensive itemization of all available packages, but provides a representative sample of the extensive variety of packages that implement methods of ancestral reconstruction with different strengths and features.
Molecular evolution
The majority of these software packages are designed for analyzing genetic sequence data. For example, PAML is a collection of programs for the phylogenetic analysis of DNA and protein sequence alignments by maximum likelihood. Ancestral reconstruction can be performed using the codeml program. In addition, LAZARUS is a collection of Python scripts that wrap the ancestral reconstruction functions of PAML for batch processing and greater ease-of-use. HyPhy, Mesquite, and MEGA are also software packages for the phylogenetic analysis of sequence data, but are designed to be more modular and customizable. HyPhy implements a joint maximum likelihood method of ancestral sequence reconstruction that can be readily adapted to reconstructing a more generalized range of discrete ancestral character states such as geographic locations by specifying a customized model in its batch language. Mesquite provides ancestral state reconstruction methods for both discrete and continuous characters using both maximum parsimony and maximum likelihood methods. It also provides several visualization tools for interpreting the results of ancestral reconstruction. MEGA is a modular system, too, but places greater emphasis on ease-of-use than customization of analyses. As of version 5, MEGA allows the user to reconstruct ancestral states using maximum parsimony, maximum likelihood, and empirical Bayes methods.
The Bayesian analysis of genetic sequences may confer greater robustness to model misspecification. MrBayes allows inference of ancestral states at ancestral nodes using the full hierarchical Bayesian approach. The PREQUEL program distributed in the PHAST package performs comparative evolutionary genomics using ancestral sequence reconstruction. SIMMAP stochastically maps mutations on phylogenies. BayesTraits analyses discrete or continuous characters in a Bayesian framework to evaluate models of evolution, reconstruct ancestral states, and detect correlated evolution between pairs of traits.
Other character types
Other software packages are more oriented towards the analysis of qualitative and quantitative traits (phenotypes). For example, the ape package in the statistical computing environment R also provides methods for ancestral state reconstruction for both discrete and continuous characters through the ace function, including maximum likelihood. (Note that ace performs reconstruction by computing scaled conditional likelihoods instead of the marginal or joint likelihoods used by other maximum likelihood-based methods for ancestral reconstruction, which may adversely affect the accuracy of reconstruction at nodes other than the root [1].) Phyrex implements a maximum parsimony-based algorithm to reconstruct ancestral gene expression profiles, in addition to a maximum likelihood method for reconstructing ancestral genetic sequences (by wrapping around the baseml function in PAML).
Several software packages also reconstruct phylogeography. BEAST (Bayesian Evolutionary Analysis by Sampling Trees) provides tools for reconstructing ancestral geographic locations from observed sequences annotated with location data using Bayesian MCMC sampling methods. Diversitree is an R package providing methods for ancestral state reconstruction under Mk2 (a continuous time Markov model of binary character evolution.) and BiSSE (Binary State Speciation and Extinction) models. Lagrange performs analyses on reconstruction of geographic range evolution on phylogenetic trees. Phylomapper is a statistical framework for estimating historical patterns of gene flow and ancestral geographic locations. RASP infers ancestral states using statistical dispersal-vicariance analysis, Lagrange, Bayes-Lagrange, BayArea and BBM methods. VIP infers historical biogeography by examining disjunct geographic distributions.
Genome rearrangements provide valuable information in comparative genomics between species. ANGES compares extant related genomes through ancestral reconstruction of genetic markers. BADGER uses a Bayesian approach to examining the history of gene rearrangement. Count reconstructs the evolution of the size of gene families. EREM analyses the gain and loss of genetic features encoded by binary characters. PARANA performs parsimony based inference of ancestral biological networks that represent gene loss and duplication.
Web applications
Finally, there are several web-server based applications that allow investigators to use maximum likelihood methods for ancestral reconstruction of different character types without having to install any software. For example, Ancestors is web-server for ancestral genome reconstruction by the identification and arrangement of syntenic regions. FastML is a web-server for probabilistic reconstruction of ancestral sequences by maximum likelihood that uses a gap character model for reconstructing indel variation. MLGO is a web-server for maximum likelihood gene order analysis.
Future directions
The development and application of computational algorithms for ancestral reconstruction continues to be an active area of research across disciplines. For example, the reconstruction of sequence insertions and deletions (indels) has lagged behind the more straightforward application of substitution models. Bouchard-Côté and Jordan recently described a new model (the Poisson Indel Process) which represents an important advance on the archetypal Thorne-Kishino-Felsenstein model of indel evolution. In addition, the field is being driven forward by rapid advances in the area of next-generation sequencing technology, where sequences are generated from millions of nucleic acid templates by extensive parallelization of sequencing reactions in a custom apparatus. These advances have made it possible to generate a "deep" snapshot of the genetic composition of a rapidly evolving population, such as RNA viruses or tumour cells, in a relatively short amount of time. At the same time, the massive amount of data and platform-specific sequencing error profiles has created new bioinformatic challenges for processing these data for ancestral sequence reconstruction.