
 | ||
From sound synthesis to sound retrieval and back
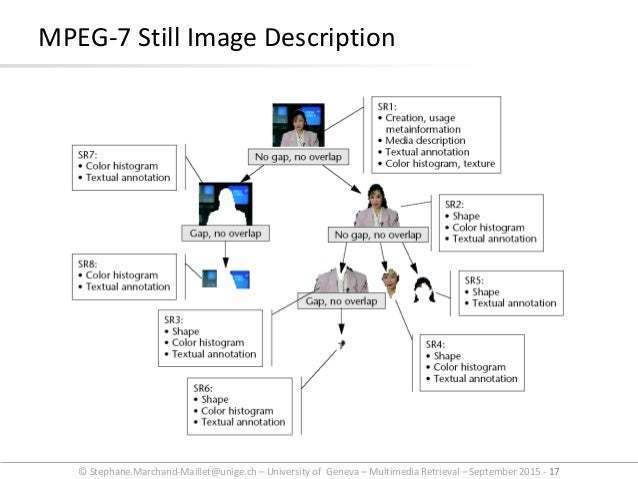
Multimedia information retrieval (MMIR or MIR) is a research discipline of computer science that aims at extracting semantic information from multimedia data sources. Data sources include directly perceivable media such as audio, image and video, indirectly perceivable sources such as text, biosignals as well as not perceivable sources such as bioinformation, stock prices, etc. The methodology of MMIR can be organized in three groups:
Contents
- From sound synthesis to sound retrieval and back
- Final year projects 2015 multimedia information retrieval based
- Feature extraction methods
- Merging and filtering methods
- Categorization methods
- Open problems
- Related areas
- References
- Methods for the summarization of media content (feature extraction). The result of feature extraction is a description.
- Methods for the filtering of media descriptions (for example, elimination of redundancy)
- Methods for the categorization of media descriptions into classes.
Final year projects 2015 multimedia information retrieval based
Feature extraction methods
Feature extraction is motivated by the sheer size of multimedia objects as well as their redundancy and, possibly, noisiness. Generally, two possible goals can be achieved by feature extraction:
Merging and filtering methods
Multimedia Information Retrieval implies that multiple channels are employed for the understanding of media content. Each of this channels is described by media-specific feature transformations. The resulting descriptions have to be merged to one description per media object. Merging can be performed by simple concatenation if the descriptions are of fixed size. Variable-sized descriptions – as they frequently occur in motion description – have to be normalized to a fixed length first.
Frequently used methods for description filtering include factor analysis (e.g. by PCA), singular value decomposition (e.g. as latent semantic indexing in text retrieval) and the extraction and testing of statistical moments. Advanced concepts such as the Kalman filter are used for merging of descriptions.
Categorization methods
Generally, all forms of machine learning can be employed for the categorization of multimedia descriptions though some methods are more frequently used in one area than another. For example, hidden Markov models are state-of-the-art in speech recognition, while dynamic time warping – a semantically related method – is state-of-the-art in gene sequence alignment. The list of applicable classifiers includes the following:
The selection of the best classifier for a given problem (test set with descriptions and class labels, so-called ground truth) can be performed automatically, for example, using the Weka Data Miner.
Open problems
The quality of MMIR Systems depends heavily on the quality of the training data. Discriminative descriptions can be extracted from media sources in various forms. Machine learning provides categorization methods for all types of data. However, the classifier can only be as good as the given training data. On the other hand, it requires considerable effort to provide class labels for large databases. The future success of MMIR will depend on the provision of such data. The annual TRECVID competition is currently one of the most relevant sources of high-quality ground truth.
Related areas
MMIR provides an overview over methods employed in the areas of information retrieval. Methods of one area are adapted and employed on other types of media. Multimedia content is merged before the classification is performed. MMIR methods are, therefore, usually reused from other areas such as:
The Journal of Multimedia Information Retrieval documents the development of MMIR as a research discipline that is independent of these areas. See also Handbook of Multimedia Information Retrieval for a complete overview over this research discipline.