An information retrieval process begins when a user enters a query into the system. Queries are formal statements of information needs, for example search strings in web search engines. In information retrieval a query does not uniquely identify a single object in the collection. Instead, several objects may match the query, perhaps with different degrees of relevancy.
An object is an entity that is represented by information in a content collection or database. User queries are matched against the database information. However, as opposed to classical SQL queries of a database, in information retrieval the results returned may or may not match the query, so results are typically ranked. This ranking of results is a key difference of information retrieval searching compared to database searching.
Depending on the application the data objects may be, for example, text documents, images, audio, mind maps or videos. Often the documents themselves are not kept or stored directly in the IR system, but are instead represented in the system by document surrogates or metadata.
Most IR systems compute a numeric score on how well each object in the database matches the query, and rank the objects according to this value. The top ranking objects are then shown to the user. The process may then be iterated if the user wishes to refine the query.
The idea of using computers to search for relevant pieces of information was popularized in the article As We May Think by Vannevar Bush in 1945. It would appear that Bush was inspired by patents for a 'statistical machine' - filed by Emanuel Goldberg in the 1920s and '30s - that searched for documents stored on film. The first description of a computer searching for information was described by Holmstrom in 1948, detailing an early mention of the Univac computer. Automated information retrieval systems were introduced in the 1950s: one even featured in the 1957 romantic comedy, Desk Set. In the 1960s, the first large information retrieval research group was formed by Gerard Salton at Cornell. By the 1970s several different retrieval techniques had been shown to perform well on small text corpora such as the Cranfield collection (several thousand documents). Large-scale retrieval systems, such as the Lockheed Dialog system, came into use early in the 1970s.
In 1992, the US Department of Defense along with the National Institute of Standards and Technology (NIST), cosponsored the Text Retrieval Conference (TREC) as part of the TIPSTER text program. The aim of this was to look into the information retrieval community by supplying the infrastructure that was needed for evaluation of text retrieval methodologies on a very large text collection. This catalyzed research on methods that scale to huge corpora. The introduction of web search engines has boosted the need for very large scale retrieval systems even further.
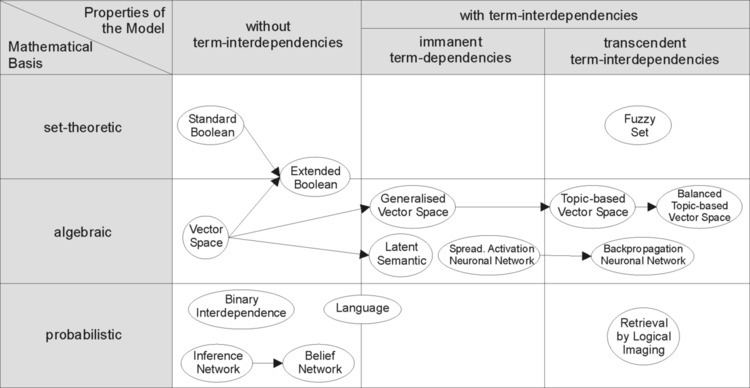
For effectively retrieving relevant documents by IR strategies, the documents are typically transformed into a suitable representation. Each retrieval strategy incorporates a specific model for its document representation purposes. The picture on the right illustrates the relationship of some common models. In the picture, the models are categorized according to two dimensions: the mathematical basis and the properties of the model.
Set-theoretic models represent documents as sets of words or phrases. Similarities are usually derived from set-theoretic operations on those sets. Common models are:Standard Boolean modelExtended Boolean modelFuzzy retrievalAlgebraic models represent documents and queries usually as vectors, matrices, or tuples. The similarity of the query vector and document vector is represented as a scalar value.Vector space modelGeneralized vector space model(Enhanced) Topic-based Vector Space ModelExtended Boolean modelLatent semantic indexing a.k.a. latent semantic analysisProbabilistic models treat the process of document retrieval as a probabilistic inference. Similarities are computed as probabilities that a document is relevant for a given query. Probabilistic theorems like the Bayes' theorem are often used in these models.Binary Independence ModelProbabilistic relevance model on which is based the okapi (BM25) relevance functionUncertain inferenceLanguage modelsDivergence-from-randomness modelLatent Dirichlet allocationFeature-based retrieval models view documents as vectors of values of feature functions (or just features) and seek the best way to combine these features into a single relevance score, typically by learning to rank methods. Feature functions are arbitrary functions of document and query, and as such can easily incorporate almost any other retrieval model as just another feature.Models without term-interdependencies treat different terms/words as independent. This fact is usually represented in vector space models by the orthogonality assumption of term vectors or in probabilistic models by an independency assumption for term variables.Models with immanent term interdependencies allow a representation of interdependencies between terms. However the degree of the interdependency between two terms is defined by the model itself. It is usually directly or indirectly derived (e.g. by dimensional reduction) from the co-occurrence of those terms in the whole set of documents.Models with transcendent term interdependencies allow a representation of interdependencies between terms, but they do not allege how the interdependency between two terms is defined. They rely an external source for the degree of interdependency between two terms. (For example, a human or sophisticated algorithms.)The evaluation of an information retrieval system is the process of assessing how well a system meets the information needs of its users. Traditional evaluation metrics, designed for Boolean retrieval or top-k retrieval, include precision and recall. Many more measures for evaluating the performance of information retrieval systems have also been proposed. In general, measurement considers a collection of documents to be searched and a search query. All common measures described here assume a ground truth notion of relevancy: every document is known to be either relevant or non-relevant to a particular query. In practice, queries may be ill-posed and there may be different shades of relevancy.
Virtually all modern evaluation metrics (e.g., mean average precision, discounted cumulative gain) are designed for ranked retrieval without any explicit rank cutoff, taking into account the relative order of the documents retrieved by the search engines and giving more weight to documents returned at higher ranks.
The mathematical symbols used in the formulas below mean:
X ∩ Y - Intersection - in this case, specifying the documents in both sets X and Y | X | - Cardinality - in this case, the number of documents in set X ∫ - Integral ∑ - Summation Δ - Symmetric differencePrecision is the fraction of the documents retrieved that are relevant to the user's information need.
precision = | { relevant documents } ∩ { retrieved documents } | | { retrieved documents } | In binary classification, precision is analogous to positive predictive value. Precision takes all retrieved documents into account. It can also be evaluated at a given cut-off rank, considering only the topmost results returned by the system. This measure is called precision at n or P@n.
Note that the meaning and usage of "precision" in the field of information retrieval differs from the definition of accuracy and precision within other branches of science and statistics.
Recall is the fraction of the documents that are relevant to the query that are successfully retrieved.
recall = | { relevant documents } ∩ { retrieved documents } | | { relevant documents } | In binary classification, recall is often called sensitivity. So it can be looked at as the probability that a relevant document is retrieved by the query.
It is trivial to achieve recall of 100% by returning all documents in response to any query. Therefore, recall alone is not enough but one needs to measure the number of non-relevant documents also, for example by computing the precision.
The proportion of non-relevant documents that are retrieved, out of all non-relevant documents available:
fall-out = | { non-relevant documents } ∩ { retrieved documents } | | { non-relevant documents } | In binary classification, fall-out is closely related to specificity and is equal to ( 1 − specificity ) . It can be looked at as the probability that a non-relevant document is retrieved by the query.
It is trivial to achieve fall-out of 0% by returning zero documents in response to any query.
The weighted harmonic mean of precision and recall, the traditional F-measure or balanced F-score is:
F = 2 ⋅ p r e c i s i o n ⋅ r e c a l l ( p r e c i s i o n + r e c a l l ) This is also known as the F 1 measure, because recall and precision are evenly weighted.
The general formula for non-negative real β is:
F β = ( 1 + β 2 ) ⋅ ( p r e c i s i o n ⋅ r e c a l l ) ( β 2 ⋅ p r e c i s i o n + r e c a l l ) Two other commonly used F measures are the F 2 measure, which weights recall twice as much as precision, and the F 0.5 measure, which weights precision twice as much as recall.
The F-measure was derived by van Rijsbergen (1979) so that F β "measures the effectiveness of retrieval with respect to a user who attaches β times as much importance to recall as precision". It is based on van Rijsbergen's effectiveness measure E = 1 − 1 α P + 1 − α R . Their relationship is:
F β = 1 − E where
α = 1 1 + β 2 F-measure can be a better single metric when compared to precision and recall; both precision and recall give different information that can complement each other when combined. If one of them excels more than the other, F-measure will reflect it.
Precision and recall are single-value metrics based on the whole list of documents returned by the system. For systems that return a ranked sequence of documents, it is desirable to also consider the order in which the returned documents are presented. By computing a precision and recall at every position in the ranked sequence of documents, one can plot a precision-recall curve, plotting precision p ( r ) as a function of recall r . Average precision computes the average value of p ( r ) over the interval from r = 0 to r = 1 :
AveP = ∫ 0 1 p ( r ) d r That is the area under the precision-recall curve. This integral is in practice replaced with a finite sum over every position in the ranked sequence of documents:
AveP = ∑ k = 1 n P ( k ) Δ r ( k ) where k is the rank in the sequence of retrieved documents, n is the number of retrieved documents, P ( k ) is the precision at cut-off k in the list, and Δ r ( k ) is the change in recall from items k − 1 to k .
This finite sum is equivalent to:
AveP = ∑ k = 1 n ( P ( k ) × rel ( k ) ) number of relevant documents where rel ( k ) is an indicator function equaling 1 if the item at rank k is a relevant document, zero otherwise. Note that the average is over all relevant documents and the relevant documents not retrieved get a precision score of zero.
Some authors choose to interpolate the p ( r ) function to reduce the impact of "wiggles" in the curve. For example, the PASCAL Visual Object Classes challenge (a benchmark for computer vision object detection) computes average precision by averaging the precision over a set of evenly spaced recall levels {0, 0.1, 0.2, ... 1.0}:
AveP = 1 11 ∑ r ∈ { 0 , 0.1 , … , 1.0 } p interp ( r ) where p interp ( r ) is an interpolated precision that takes the maximum precision over all recalls greater than r :
p interp ( r ) = max r ~ : r ~ ≥ r p ( r ~ ) .
An alternative is to derive an analytical p ( r ) function by assuming a particular parametric distribution for the underlying decision values. For example, a binormal precision-recall curve can be obtained by assuming decision values in both classes to follow a Gaussian distribution.
For modern (Web-scale) information retrieval, recall is no longer a meaningful metric, as many queries have thousands of relevant documents, and few users will be interested in reading all of them. Precision at k documents (P@k) is still a useful metric (e.g., P@10 or "Precision at 10" corresponds to the number of relevant results on the first search results page), but fails to take into account the positions of the relevant documents among the top k. Another shortcoming is that on a query with fewer relevant results than k, even a perfect system will have a score less than 1. It is easier to score manually since only the top k results need to be examined to determine if they are relevant or not.
R-precision requires knowing all documents that are relevant to a query. The number of relevant documents, R , is used as the cutoff for calculation, and this varies from query to query. For example, if there are 15 documents relevant to "red" in a corpus (R=15), R-precision for "red" looks at the top 15 documents returned, counts the number that are relevant r turns that into a relevancy fraction: r / R = r / 15 .
Precision is equal to recall at the R-th position.
Empirically, this measure is often highly correlated to mean average precision.
Mean average precision for a set of queries is the mean of the average precision scores for each query.
MAP = ∑ q = 1 Q A v e P ( q ) Q where Q is the number of queries.
DCG uses a graded relevance scale of documents from the result set to evaluate the usefulness, or gain, of a document based on its position in the result list. The premise of DCG is that highly relevant documents appearing lower in a search result list should be penalized as the graded relevance value is reduced logarithmically proportional to the position of the result.
The DCG accumulated at a particular rank position p is defined as:
D C G p = r e l 1 + ∑ i = 2 p r e l i log 2 i . Since result set may vary in size among different queries or systems, to compare performances the normalised version of DCG uses an ideal DCG. To this end, it sorts documents of a result list by relevance, producing an ideal DCG at position p ( I D C G p ), which normalizes the score:
n D C G p = D C G p I D C G p . The nDCG values for all queries can be averaged to obtain a measure of the average performance of a ranking algorithm. Note that in a perfect ranking algorithm, the D C G p will be the same as the I D C G p producing an nDCG of 1.0. All nDCG calculations are then relative values on the interval 0.0 to 1.0 and so are cross-query comparable.
Mean reciprocal rankSpearman's rank correlation coefficientbpref - a summation-based measure of how many relevant documents are ranked before irrelevant documentsGMAP - geometric mean of (per-topic) average precisionMeasures based on marginal relevance and document diversity - see Relevance (information retrieval) § Problems and alternativesVisualizations of information retrieval performance include:
Graphs which chart precision on one axis and recall on the otherHistograms of average precision over various topicsReceiver operating characteristic (ROC curve)Confusion matrixBefore the 1900s1801: Joseph Marie Jacquard invents the Jacquard loom, the first machine to use punched cards to control a sequence of operations.1880s: Herman Hollerith invents an electro-mechanical data tabulator using punch cards as a machine readable medium.1890 Hollerith cards, keypunches and tabulators used to process the 1890 US Census data.1920s-1930sEmanuel Goldberg submits patents for his "Statistical Machine” a document search engine that used photoelectric cells and pattern recognition to search the metadata on rolls of microfilmed documents.1940s–1950slate 1940s: The US military confronted problems of indexing and retrieval of wartime scientific research documents captured from Germans.1945: Vannevar Bush's As We May Think appeared in Atlantic Monthly.1947: Hans Peter Luhn (research engineer at IBM since 1941) began work on a mechanized punch card-based system for searching chemical compounds.1950s: Growing concern in the US for a "science gap" with the USSR motivated, encouraged funding and provided a backdrop for mechanized literature searching systems (Allen Kent et al.) and the invention of citation indexing (Eugene Garfield).1950: The term "information retrieval" was coined by Calvin Mooers.1951: Philip Bagley conducted the earliest experiment in computerized document retrieval in a master thesis at MIT.1955: Allen Kent joined Case Western Reserve University, and eventually became associate director of the Center for Documentation and Communications Research. That same year, Kent and colleagues published a paper in American Documentation describing the precision and recall measures as well as detailing a proposed "framework" for evaluating an IR system which included statistical sampling methods for determining the number of relevant documents not retrieved.1958: International Conference on Scientific Information Washington DC included consideration of IR systems as a solution to problems identified. See: Proceedings of the International Conference on Scientific Information, 1958 (National Academy of Sciences, Washington, DC, 1959)1959: Hans Peter Luhn published "Auto-encoding of documents for information retrieval."1960s:early 1960s: Gerard Salton began work on IR at Harvard, later moved to Cornell.1960: Melvin Earl Maron and John Lary Kuhns published "On relevance, probabilistic indexing, and information retrieval" in the Journal of the ACM 7(3):216–244, July 1960.1962:Cyril W. Cleverdon published early findings of the Cranfield studies, developing a model for IR system evaluation. See: Cyril W. Cleverdon, "Report on the Testing and Analysis of an Investigation into the Comparative Efficiency of Indexing Systems". Cranfield Collection of Aeronautics, Cranfield, England, 1962.Kent published Information Analysis and Retrieval.1963:
Weinberg report "Science, Government and Information" gave a full articulation of the idea of a "crisis of scientific information." The report was named after Dr. Alvin Weinberg.Joseph Becker and Robert M. Hayes published text on information retrieval. Becker, Joseph; Hayes, Robert Mayo. Information storage and retrieval: tools, elements, theories. New York, Wiley (1963).1964:
Karen Spärck Jones finished her thesis at Cambridge, Synonymy and Semantic Classification, and continued work on computational linguistics as it applies to IR.The National Bureau of Standards sponsored a symposium titled "Statistical Association Methods for Mechanized Documentation." Several highly significant papers, including G. Salton's first published reference (we believe) to the SMART system.mid-1960s:
National Library of Medicine developed MEDLARS Medical Literature Analysis and Retrieval System, the first major machine-readable database and batch-retrieval system.Project Intrex at MIT.1965: J. C. R. Licklider published
Libraries of the Future.
1966: Don Swanson was involved in studies at University of Chicago on Requirements for Future Catalogs.
late 1960s: F. Wilfrid Lancaster completed evaluation studies of the MEDLARS system and published the first edition of his text on information retrieval.
1968:
Gerard Salton published Automatic Information Organization and Retrieval.John W. Sammon, Jr.'s RADC Tech report "Some Mathematics of Information Storage and Retrieval..." outlined the vector model.1969: Sammon's "A nonlinear mapping for data structure analysis" (IEEE Transactions on Computers) was the first proposal for visualization interface to an IR system.
1970searly 1970s:First online systems—NLM's AIM-TWX, MEDLINE; Lockheed's Dialog; SDC's ORBIT.Theodor Nelson promoting concept of hypertext, published Computer Lib/Dream Machines.1971: Nicholas Jardine and Cornelis J. van Rijsbergen published "The use of hierarchic clustering in information retrieval", which articulated the "cluster hypothesis."
1975: Three highly influential publications by Salton fully articulated his vector processing framework and term discrimination model:
A Theory of Indexing (Society for Industrial and Applied Mathematics)A Theory of Term Importance in Automatic Text Analysis (JASIS v. 26)A Vector Space Model for Automatic Indexing (CACM 18:11)1978: The First ACM SIGIR conference.
1979: C. J. van Rijsbergen published
Information Retrieval (Butterworths). Heavy emphasis on probabilistic models.
1979: Tamas Doszkocs implemented the CITE natural language user interface for MEDLINE at the National Library of Medicine. The CITE system supported free form query input, ranked output and relevance feedback.
1980s1980: First international ACM SIGIR conference, joint with British Computer Society IR group in Cambridge.1982: Nicholas J. Belkin, Robert N. Oddy, and Helen M. Brooks proposed the ASK (Anomalous State of Knowledge) viewpoint for information retrieval. This was an important concept, though their automated analysis tool proved ultimately disappointing.1983: Salton (and Michael J. McGill) published Introduction to Modern Information Retrieval (McGraw-Hill), with heavy emphasis on vector models.1985: David Blair and Bill Maron publish: An Evaluation of Retrieval Effectiveness for a Full-Text Document-Retrieval Systemmid-1980s: Efforts to develop end-user versions of commercial IR systems.1985–1993: Key papers on and experimental systems for visualization interfaces.Work by Donald B. Crouch, Robert R. Korfhage, Matthew Chalmers, Anselm Spoerri and others.1989: First World Wide Web proposals by Tim Berners-Lee at CERN.1990s1992: First TREC conference.1997: Publication of Korfhage's Information Storage and Retrieval with emphasis on visualization and multi-reference point systems.late 1990s: Web search engines implementation of many features formerly found only in experimental IR systems. Search engines become the most common and maybe best instantiation of IR models.Tony Kent Strix awardGerard Salton AwardCenter for Intelligent Information Retrieval (CIIR) at the University of Massachusetts Amherst Information Retrieval Group at the University of Glasgow Information and Language Processing Systems (ILPS) at the University of Amsterdam