
 | ||
This article discusses how information theory (a branch of mathematics studying the transmission, processing and storage of information) is related to measure theory (a branch of mathematics related to integration and probability).
Contents
Measures in information theory
Many of the concepts in information theory have separate definitions and formulas for continuous and discrete cases. For example, entropy
These separate definitions can be more closely related in terms of measure theory. For discrete random variables, probability mass functions can be considered density functions with respect to the counting measure. Thinking of both the integral and the sum as integration on a measure space allows for a unified treatment.
Consider the formula for the differential entropy of a continuous random variable
This can usually be interpreted as the following Riemann–Stieltjes integral:
where
If instead,
The integral expression, and the general concept, are identical in the continuous case; the only difference is the measure used. In both cases the probability density function
If
If instead of the underlying measure μ we take another probability measure
where the integral runs over the support of
Entropy as a "measure"
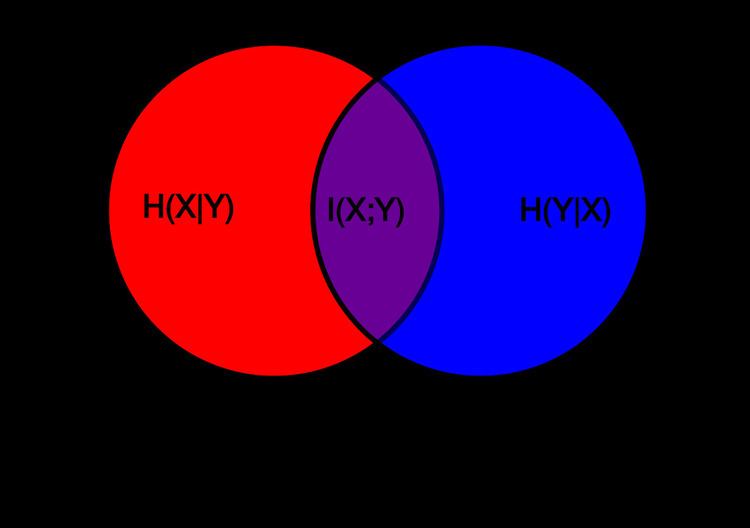
There is an analogy between Shannon's basic "measures" of the information content of random variables and a measure over sets. Namely the joint entropy, conditional entropy, and mutual information can be considered as the measure of a set union, set difference, and set intersection, respectively (Reza pp. 106–108).
If we associate the existence of abstract sets
where
we find that Shannon's "measure" of information content satisfies all the postulates and basic properties of a formal signed measure over sets, as commonly illustrated in an information diagram. This allows the sum of two measures to be written:
and the analog of Bayes' theorem (
This can be a handy mnemonic device in some situations, e.g.
Note that measures (expectation values of the logarithm) of true probabilities are called "entropy" and generally represented by the letter H, while other measures are often referred to as "information" or "correlation" and generally represented by the letter I. For notational simplicity, the letter I is sometimes used for all measures.
Multivariate mutual information
Certain extensions to the definitions of Shannon's basic measures of information are necessary to deal with the σ-algebra generated by the sets that would be associated to three or more arbitrary random variables. (See Reza pp. 106–108 for an informal but rather complete discussion.) Namely
in order to define the (signed) measure over the whole σ-algebra. There is no single universally accepted definition for the mutivariate mutual information, but the one that corresponds here to the measure of a set intersection is due to Fano (Srinivasa). The definition is recursive. As a base case the mutual information of a single random variable is defined to be its entropy:
where the conditional mutual information is defined as
The first step in the recursion yields Shannon's definition
Many other variations are possible for three or more random variables: for example,