
 | ||
Compressed sensing (also known as compressive sensing, compressive sampling, or sparse sampling) is a signal processing technique for efficiently acquiring and reconstructing a signal, by finding solutions to underdetermined linear systems. This is based on the principle that, through optimization, the sparsity of a signal can be exploited to recover it from far fewer samples than required by the Shannon-Nyquist sampling theorem. There are two conditions under which recovery is possible. The first one is sparsity which requires the signal to be sparse in some domain. The second one is incoherence which is applied through the isometric property which is sufficient for sparse signals.
Contents
- Overview
- History
- Underdetermined linear system
- Solution reconstruction method
- Motivation and Applications
- Existing approaches
- Applications
- Photography
- Holography
- Facial recognition
- Magnetic resonance imaging
- Network tomography
- Shortwave infrared cameras
- Aperture synthesis in radio astronomy
- Transmission electron microscopy
- References
Overview
A common goal of the engineering field of signal processing is to reconstruct a signal from a series of sampling measurements. In general, this task is impossible because there is no way to reconstruct a signal during the times that the signal is not measured. Nevertheless, with prior knowledge or assumptions about the signal, it turns out to be possible to perfectly reconstruct a signal from a series of measurements. Over time, engineers have improved their understanding of which assumptions are practical and how they can be generalized.
An early breakthrough in signal processing was the Nyquist–Shannon sampling theorem. It states that if the signal's highest frequency is less than half of the sampling rate, then the signal can be reconstructed perfectly. The main idea is that with prior knowledge about constraints on the signal’s frequencies, fewer samples are needed to reconstruct the signal.
Around 2004, Emmanuel Candès, Terence Tao, and David Donoho proved that given knowledge about a signal's sparsity, the signal may be reconstructed with even fewer samples than the sampling theorem requires. This idea is the basis of compressed sensing.
History
Compressed sensing relies on L1 techniques, which several other scientific fields have used historically. In statistics, the least squares method was complemented by the
At first glance, compressed sensing might seem to violate the sampling theorem, because compressed sensing depends on the sparsity of the signal in question and not its highest frequency. This is a misconception, because the sampling theorem guarantees perfect reconstruction given sufficient, not necessary, conditions. A sampling method fundamentally different from classical fixed-rate sampling cannot "violate" the sampling theorem. Sparse signals with high frequency components can be highly under-sampled using compressed sensing compared to classical fixed-rate sampling.
Underdetermined linear system
An underdetermined system of linear equations has more unknowns than equations and generally has an infinite number of solutions. In order to choose a solution to such a system, one must impose extra constraints or conditions (such as smoothness) as appropriate.
In compressed sensing, one adds the constraint of sparsity, allowing only solutions which have a small number of nonzero coefficients. Not all underdetermined systems of linear equations have a sparse solution. However, if there is a unique sparse solution to the underdetermined system, then the compressed sensing framework allows the recovery of that solution.
Solution / reconstruction method
Compressed sensing takes advantage of the redundancy in many interesting signals—they are not pure noise. In particular, many signals are sparse, that is, they contain many coefficients close to or equal to zero, when represented in some domain. This is the same insight used in many forms of lossy compression.
Compressed sensing typically starts with taking a weighted linear combination of samples also called compressive measurements in a basis different from the basis in which the signal is known to be sparse. The results found by Emmanuel Candès, Justin Romberg, Terence Tao and David Donoho, showed that the number of these compressive measurements can be small and still contain nearly all the useful information. Therefore, the task of converting the image back into the intended domain involves solving an underdetermined matrix equation since the number of compressive measurements taken is smaller than the number of pixels in the full image. However, adding the constraint that the initial signal is sparse enables one to solve this underdetermined system of linear equations.
The least-squares solution to such problems is to minimize the
To enforce the sparsity constraint when solving for the underdetermined system of linear equations, one can minimize the number of nonzero components of the solution. The function counting the number of non-zero components of a vector was called the
Candès. et al., proved that for many problems it is probable that the
Motivation and Applications
Role of TV regularization
Total variation can be seen as a non-negative real-valued functional defined on the space of real-valued functions (for the case of functions of one variable) or on the space of integrable functions (for the case of functions of several variables). For signals, especially, total variation refers to the integral of the absolute gradient of the signal. In signal and image reconstruction, it is applied as total variation regularization where the underlying principle is that signals with excessive details have high total variation and that removing these details, while retaining important information such as edges, would reduce the total variation of the signal and make the signal subject closer to the original signal in the problem.
For the purpose of signal and image reconstruction,
Recent progress on this problem involves using an iteratively directional TV refinement for CS reconstruction. This method would have 2 stages: the first stage would estimate and refine the initial orientation field - which is defined as a noisy point-wise initial estimate, through edge-detection, of the given image. In the second stage, the CS reconstruction model is presented by utilizing directional TV regularizer. More details about these TV-based approaches - iteratively reweighted l1 minimization, edge-preserving TV and iterative model using directional orientation field and TV- are provided below.
Existing approaches
Iteratively reweighted l 1 minimization
In the CS reconstruction models using constrained
Advantages and disadvantages
Early iterations may find inaccurate sample estimates, however this method will down-sample these at a later stage to give more weight to the smaller non-zero signal estimates. One of the disadvantages is the need for defining a valid starting point as a global minimum might not be obtained every time due to the concavity of the function. Another disadvantage is that this method tends to uniformly penalize the image gradient irrespective of the underlying image structures. This causes over-smoothing of edges, especially those of low contrast regions,subsequently leading to loss of low contrast information.The advantages of this method include: reduction of the sampling rate for sparse signals; reconstruction of the image while being robust to the removal of noise and other artifacts; and use of very few iterations. This can also help in recovering images with sparse gradients.
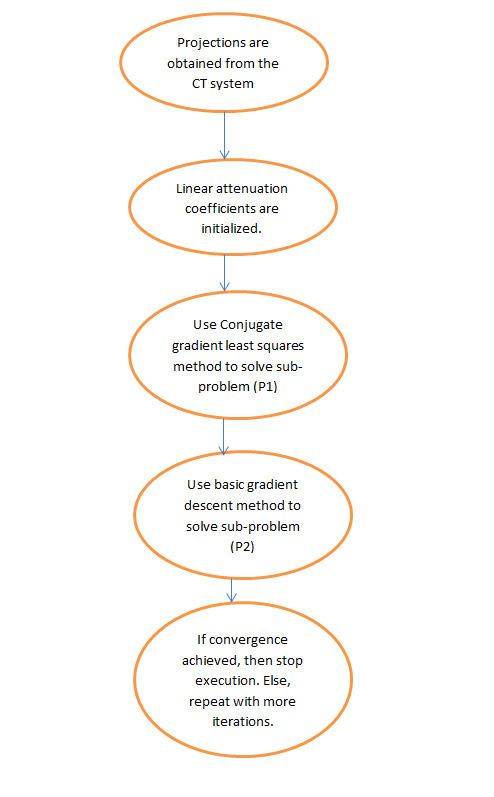
In the figure shown below, P1 refers to the first-step of the iterative reconstruction process, of the projection matrix P of the fan-beam geometry, which is constrained by the data fidelity term. This may contain noise and artifacts as no regularization is performed. The minimization of P1 is solved through the conjugate gradient least squares method. P2 refers to the second step of the iterative reconstruction process wherein it utilizes the edge-preserving total variation regularization term to remove noise and artifacts, and thus improve the quality of the reconstructed image/signal. The minimization of P2 is done through a simple gradient descent method. Convergence is determined by testing, after each iteration, for image positivity, by checking if
Edge-preserving total variation (TV) based compressed sensing
This is an iterative CT reconstruction algorithm with edge-preserving TV regularization to reconstruct CT images from highly undersampled data obtained at low dose CT through low current levels (milliampere). In order to reduce the imaging dose, one of the approaches used is to reduce the number of x-ray projections acquired by the scanner detectors. However, this insufficient projection data which is used to reconstruct the CT image can cause streaking artifacts. Furthermore, using these insufficient projections in standard TV algorithms end up making the problem under-determined and thus leading to infinitely many possible solutions. In this method, an additional penalty weighted function is assigned to the original TV norm. This allows for easier detection of sharp discontinuities in intensity in the images and thereby adapt the weight to store the recovered edge information during the process of signal/image reconstruction. The parameter
Advantages and disadvantages
Some of the disadvantages of this method are the absence of smaller structures in the reconstructed image and degradation of image resolution. This edge preserving TV algorithm, however, requires fewer iterations than the conventional TV algorithm. Analyzing the horizontal and vertical intensity profiles of the reconstructed images, it can be seen that there are sharp jumps at edge points and negligible, minor fluctuation at non-edge points. Thus, this method leads to low relative error and higher correlation as compared to the TV method. It also effectively suppresses and removes any form of image noise and image artifacts such as streaking.
Iterative model using a directional orientation field and directional total variation
To prevent over-smoothing of edges and texture details and to obtain a reconstructed CS image which is accurate and robust to noise and artifacts, this method is used. First, an initial estimate of the noisy point-wise orientation field of the image
The structure tensor obtained is convolved with a Gaussian kernel
To overcome this drawback, a refined orientation model is defined in which the data term reduces the effect of noise and improves accuracy while the second penalty term with the L2-norm is a fidelity term which ensures accuracy of initial coarse estimation.
This orientation field is introduced into the directional total variation optimization model for CS reconstruction through the equation:
The Augmented Lagrangian method for the orientation field,
Here,
For the orientation field refinement model, the Lagrangian multipliers are updated in the iterative process as follows:
For the iterative directional total variation refinement model, the Lagrangian multipliers are updated as follows:
Here,
Advantages and disadvantages
Based on Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) metrics and known ground-truth images for testing performance, it is concluded that iterative directional total variation has a better reconstructed performance than the non-iterative methods in preserving edge and texture areas. The orientation field refinement model plays a major role in this improvement in performance as it increases the number of directionless pixels in the flat area while enhancing the orientation field consistency in the regions with edges.
Applications
The field of compressive sensing is related to several topics in signal processing and computational mathematics, such as underdetermined linear-systems, group testing, heavy hitters, sparse coding, multiplexing, sparse sampling, and finite rate of innovation. Its broad scope and generality has enabled several innovative CS-enhanced approaches in signal processing and compression, solution of inverse problems, design of radiating systems, radar and through-the-wall imaging, and antenna characterization. Imaging techniques having a strong affinity with compressive sensing include coded aperture and computational photography. Implementations of compressive sensing in hardware at different technology readiness levels is available.
Conventional CS reconstruction uses sparse signals (usually sampled at a rate less than the Nyquist sampling rate) for reconstruction through constrained
Photography
Compressed sensing is used in a mobile phone camera sensor. The approach allows a reduction in image acquisition energy per image by as much as a factor of 15 at the cost of complex decompression algorithms; the computation may require an off-device implementation.
Compressed sensing is used in single-pixel cameras from Rice University. Bell Labs employed the technique in a lensless single-pixel camera that takes stills using repeated snapshots of randomly chosen apertures from a grid. Image quality improves with the number of snapshots, and generally requires a small fraction of the data of conventional imaging, while eliminating lens/focus-related aberrations.
Holography
Compressed sensing can be used to improve image reconstruction in holography by increasing the number of voxels one can infer from a single hologram. It is also used for image retrieval from undersampled measurements in optical and millimeter-wave holography.
Facial recognition
Compressed sensing is being used in facial recognition applications.
Magnetic resonance imaging
Compressed sensing has been used to shorten magnetic resonance imaging scanning sessions on conventional hardware. Reconstruction methods include
Compressed sensing addresses the issue of high scan time by enabling faster acquisition by measuring fewer Fourier coefficients. This produces a high-quality image with relatively lower scan time. Another application (also discussed ahead) is for CT reconstruction with fewer X-ray projections. Compressed sensing, in this case, removes the high spatial gradient parts - mainly, image noise and artifacts. This holds tremendous potential as one can obtain high-resolution CT images at low radiation doses (through lower current-mA settings).
Network tomography
Compressed sensing has showed outstanding results in the application of network tomography to network management. Network delay estimation and network congestion detection can both be modeled as underdetermined systems of linear equations where the coefficient matrix is the network routing matrix. Moreover, in the Internet, network routing matrices usually satisfy the criterion for using compressed sensing.
Shortwave-infrared cameras
Commercial shortwave-infrared cameras based upon compressed sensing are available. These cameras have light sensitivity from 0.9 µm to 1.7 µm, which are wavelengths invisible to the human eye.
Aperture synthesis in radio astronomy
In the field of radio astronomy, compressed sensing has been proposed for deconvolving an interferometric image. In fact, the Högbom CLEAN algorithm that has been in use for the deconvolution of radio images since 1974, is similar to compressed sensing's matching pursuit algorithm.
Transmission electron microscopy
Compressed sensing combined with a moving aperture has been used to increase the acquisition rate of images in a transmission electron microscope. In scanning mode, compressive sensing combined with random scanning of the electron beam has enabled both faster acquisition and less electron dose, which allows for imaging of electron beam sensitive materials.