
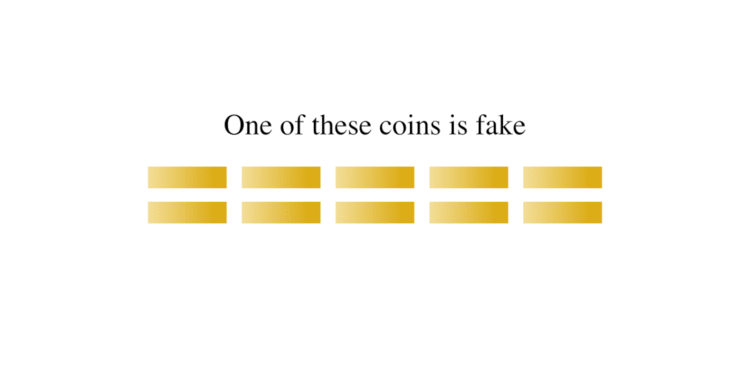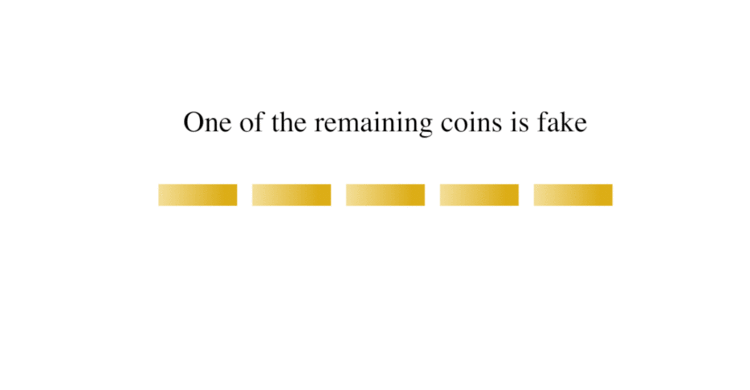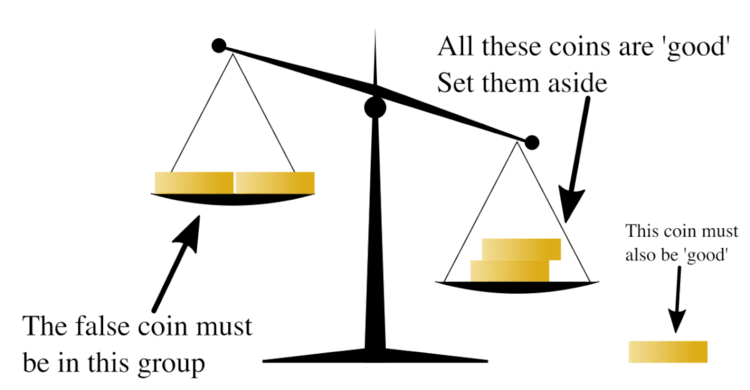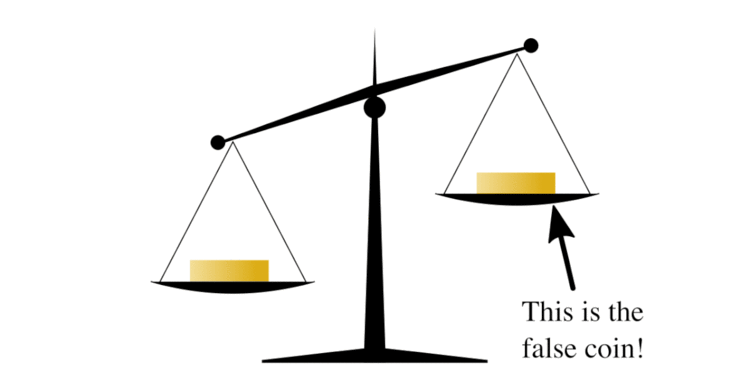 | ||
In combinatorial mathematics, group testing refers to any procedure which breaks up the task of locating elements of a set which have certain properties into tests on groups of items, rather than on individual elements. A familiar example of this type of technique is the false coin problem of recreational mathematics. In this problem there are n coins and one of them is false, weighing less than a real coin. The objective is to find the false coin, using a balance scale, in the fewest number of weighings. By repeatedly dividing the coins in half and comparing the two halves, the false coin can be found quickly as it is always in the lighter half.
Contents
- Background
- Types of group testing algorithm
- Formalization of the problem
- Formal notion of a test
- Goal
- Definitions and initial bounds
- Mathematical representation of non adaptive algorithms
- Generalized binary splitting algorithm
- Non adaptive algorithms
- Combinatorial Orthogonal Matching Pursuit COMP
- Definite Defectives DD
- Sequential COMP SCOMP
- Bounds
- Lower bound on t a d n displaystyle tadn
- Upper bound on t a d n displaystyle tadn
- Upper bound on t 1 n displaystyle t1n
- Upper bounds for non adaptive group testing
- References
Schemes for carrying out such group testing can be simple or complex and the tests involved at each stage may be different. Schemes in which the tests for the next stage depend on the results of the previous stages are called adaptive procedures, while schemes designed so that all the tests are known beforehand are called non-adaptive procedures. The structure of the scheme of the tests involved in a non-adaptive procedure is known as a pooling design.
Background
The field of (Combinatorial) Group Testing was introduced by Robert Dorfman in 1943. The motivation arose during the Second World War when the United States Public Health Service and the Selective service embarked upon a large scale project to weed out all syphilitic men called up for induction. Testing an individual for syphilis involves drawing a blood sample from them and then analysing the sample to determine the presence or absence of syphilis. However, at the time, performing this test was expensive, and testing every soldier individually would have been very cost heavy and inefficient.
Supposing there are
The feasibility of a more effective testing scheme hinges on the following property. We can combine blood samples and test a combined sample together to check if at least one soldier has syphilis. This is the central idea behind group testing. If one or more of the soldiers in this group has syphilis, then a test is wasted (more tests need to be performed to find which soldier(s) it was). On the other hand, if no one in the pool has syphilis then many tests are saved.
Modern interest in these testing schemes has been rekindled by the Human Genome Project.
Types of group-testing algorithm
Group-testing algorithms can be described as adaptive or non-adaptive. An adaptive algorithm proceeds by performing a test, and then using the result (and all past results) to decide which next test to perform. On the other hand, in non-adaptive algorithms all tests are decided in advance. Although adaptive algorithms offer much more freedom in design, it is known that adaptive group-testing algorithms do not improve upon non-adaptive group-testing algorithms by more than a constant factor in the number of tests required to identify the set of defective items. In addition to this, non-adaptive methods are often useful in practice because one knows in advance all the tests one needs to perform, allowing for the effective distribution of the testing process.
As well as adaptivity, all group testing algorithms are either combinatorial or probabilistic. A combinatorial algorithm finds all the defectives with certainty. In contrast, a probabilistic algorithm has some non-zero probability of making a mistake (i.e. deciding a defective item is non-defective or vice versa). It is known that zero-error algorithms require significantly more tests asymptotically (in the number of defective items) than algorithms that allow asymptotically small probabilities of error.
Another class of algorithms are so-called noisy algorithms. These deal with the situation that with some non-zero probability,
Formalization of the problem
We now formalize the group-testing problem abstractly.
Let the total number of items to be tested be
The Hamming Weight of
Formal notion of a test
A query/test
Note that the addition operation used by the summation is the logical OR, i.e.
Goal
The goal of group testing is to compute or estimate
Definitions and initial bounds
Consider the case when only one person in the group will test positive. Then if we tested in the naive way, in the best case we would at least have to test the first person to find out if he/she is infected. However, in the worst case one might have to end up testing the entire group and only the last person we test will turn out to really be the one who was infected. Hence,
In summary,
Mathematical representation of non-adaptive algorithms
Algorithms for non-adaptive group testing consist of two distinct phases. First, it is decided how many tests to perform and which items to include in each test. This is usually encoded in an
As well as the vector
These notions can be expressed more formally as follows. Let
Under this setup,
Generalized binary splitting algorithm
The generalized binary splitting algorithm is an essentially-optimal adaptive group-testing algorithm that proceeds as follows:
- If
n ≤ 2 d − 2 , test then items individually. Otherwise, setl = n − d + 1 andα = ⌊ log l / d ⌋ . - Test a group of size
2 α n := n − 2 α x , of non-defective items; setn := n − 1 − x andd := d − 1 . Go to step 1.
The generalized binary splitting algorithm requires no more than
Non-adaptive algorithms
Non-adaptive group-testing algorithms tend to assume that the number of defectives, or at least a good upper bound on them, is known. We will denote this quantity
Combinatorial Orthogonal Matching Pursuit (COMP)
Combinatorial Orthogonal Matching Pursuit, or COMP, is a simple non-adaptive group-testing algorithm that forms the basis for the more complicated algorithms that follow in this section.
First, each entry of the testing matrix is chosen i.i.d. to be
The decoding step proceeds column-wise (i.e. by item). If every test in which an item appears is positive, then the item is declared defective; otherwise the item is assumed to be non-defective. Or equivalently, if an item appears in any test whose outcome is negative, the item is declared non-defective; otherwise the item is assumed to be defective. Of particular note here is that this algorithm never creates false negatives, though a false positive occurs when all locations with ones in the j-th column of
The COMP algorithm requires no more than
In the noisy case, we relax the requirement in the original COMP algorithm that the set of locations of ones in any column of
Definite Defectives (DD)
The definite defectives method is an extension of the COMP algorithm that attempts to remove any false positives. Performance guarantees for DD have been shown to strictly exceed those of COMP.
The decoding step uses a useful property of the COMP algorithm: that every item that COMP declares non-defective is certainly non-defective (that is, there are no false negatives). It proceeds as follows:
- We first run the COMP algorithm, and remove any non-defectives that it detects. All remaining items are now “possibly defective”
- Next the algorithm looks at all the positive tests. If an item appears as the only “possible defective” in a test, then it must be defective, so the algorithm declares it to be defective.
- All other items are assumed to be non-defective. The justification for this last step comes from the assumption that the number of defectives is much smaller than the total number of items.
Note that steps 1 and 2 never make a mistake, so the algorithm can only make a mistake if it declares a defective item to be non-defective. Thus the DD algorithm can only create false negatives.
Sequential COMP (SCOMP)
SCOMP is an algorithm that makes use of the fact that DD makes no mistakes until the last step, were we assume remaining items to be defective. Let the set of declared defectives be
The algorithm proceeds as follows:
- First carry out steps 1 and 2 of the DD algorithm to obtain
K , an initial estimate for the set of defectives. - If
K explains every positive test, terminate the algorithm:K is our final estimate for the set of defectives. - If there are any unexplained tests, find the “possible defective” that appears in the largest number of unexplained tests, and declare it to be defective (that is, add it to the set
K ). Go to step 2.
In simulations, SCOMP has been shown to perform close to optimally.
Bounds
In the combinatorial setup, there are a number of upper and lower bounds on t(d,n) (and t^a(d,n)), the minimum number of tests required to detect all defectives.
Lower bound on t a ( d , n ) {displaystyle t^{a}(d,n)}
Fix a valid group testing scheme with
Now,
Thus we have proved that
Upper bound on t a ( d , n ) {displaystyle t^{a}(d,n)}
Since we know that the upper bound on the number of positives is
Upper bound on t ( 1 , n ) {displaystyle t(1,n)}
Thus as the upper and lower bounds are the same, we have a tight bound for
Upper bounds for non-adaptive group testing
For non-adaptive group testing upper bounds we shift focus toward disjunct matrices, which have been used for many of the bounds because of their nice properties. It has been shown that
Separately, we can see that the current known lower bound for