
 | ||
In molecular biology and genetics, sense is a concept used to compare the polarity of nucleic acid molecules, such as DNA or RNA, to other nucleic acid molecules. Depending on the context within molecular biology, sense may have slightly different meanings.
Contents
DNA sense
Molecular biologists call a single strand of DNA sense (or positive (+)) if an RNA version of the same sequence is translated or translatable into protein. Its complementary strand is called antisense (or negative (-) sense). Sometimes the phrase coding strand is encountered; however, protein coding and non-coding RNAs can be transcribed similarly from both strands, in some cases being transcribed in both directions from a common promoter region, or being transcribed from within introns, on both strands (see "ambisense" below).
Antisense DNA
The two complementary strands of double-stranded DNA (dsDNA) are usually differentiated as the "sense" strand and the "antisense" strand. The DNA sense strand looks like the messenger RNA (mRNA) and can be used to read the expected protein code; for example, ATG in the sense DNA may correspond to an AUG codon in the mRNA, encoding the amino acid methionine. However, the DNA sense strand itself is not used to make protein by the cell. It is the DNA antisense strand which serves as the source for the protein code, because, with bases complementary to the DNA sense strand, it is used as a template for the mRNA. Since transcription results in an RNA product complementary to the DNA template strand, the mRNA is complementary to the DNA antisense strand. The mRNA is what is used for translation (protein synthesis).
Hence, a base triplet 3'-TAC-5' in the DNA antisense strand can be used as a template which will result in an 5'-AUG-3' base triplet in mRNA (AUG is the codon for methionine, the start codon). The DNA sense strand will have the triplet ATG, which looks just like AUG but will not be used to make methionine because it will not be used to make mRNA. The DNA sense strand is called a "sense" strand not because it will be used to make protein (it won't be), but because it has a sequence that looks like the protein codon sequence.
In biology and research, short antisense molecules can interact with complementary strands of nucleic acids, modifying expression of genes. See the section on "antisense oligonucleotides" below.
Example with double-stranded DNA
DNA strand 1: antisense strand (transcribed to)→ RNA strand (sense)
DNA strand 2: sense strand
Some regions within a double strand of DNA code for genes, which are usually instructions specifying the order of amino acids in a protein along with regulatory sequences, splicing sites, noncoding introns, and other complicating details. For a cell to use this information, one strand of the DNA serves as a template for the synthesis of a complementary strand of RNA. The template DNA strand is called the transcribed strand with antisense sequence and the mRNA transcript is said to be sense sequence (the complement of antisense). Because the DNA is double-stranded, the strand complementary to the antisense sequence is called the non-transcribed strand and has the same sense sequence as the mRNA transcript (though T bases in DNA are substituted with U bases in RNA).
A note on the confusion between "sense" and "antisense" strands: The strand names actually depend on which direction you are writing the sequence that contains the information for proteins (the "sense" information), not on which strand is on the top or bottom (that is arbitrary). The only real biological information that is important for labeling strands is the location of the 5' phosphate group and the 3' hydroxyl group because these ends determine the direction of transcription and translation. A sequence 5' CGCTAT 3' is equivalent to a sequence written 3' TATCGC 5' as long as the 5' and 3' ends are noted. If the ends are not labeled, convention is to assume that the sequence is written from left to right in the 5' to 3' direction. Watson strand refers to 5' to 3' top strand (5' → 3'), whereas Crick strand refers to 5' to 3' bottom strand (3' ← 5'). Both Watson and Crick strands can be either sense or antisense strands depending on the gene whose sequences are displayed in the genome sequence database. For example, YEL021W, an alias of URA3 gene used in NCBI database, defines that this gene is located on the 21st open reading frame (ORF) from the centromere of the left arm (L) of Yeast (Y) chromosome number V (E), and that the expression coding strand is Watson strand (W). YKL074C defines the 74th ORF to the left of the centromere of chromosome XI and denotes coding strand from the Crick strand (C). Another confusing term referring to "Plus" and "Minus" strand is also widely used. Whether the strand is sense (positive) or antisense (negative), the default query sequence in NCBI BLAST alignment is "Plus" strand.
Ambisense
A single-stranded genome that contains both positive-sense and negative-sense is said to be ambisense. Bunyaviruses have 3 single-stranded RNA (ssRNA) fragments containing both positive-sense and negative-sense sections; arenaviruses are also ssRNA viruses with an ambisense genome, as they have 2 fragments that are mainly negative-sense except for part of the 5' ends of the large and small segments of their genome.
Antisense RNA
Antisense RNA is an RNA transcript that is complementary to endogenous mRNA. In other words, it is a non-coding strand complementary to the coding sequence of RNA; this is similar to negative-sense viral RNA. Introducing a transgene coding for antisense RNA is a technique used to block expression of a gene of interest. Radioactively-labelled antisense RNA can be used to show the level of transcription of genes in various cell types. Some alternative antisense structural types are being experimentally applied as antisense therapy, with at least one antisense therapy approved for use in humans.
When mRNA forms a duplex with a complementary antisense RNA sequence, translation is blocked. This process is related to RNA interference.
Antisense nucleic acid molecules have been used experimentally to bind to mRNA and prevent expression of specific genes. Antisense therapies are also in development; in the USA, the Food and Drug Administration (FDA) has approved phosphorothioate antisense oligos fomivirsen (Vitravene) and mipomersen (Kynamro) for human therapeutic use.
Cells can produce antisense RNA molecules naturally, called microRNA, which interact with complementary mRNA molecules and inhibit their expression.
RNA sense in viruses
In virology, the genome of an RNA virus can be said to be either positive-sense, also known as a "plus-strand", or negative-sense, also known as a "minus-strand". In most cases, the terms sense and strand are used interchangeably, making such terms as positive-strand equivalent to positive-sense, and plus-strand equivalent to plus-sense. Whether a virus genome is positive-sense or negative-sense can be used as a basis for classifying viruses.
Positive-sense
Positive-sense (5' to 3') viral RNA signifies that a particular viral RNA sequence may be directly translated into the desired viral proteins. Therefore, in positive-sense RNA viruses, the viral RNA genome can be considered viral mRNA, and can be immediately translated by the host cell. Unlike negative-sense RNA, positive-sense RNA is of the same sense as mRNA. Some viruses (e.g., Coronaviridae) have positive-sense genomes that can act as mRNA and be used directly to synthesize proteins without the help of a complementary RNA intermediate. Because of this, these viruses do not need to have an RNA polymerase packaged into the virion.
Negative-sense
Negative-sense (3' to 5') viral RNA is complementary to the viral mRNA and thus from it a positive-sense RNA must be produced by an RNA-dependent RNA polymerase prior to translation. Negative-sense RNA (like DNA) has a nucleotide sequence complementary to the mRNA that it encodes. Like DNA, this RNA cannot be translated into protein directly. Instead, it must first be transcribed into a positive-sense RNA that acts as an mRNA. Some viruses (Influenza, for example) have negative-sense genomes and so must carry an RNA polymerase inside the virion.
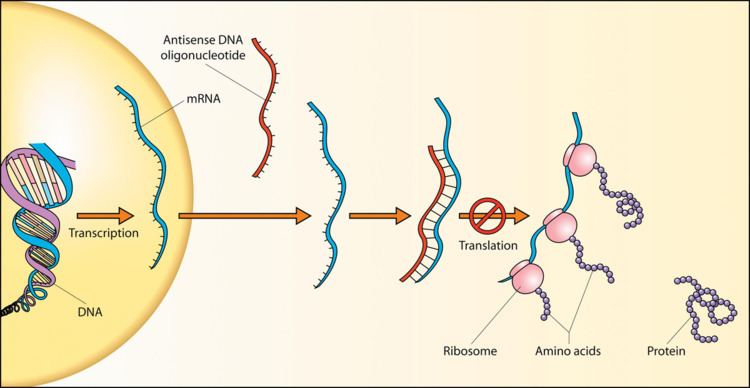
Antisense oligonucleotides
Gene silencing can be achieved by introducing into cells a short "antisense oligonucleotide" that is complementary to an RNA target. This experiment was first done by Zamecnik and Stephenson in 1978 and continues to be a useful approach, both for laboratory experiments and potentially for clinical applications (antisense therapy).
If the antisense oligonucleotide contains a stretch of DNA or a DNA mimic (phosphorothioate DNA, 2'F-ANA, or others) it can recruit RNase H to degrade the target RNA. This makes the mechanism of gene silencing catalytic. Double-stranded RNA can also act as a catalytic, enzyme-dependent antisense agent through the RNAi/siRNA pathway, involving target mRNA recognition through sense-antisense strand pairing followed by target mRNA degradation by the RNA-induced silencing complex (RISC). The R1 plasmid hok/sok system provides yet another example of an enzyme-dependent antisense regulation process through enzymatic degradation of the resulting RNA duplex.
Other antisense mechanisms are not enzyme-dependent, but involve steric blocking of their target RNA (e.g. to prevent translation or induce alternative splicing). Steric blocking antisense mechanisms often use oligonucleotides that are heavily modified. Since there is no need for RNase H recognition, this can include chemistries such as 2'-O-alkyl, peptide nucleic acid (PNA), locked nucleic acid (LNA), and Morpholino oligomers.