
 | ||
Regularization perspectives on support vector machines provide a way of interpreting support vector machines (SVMs) in the context of other machine learning algorithms. SVM algorithms categorize multidimensional data, with the goal of fitting the training set data well, but also avoiding overfitting, so that the solution generalizes to new data points. Regularization algorithms also aim to fit training set data and avoid overfitting. They do this by choosing a fitting function that has low error on the training set, but also is not too complicated, where complicated functions are functions with high norms in some function space. Specifically, Tikhonov regularization algorithms choose a function that minimize the sum of training set error plus the function's norm. The training set error can be calculated with different loss functions. For example, regularized least squares is a special case of Tikhonov regularization using the squared error loss as the loss function.
Contents
Regularization perspectives on support vector machines interpret SVM as a special case Tikhonov regularization, specifically Tikhonov regularization with the hinge loss for a loss function. This provides a theoretical framework with which to analyze SVM algorithms and compare them to other algorithms with the same goals: to generalize without overfitting. SVM was first proposed in 1995 by Corinna Cortes and Vladimir Vapnik, and framed geometrically as a method for finding hyperplanes that can separate multidimensional data into two categories. This traditional geometric interpretation of SVMs provides useful intuition about how SVMs work, but is difficult to relate to other machine learning techniques for avoiding overfitting like regularization, early stopping, sparsity and Bayesian inference. However, once it was discovered that SVM is also a special case of Tikhonov regularization, regularization perspectives on SVM provided the theory necessary to fit SVM within a broader class of algorithms. This has enabled detailed comparisons between SVM and other forms of Tikhonov regularization, and theoretical grounding for why it is beneficial to use SVM's loss function, the hinge loss.
Theoretical background
In the statistical learning theory framework, an algorithm is a strategy for choosing a function
where
When
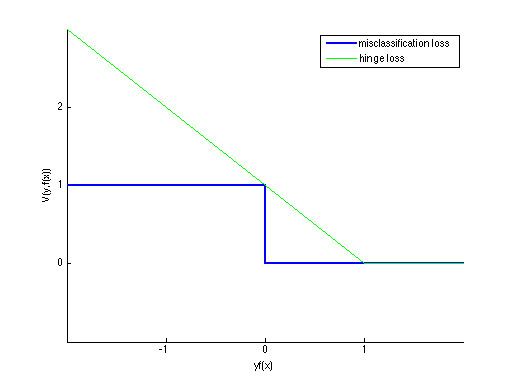
The simplest and most intuitive loss function for categorization is the misclassification loss, or 0-1 loss, which is 0 if
Derivation
The Tikhonov regularization problem can be shown to be equivalent to traditional formulations of SVM by expressing it in terms of the hinge loss. With the hinge loss,
where
Multiplying by
with