
 | ||
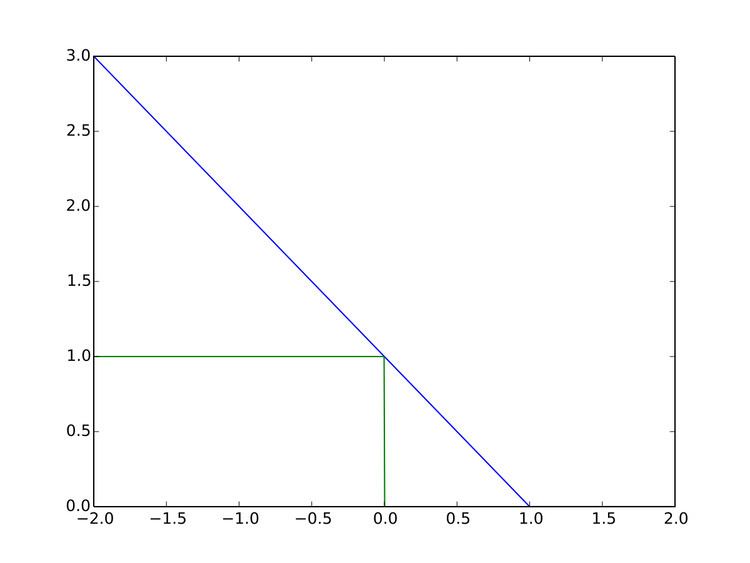
In machine learning, the hinge loss is a loss function used for training classifiers. The hinge loss is used for "maximum-margin" classification, most notably for support vector machines (SVMs). For an intended output t = ±1 and a classifier score y, the hinge loss of the prediction y is defined as
Contents
Note that y should be the "raw" output of the classifier's decision function, not the predicted class label. For instance, in linear SVMs,
It can be seen that when t and y have the same sign (meaning y predicts the right class) and
Extensions
While binary SVMs are commonly extended to multiclass classification in a one-vs.-all or one-vs.-one fashion, it is also possible to extend the hinge loss itself for such an end. Several different variations of multiclass hinge loss have been proposed. For example, Crammer and Singer defined it for a linear classifier as
Weston and Watkins provided a similar definition, but with a sum rather than a max:
In structured prediction, the hinge loss can be further extended to structured output spaces. Structured SVMs with margin rescaling use the following variant, where y denotes the SVM's parameters, φ the joint feature function, and Δ the Hamming loss:
Optimization
The hinge loss is a convex function, so many of the usual convex optimizers used in machine learning can work with it. It is not differentiable, but has a subgradient with respect to model parameters w of a linear SVM with score function
However, since the derivative of the hinge loss at
or the quadratically smoothed
suggested by Zhang. The modified Huber loss is a special case of this loss function with