
 | ||
Regularization, in mathematics and statistics and particularly in the fields of machine learning and inverse problems, is a process of introducing additional information in order to solve an ill-posed problem or to prevent overfitting.
Contents
- Introduction
- Generalization
- Tikhonov regularization
- Tikhonov regularized least squares
- Early stopping
- Theoretical motivation in least squares
- Regularizers for sparsity
- Proximal methods
- Group sparsity without overlaps
- Group sparsity with overlaps
- Regularizers for semi supervised learning
- Regularizers for multitask learning
- Sparse regularizer on columns
- Nuclear norm regularization
- Mean constrained regularization
- Clustered mean constrained regularization
- Graph based similarity
- Other uses of regularization in statistics and machine learning
- References
Introduction
In general, a regularization term
for a loss function
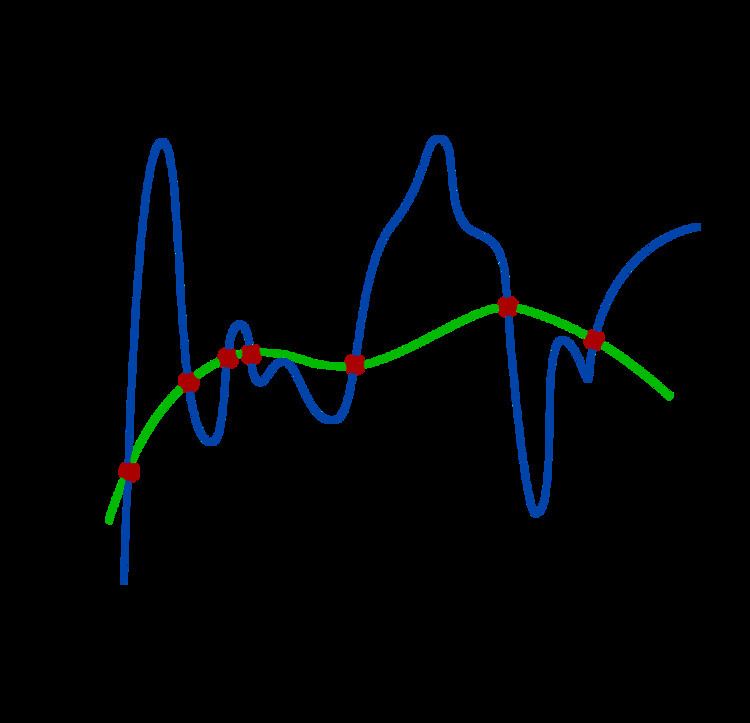
A theoretical justification for regularization is that it attempts to impose Occam's razor on the solution, as depicted in the figure. From a Bayesian point of view, many regularization techniques correspond to imposing certain prior distributions on model parameters.
Regularization can be used to learn simpler models, induce models to be sparse, introduce group structure into the learning problem, and more.
The same idea arose in many fields of science. For example, the least-squares method can be viewed as a very simple form of regularization. A simple form of regularization applied to integral equations, generally termed Tikhonov regularization after Andrey Nikolayevich Tikhonov, is essentially a trade-off between fitting the data and reducing a norm of the solution. More recently, non-linear regularization methods, including total variation regularization have become popular.
Generalization
Regularization can be motivated as a technique to improve the generalization of a learned model.
The goal of this learning problem is to find a function that fits or predicts the outcome (label) that minimizes the expected error over all possible inputs and labels. The expected error of a function
Typically in learning problems, only a subset of input data and labels are available, measured with some noise. Therefore, the expected error is unmeasurable, and the best surrogate available is the empirical error over the
Without bounds on the complexity of the function space (formally, the reproducing kernel Hilbert space) available, a model will be learned that incurs zero loss on the surrogate empirical error. If measurements (e.g. of
Tikhonov regularization
When learning a linear function, such that
In the case of a general function, we take the norm of the function in its reproducing kernel Hilbert space:
As the
Tikhonov regularized least squares
The learning problem with the least squares loss function and Tikhonov regularization can be solved analytically. Written in matrix form, the optimal
By construction of the optimization problem, other values of
During training, this algorithm takes
Early stopping
Early stopping can be viewed as regularization in time. Intuitively, a training procedure like gradient descent will tend to learn more and more complex functions as the number of iterations increases. By regularizing on time, the complexity of the model can be controlled, improving generalization.
In practice, early stopping is implemented by training on a training set and measuring accuracy on a statistically independent validation set. The model is trained until performance on the validation set no longer improves. The model is then tested on a testing set.
Theoretical motivation in least squares
Consider the finite approximation of Neumann series for an invertible matrix
This can be used to approximate the analytical solution of unregularized least squares, if
The exact solution to the unregularized least squares learning problem will minimize the empirical error, but may fail to generalize and minimize the expected error. By limiting
The algorithm above is equivalent to restricting the number of gradient descent iterations for the empirical risk
with the gradient descent update:
The base case is trivial. The inductive case is proved as follows:
Regularizers for sparsity
Assume that a dictionary
Enforcing a sparsity constraint on
A sensible sparsity constraint is the
The
Elastic net regularization tends to have a grouping effect, where correlated input features are assigned equal weights.
Elastic net regularization is commonly used in practice and is implemented in many machine learning libraries.
Proximal methods
While the
For a problem
and then iterate
The proximal method iteratively performs gradient descent and then projects the result back into the space permitted by
When
This allows for efficient computation.
Group sparsity without overlaps
Groups of features can be regularized by a sparsity constraint, which can be useful for expressing certain prior knowledge into an optimization problem.
In the case of a linear model with non-overlapping known groups, a regularizer can be defined:
This can be viewed as inducing a regularizer over the
This can be solved by the proximal method, where the proximal operator is a block-wise soft-thresholding function:
Group sparsity with overlaps
The algorithm described for group sparsity without overlaps can be applied to the case where groups do overlap, in certain situations. It should be noted that this will likely result in some groups with all zero elements, and other groups with some non-zero and some zero elements.
If it is desired to preserve the group structure, a new regularizer can be defined:
For each
Regularizers for semi-supervised learning
When labels are more expensive to gather than input examples, semi-supervised learning can be useful. Regularizers have been designed to guide learning algorithms to learn models that respect the structure of unsupervised training samples. If a symmetric weight matrix
If
The optimization problem
Note that the pseudo-inverse can be taken because
Regularizers for multitask learning
In the case of multitask learning,
Sparse regularizer on columns
This regularizer defines an L2 norm on each column and an L1 norm over all columns. It can be solved by proximal methods.
Nuclear norm regularization
Mean-constrained regularization
This regularizer constrains the functions learned for each task to be similar to the overall average of the functions across all tasks. This is useful for expressing prior information that each task is expected to share similarities with each other task. An example is predicting blood iron levels measured at different times of the day, where each task represents a different person.
Clustered mean-constrained regularization
This regularizer is similar to the mean-constrained regularizer, but instead enforces similarity between tasks within the same cluster. This can capture more complex prior information. This technique has been used to predict Netflix recommendations. A cluster would correspond to a group of people who share similar preferences in movies.
Graph-based similarity
More general than above, similarity between tasks can be defined by a function. The regularizer encourages the model to learn similar functions for similar tasks.
Other uses of regularization in statistics and machine learning
Bayesian learning methods make use of a prior probability that (usually) gives lower probability to more complex models. Well-known model selection techniques include the Akaike information criterion (AIC), minimum description length (MDL), and the Bayesian information criterion (BIC). Alternative methods of controlling overfitting not involving regularization include cross-validation.
Examples of applications of different methods of regularization to the linear model are: