
 | ||
In statistics and machine learning, lasso (least absolute shrinkage and selection operator) (also Lasso or LASSO) is a regression analysis method that performs both variable selection and regularization in order to enhance the prediction accuracy and interpretability of the statistical model it produces. It was introduced by Robert Tibshirani in 1996 based on Leo Breiman’s Nonnegative Garrote. Lasso was originally formulated for least squares models and this simple case reveals a substantial amount about the behavior of the estimator, including its relationship to ridge regression and best subset selection and the connections between lasso coefficient estimates and so-called soft thresholding. It also reveals that (like standard linear regression) the coefficient estimates need not be unique if covariates are collinear.
Contents
- Motivation
- Basic form
- Orthonormal covariates
- Correlated covariates
- General form
- Geometric interpretation
- Bayesian interpretation
- Convex relaxation interpretation
- Generalizations of lasso
- Elastic net
- Group lasso
- Fused lasso
- Quasi norms and bridge regression
- Model fitting
- References
Though originally defined for least squares, lasso regularization is easily extended to a wide variety of statistical models including generalized linear models, generalized estimating equations, proportional hazards models, and M-estimators, in a straightforward fashion. Lasso’s ability to perform subset selection relies on the form of the constraint and has a variety of interpretations including in terms of geometry, Bayesian statistics, and convex analysis.
The LASSO is closely related to basis pursuit denoising.
Motivation
Robert Tibshirani introduced lasso in order to improve the prediction accuracy and interpretability of regression models by altering the model fitting process to select only a subset of the provided covariates for use in the final model rather than using all of them. It is based on Breiman’s Nonnegative Garrote, which has similar goals, but works somewhat differently.
Prior to lasso, the most widely used method for choosing which covariates to include was stepwise selection, which only improves prediction accuracy in certain cases, such as when only a few covariates have a strong relationship with the outcome. However, in other cases, it can make prediction error worse. Also, at the time, ridge regression was the most popular technique for improving prediction accuracy. Ridge regression improves prediction error by shrinking large regression coefficients in order to reduce overfitting, but it does not perform covariate selection and therefore does not help to make the model more interpretable.
Lasso is able to achieve both of these goals by forcing the sum of the absolute value of the regression coefficients to be less than a fixed value, which forces certain coefficients to be set to zero, effectively choosing a simpler model that does not include those coefficients. This idea is similar to ridge regression, in which the sum of the squares of the coefficients is forced to be less than a fixed value, though in the case of ridge regression, this only shrinks the size of the coefficients, it does not set any of them to zero.
Basic form
Lasso was originally introduced in the context of least squares, and it can be instructive to consider this case first, since it illustrates many of lasso’s properties in a straightforward setting.
Consider a sample consisting of N cases, each of which consists of p covariates and a single outcome. Let
Here
where
Since
it is standard to work with centered variables. Additionally, the covariates are typically standardized
It can be helpful to rewrite
in the so-called Lagrangian form
where the exact relationship between
Orthonormal covariates
We can now examine some basic properties of the lasso estimator.
We first assume that the covariates are orthonormal so that
We can compare this to ridge regression, where the objective is to minimize
which yields
So ridge regression shrinks all coefficients by a uniform factor of
We can also compare this to regression with best subset selection, in which the goal is to minimize
where
where
Therefore, the lasso estimates share features of the estimates from both ridge and best subset selection regression since they both shrink the magnitude of all the coefficients, like ridge regression, but also set some of them to zero, as in the best subset selection case. Additionally, while ridge regression scales all of the coefficients by a constant factor, lasso instead translates the coefficients towards zero by a constant value and sets them to zero if they reach it.
Correlated covariates
Returning to the general case, in which the different covariates may not be independent, we consider the special case in which two of the covariates, say j and k, are identical for each case, so that
General form
Lasso regularization can be extended to a wide variety of objective functions such as those for generalized linear models, generalized estimating equations, proportional hazards models, and M-estimators in general, in the obvious way. Given the objective function
the lasso regularized version of the estimator will be the solution to
where only
Geometric interpretation
As discussed above, lasso can set coefficients to zero, while ridge regression, which appears superficially similar, cannot. This is due to the difference in the shape of the constraint boundaries in the two cases. Both lasso and ridge regression can be interpreted as minimizing the same objective function
but with respect to different constraints:
Bayesian interpretation
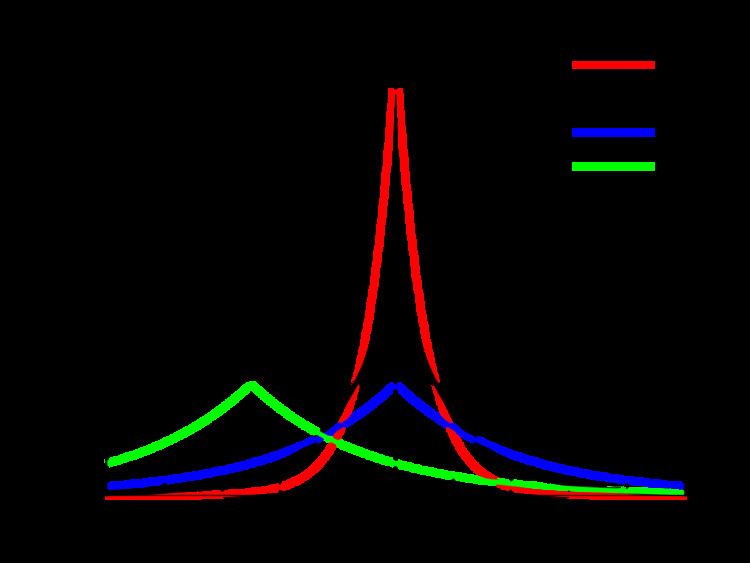
Just as ridge regression can be interpreted as linear regression for which the coefficients have been assigned normal prior distributions, lasso can be interpreted as linear regression for which the coefficients have Laplace prior distributions. The Laplace distribution is sharply peaked at zero (its first derivative is discontinuous) and it concentrates its probability mass closer to zero than does the normal distribution. This provides an alternative explanation of why lasso tends to set some coefficients to zero, while ridge regression does not.
Convex relaxation interpretation
Lasso can also be viewed as a convex relaxation of the best subset selection regression problem, which is to find the subset of
Generalizations of lasso
A number of lasso variants have been created in order to remedy certain limitations of the original technique and to make the method more useful for particular problems. Almost all of these focus on respecting or utilizing different types of dependencies among the covariates. Elastic net regularization adds an additional ridge regression-like penalty which improves performance when the number of predictors is larger than the sample size, allows the method to select strongly correlated variables together, and improves overall prediction accuracy. Group lasso allows groups of related covariates to be selected as a single unit, which can be useful in settings where it does not make sense to include some covariates without others. Further extensions of group lasso to perform variable selection within individual groups (sparse group lasso) and to allow overlap between groups (overlap group lasso) have also been developed. Fused lasso can account for the spatial or temporal characteristics of a problem, resulting in estimates that better match the structure of the system being studied. Lasso regularized models can be fit using a variety of techniques including subgradient methods, least-angle regression (LARS), and proximal gradient methods. Determining the optimal value for the regularization parameter is an important part of ensuring that the model performs well; it is typically chosen using cross-validation.
Elastic net
In 2005, Zou and Hastie introduced the elastic net to address several shortcomings of lasso. When p > n (the number of covariates is greater than the sample size) lasso can select only n covariates (even when more are associated with the outcome) and it tends to select only one covariate from any set of highly correlated covariates. Additionally, even when n > p, if the covariates are strongly correlated, ridge regression tends to perform better.
The elastic net extends lasso by adding an additional
which is equivalent to solving
Somewhat surprisingly, this problem can be written in a simple lasso form
letting
Then
So the result of the elastic net penalty is a combination of the effects of the lasso and Ridge penalties.
Returning to the general case, the fact that the penalty function is now strictly convex means that if
is the sample correlation matrix because the
Therefore, highly correlated covariates will tend to have similar regression coefficients, with the degree of similarity depending on both
Group lasso
In 2006, Yuan and Lin introduced the group lasso in order to allow predefined groups of covariates to be selected into or out of a model together, so that all the members of a particular group are either included or not included. While there are many settings in which this is useful, perhaps the most obvious is when levels of a categorical variable are coded as a collection of binary covariates. In this case, it often doesn't make sense to include only a few levels of the covariate; the group lasso can ensure that all the variables encoding the categorical covariate are either included or excluded from the model together. Another setting in which grouping is natural is in biological studies. Since genes and proteins often lie in known pathways, an investigator may be more interested in which pathways are related to an outcome than whether particular individual genes are. The objective function for the group lasso is a natural generalization of the standard lasso objective
where the design matrix
Fused lasso
In some cases, the object being studied may have important spatial or temporal structure that must be accounted for during analysis, such as time series or image based data. In 2005, Tibshirani and colleagues introduced the Fused lasso to extend the use of lasso to exactly this type of data. The fused lasso objective function is
The first constraint is just the typical lasso constraint, but the second directly penalizes large changes with respect to the temporal or spatial structure, which forces the coefficients to vary in a smooth fashion that reflects the underlying logic of the system being studied. Clustered lasso is a generalization to fused lasso that identifies and groups relevant covariates based on their effects (coefficients). The basic idea is to penalize the differences between the coefficients so that nonzero ones make clusters together. This can be modeled using the following regularization:
In contrast, one can first cluster variables into highly correlated groups, and then extract a single representative covariate from each cluster.
Quasi-norms and bridge regression
Lasso, elastic net, group and fused lasso construct the penalty functions from the
where
It is claimed that the fractional quasi-norms
where
The efficient algorithm for minimization is based on piece-wise quadratic approximation of subquadratic growth (PQSQ).
Model fitting
Though the lasso penalty is not differentiable, a wide variety of techniques from convex analysis and optimization theory have been developed to extremize such functions. These include subgradient methods, Least-Angle Regression (LARS), and proximal gradient methods. Subgradient methods, are the natural generalization of traditional methods such as gradient descent and stochastic gradient descent to the case in which the objective function is not differentiable at all points. LARS is a method that is closely tied to lasso models, and in many cases allows them to be fit very efficiently, though it may not perform well in all circumstances. Proximal methods have become popular because of their flexibility and performance and are an area of active research. The choice of method will depend on the particular lasso variant being used, the data, and the available resources. However, proximal methods will generally perform well in most circumstances.
In addition to fitting the parameters, choosing the regularization parameter is also a fundamental part of using lasso. Selecting it well is essential to the performance of lasso since it controls the strength of shrinkage and variable selection, which, in moderation can improve both prediction and interpretability. However, if the regularization becomes too strong, important variables may be left out of the model and coefficients may be shrunk excessively, which can harm both predictive capacity and the inferences drawn about the system being studied. LARS is unique in this regard as it generates complete regularization paths which makes determining the optimal value of the regularization parameter much more straightforward. With other methods, cross-validation is typically used to select the parameter. Additionally, a variety of heuristics related to choosing the regularization and optimization parameters are often used in order to attempt to improve performance further.