
Data structure Tree, Graph | ||
 | ||
Worst-case performance O ( b d ) {displaystyle O(b^{d})} , where b {displaystyle b} is the branching factor and d {displaystyle d} is the maximum depth Worst-case space complexity O ( d ) {displaystyle O(d)} | ||
In computer science, iterative deepening search or more specifically iterative deepening depth-first search (IDS or IDDFS) is a state space/graph search strategy in which a depth-limited version of depth-first search is run repeatedly with increasing depth limits until the goal is found. IDDFS is equivalent to breadth-first search, but uses much less memory; on each iteration, it visits the nodes in the search tree in the same order as depth-first search, but the cumulative order in which nodes are first visited is effectively breadth-first.
Contents
Algorithm
The following pseudocode shows IDDFS implemented in terms of a recursive depth-limited DFS (called DLS).
function IDDFS(root) for depth from 0 to ∞ found ← DLS(root, depth) if found ≠ null return foundfunction DLS(node, depth) if depth = 0 and node is a goal return node if depth > 0 foreach child of node found ← DLS(child, depth−1) if found ≠ null return found return nullProperties
IDDFS combines depth-first search's space-efficiency and breadth-first search's completeness (when the branching factor is finite). It is optimal when the path cost is a non-decreasing function of the depth of the node.
Since iterative deepening visits states multiple times, it may seem wasteful, but it turns out to be not so costly, since in a tree most of the nodes are in the bottom level, so it does not matter much if the upper levels are visited multiple times.
The main advantage of IDDFS in game tree searching is that the earlier searches tend to improve the commonly used heuristics, such as the killer heuristic and alpha-beta pruning, so that a more accurate estimate of the score of various nodes at the final depth search can occur, and the search completes more quickly since it is done in a better order. For example, alpha-beta pruning is most efficient if it searches the best moves first.
A second advantage is the responsiveness of the algorithm. Because early iterations use small values for
Time complexity
The time complexity of IDDFS in a (well-balanced) tree works out to be the same as depth-first search, i.e.
Proof
In an iterative deepening search, the nodes at depth
where
Now let
This is less than the infinite series
which converges to
That is, we have
Since
Example
For
All together, an iterative deepening search from depth
The higher the branching factor, the lower the overhead of repeatedly expanded states, but even when the branching factor is 2, iterative deepening search only takes about twice as long as a complete breadth-first search. This means that the time complexity of iterative deepening is still
Space complexity
The space complexity of IDDFS is
Proof
Since IDDFS, at any point, is engaged in a depth-first search, it need only store a stack of nodes which represents the branch of the tree it is expanding. Since it finds a solution of optimal length, the maximum depth of this stack is
In general, iterative deepening is the preferred search method when there is a large search space and the depth of the solution is not known.
Example
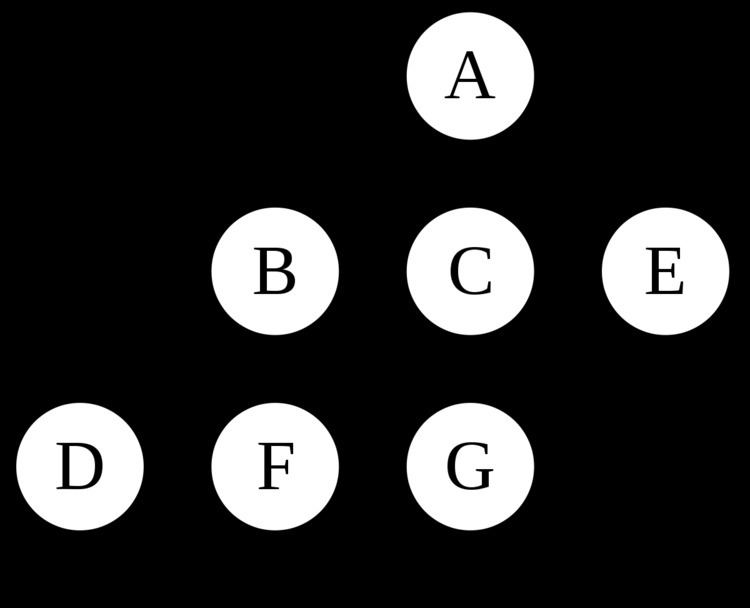
For the following graph:
a depth-first search starting at A, assuming that the left edges in the shown graph are chosen before right edges, and assuming the search remembers previously-visited nodes and will not repeat them (since this is a small graph), will visit the nodes in the following order: A, B, D, F, E, C, G. The edges traversed in this search form a Trémaux tree, a structure with important applications in graph theory.
Performing the same search without remembering previously visited nodes results in visiting nodes in the order A, B, D, F, E, A, B, D, F, E, etc. forever, caught in the A, B, D, F, E cycle and never reaching C or G.
Iterative deepening A*prevents this loop and will reach the following nodes on the following depths, assuming it proceeds left-to-right as above:
(Note that iterative deepening has now seen C, when a conventional depth-first search did not.)
(Note that it still sees C, but that it came later. Also note that it sees E via a different path, and loops back to F twice.)
For this graph, as more depth is added, the two cycles "ABFE" and "AEFB" will simply get longer before the algorithm gives up and tries another branch.
Related algorithms
Similar to iterative deepening is a search strategy called iterative lengthening search that works with increasing path-cost limits instead of depth-limits. It expands nodes in the order of increasing path cost; therefore the first goal it encounters is the one with the cheapest path cost. But iterative lengthening incurs substantial overhead that makes it less useful than iterative deepening.
Iterative deepening A* is a best-first search that performs iterative deepening based on "f"-values similar to the ones computed in the A* algorithm.