
 | ||
In natural language processing, latent Dirichlet allocation (LDA) is a generative statistical model that allows sets of observations to be explained by unobserved groups that explain why some parts of the data are similar. For example, if observations are words collected into documents, it posits that each document is a mixture of a small number of topics and that each word's creation is attributable to one of the document's topics. LDA is an example of a topic model and was first presented as a graphical model for topic discovery by David Blei, Andrew Ng, and Michael I. Jordan in 2003. Essentially the same model was also proposed independently by J. K. Pritchard, M. Stephens, and P. Donnelly in the study of population genetics in 2000. Both papers have been highly influential, with 16488 and 18170 citations respectively by December 2016.
Contents
Topics
In LDA, each document may be viewed as a mixture of various topics where each document is considered to have a set of topics that are assigned to it via LDA. This is similar to probabilistic latent semantic analysis (pLSA), except that in LDA the topic distribution is assumed to have a Dirichlet prior. In practice, this results in more reasonable mixtures of topics in a document. It has been noted, however, that the pLSA model is equivalent to the LDA model under a uniform Dirichlet prior distribution.
For example, an LDA model might have topics that can be classified as CAT_related and DOG_related. A topic has probabilities of generating various words, such as milk, meow, and kitten, which can be classified and interpreted by the viewer as "CAT_related". Naturally, the word cat itself will have high probability given this topic. The DOG_related topic likewise has probabilities of generating each word: puppy, bark, and bone might have high probability. Words without special relevance, such as the (see function word), will have roughly even probability between classes (or can be placed into a separate category). A topic is not strongly defined, neither semantically nor epistemologically. It is identified on the basis of supervised labeling and (manual) pruning on the basis of their likelihood of co-occurrence. A lexical word may occur in several topics with a different probability, however, with a different typical set of neighboring words in each topic.
Each document is assumed to be characterized by a particular set of topics. This is akin to the standard bag of words model assumption, and makes the individual words exchangeable.
Model
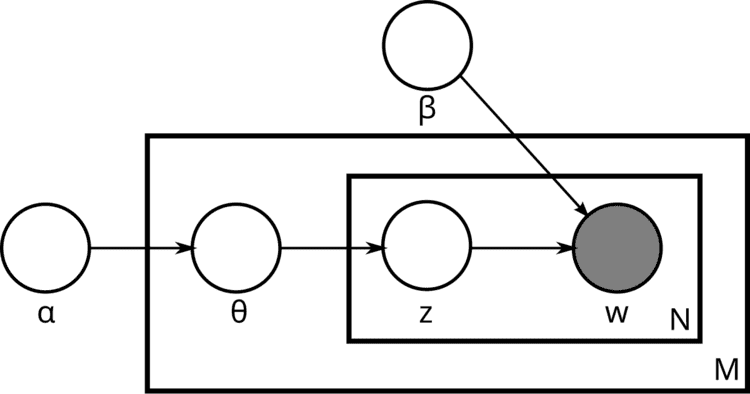
With plate notation, the dependencies among the many variables can be captured concisely. The boxes are “plates” representing replicates. The outer plate represents documents, while the inner plate represents the repeated choice of topics and words within a document. M denotes the number of documents, N the number of words in a document. Thus:
α is the parameter of the Dirichlet prior on the per-document topic distributions,β is the parameter of the Dirichlet prior on the per-topic word distribution,The
Generative Process
The generative process is as follows. Documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words. LDA assumes the following generative process for a corpus
1. Choose
2. Choose
3. For each of the word positions
(Note that the Multinomial distribution here refers to the Multinomial with only one trial. It is formally equivalent to the categorical distribution.)
The lengths
Definition
A formal description of smoothed LDA is as follows:
We can then mathematically describe the random variables as follows:
Inference
Learning the various distributions (the set of topics, their associated word probabilities, the topic of each word, and the particular topic mixture of each document) is a problem of Bayesian inference. The original paper used a variational Bayes approximation of the posterior distribution; alternative inference techniques use Gibbs sampling and expectation propagation.
Following is the derivation of the equations for collapsed Gibbs sampling, which means
According to the model, the total probability of the model is:
where the bold-font variables denote the vector version of the variables. First,
All the
We can further focus on only one
Actually, it is the hidden part of the model for the
Let
So the
Clearly, the equation inside the integration has the same form as the Dirichlet distribution. According to the Dirichlet distribution,
Thus,
Now we turn our attentions to the
For clarity, here we write down the final equation with both
The goal of Gibbs Sampling here is to approximate the distribution of
where
but the ratios among the probabilities that
Finally, let
Note that the same formula is derived in the article on the Dirichlet-multinomial distribution, as part of a more general discussion of integrating Dirichlet distribution priors out of a Bayesian network.
Faster sampling
Recent research has been focused on speeding up the inference of latent Dirichlet Allocation to support capture of a massive number of topics in large number of documents. The update equation of the collapsed Gibbs sampler mentioned in the earlier section has a natural sparsity within it that can be taken advantage of. Intuitively, since each document only contains a subset of topics
In this equation, we have three terms, out of which two of them are sparse, and the other is small. We call these terms
Here, we can see that
Now, while sampling a topic, if we sample a random variable uniformly from
Notice that after sampling each topic, updating these buckets are all basic
Applications, extensions and similar techniques
Topic modeling is a classic problem in information retrieval. Related models and techniques are, among others, latent semantic indexing, independent component analysis, probabilistic latent semantic indexing, non-negative matrix factorization, and Gamma-Poisson distribution.
The LDA model is highly modular and can therefore be easily extended. The main field of interest is modeling relations between topics. This is achieved by using another distribution on the simplex instead of the Dirichlet. The Correlated Topic Model follows this approach, inducing a correlation structure between topics by using the logistic normal distribution instead of the Dirichlet. Another extension is the hierarchical LDA (hLDA), where topics are joined together in a hierarchy by using the nested Chinese restaurant process. LDA can also be extended to a corpus in which a document includes two types of information (e.g., words and names), as in the LDA-dual model. Nonparametric extensions of LDA include the hierarchical Dirichlet process mixture model, which allows the number of topics to be unbounded and learnt from data and the nested Chinese restaurant process which allows topics to be arranged in a hierarchy whose structure is learnt from data.
As noted earlier, pLSA is similar to LDA. The LDA model is essentially the Bayesian version of pLSA model. The Bayesian formulation tends to perform better on small datasets because Bayesian methods can avoid overfitting the data. For very large datasets, the results of the two models tend to converge. One difference is that pLSA uses a variable
Variations on LDA have been used to automatically put natural images into categories, such as "bedroom" or "forest", by treating an image as a document, and small patches of the image as words; one of the variations is called Spatial Latent Dirichlet Allocation.
Recently, LDA has been also applied to bioinformatics context.
LDA is often prone to creating topics that are not easily interpretable by humans. Recent extensions include generating topics from a user-defined seed set of keywords.