
Data structure Array | ||
 | ||
Worst-case performance O ( n log n ) {displaystyle O(nlog n)} Best-case performance O ( n log n ) {displaystyle O(nlog n)} Average performance O ( n log n ) {displaystyle O(nlog n)} Worst-case space complexity O ( 1 ) {displaystyle O(1)} auxiliary | ||
In computer science, heapsort is a comparison-based sorting algorithm. Heapsort can be thought of as an improved selection sort: like that algorithm, it divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element and moving that to the sorted region. The improvement consists of the use of a heap data structure rather than a linear-time search to find the maximum.
Contents
Although somewhat slower in practice on most machines than a well-implemented quicksort, it has the advantage of a more favorable worst-case O(n log n) runtime. Heapsort is an in-place algorithm, but it is not a stable sort.
Heapsort was invented by J. W. J. Williams in 1964. This was also the birth of the heap, presented already by Williams as a useful data structure in its own right. In the same year, R. W. Floyd published an improved version that could sort an array in-place, continuing his earlier research into the treesort algorithm.
Overview
The heapsort algorithm can be divided into two parts.
In the first step, a heap is built out of the data. The heap is often placed in an array with the layout of a complete binary tree. The complete binary tree maps the binary tree structure into the array indices; each array index represents a node; the index of the node's parent, left child branch, or right child branch are simple expressions. For a zero-based array, the root node is stored at index 0; if i is the index of the current node, then
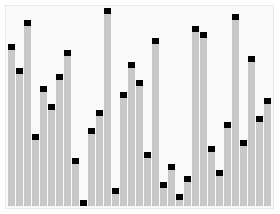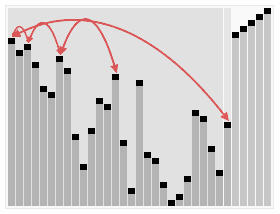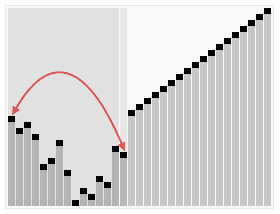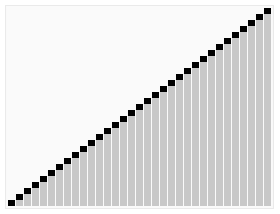
In the second step, a sorted array is created by repeatedly removing the largest element from the heap (the root of the heap), and inserting it into the array. The heap is updated after each removal to maintain the heap. Once all objects have been removed from the heap, the result is a sorted array.
Heapsort can be performed in place. The array can be split into two parts, the sorted array and the heap. The storage of heaps as arrays is diagrammed here. The heap's invariant is preserved after each extraction, so the only cost is that of extraction.
Algorithm
The heapsort algorithm involves preparing the list by first turning it into a max heap. The algorithm then repeatedly swaps the first value of the list with the last value, decreasing the range of values considered in the heap operation by one, and sifting the new first value into its position in the heap. This repeats until the range of considered values is one value in length.
The steps are:
- Call the buildMaxHeap() function on the list. Also referred to as heapify(), this builds a heap from a list in O(n) operations.
- Swap the first element of the list with the final element. Decrease the considered range of the list by one.
- Call the siftDown() function on the list to sift the new first element to its appropriate index in the heap.
- Go to step (2) unless the considered range of the list is one element.
The buildMaxHeap() operation is run once, and is O(n) in performance. The siftDown() function is O(log(n)), and is called n times. Therefore, the performance of this algorithm is O(n + n * log(n)) which evaluates to O(n log n).
Pseudocode
The following is a simple way to implement the algorithm in pseudocode. Arrays are zero-based and swap is used to exchange two elements of the array. Movement 'down' means from the root towards the leaves, or from lower indices to higher. Note that during the sort, the largest element is at the root of the heap at a[0], while at the end of the sort, the largest element is in a[end].
The sorting routine uses two subroutines, heapify and siftDown. The former is the common in-place heap construction routine, while the latter is a common subroutine for implementing heapify.
The heapify procedure can be thought of as building a heap from the bottom up by successively sifting downward to establish the heap property. An alternative version (shown below) that builds the heap top-down and sifts upward may be simpler to understand. This siftUp version can be visualized as starting with an empty heap and successively inserting elements, whereas the siftDown version given above treats the entire input array as a full but "broken" heap and "repairs" it starting from the last non-trivial sub-heap (that is, the last parent node).
Also, the siftDown version of heapify has O(n) time complexity, while the siftUp version given below has O(n log n) time complexity due to its equivalence with inserting each element, one at a time, into an empty heap. This may seem counter-intuitive since, at a glance, it is apparent that the former only makes half as many calls to its logarithmic-time sifting function as the latter; i.e., they seem to differ only by a constant factor, which never affects asymptotic analysis.
To grasp the intuition behind this difference in complexity, note that the number of swaps that may occur during any one siftUp call increases with the depth of the node on which the call is made. The crux is that there are many (exponentially many) more "deep" nodes than there are "shallow" nodes in a heap, so that siftUp may have its full logarithmic running-time on the approximately linear number of calls made on the nodes at or near the "bottom" of the heap. On the other hand, the number of swaps that may occur during any one siftDown call decreases as the depth of the node on which the call is made increases. Thus, when the siftDown heapify begins and is calling siftDown on the bottom and most numerous node-layers, each sifting call will incur, at most, a number of swaps equal to the "height" (from the bottom of the heap) of the node on which the sifting call is made. In other words, about half the calls to siftDown will have at most only one swap, then about a quarter of the calls will have at most two swaps, etc.
The heapsort algorithm itself has O(n log n) time complexity using either version of heapify.
procedure heapify(a,count) is (end is assigned the index of the first (left) child of the root) end := 1 while end < count (sift up the node at index end to the proper place such that all nodes above the end index are in heap order) siftUp(a, 0, end) end := end + 1 (after sifting up the last node all nodes are in heap order) procedure siftUp(a, start, end) is input: start represents the limit of how far up the heap to sift. end is the node to sift up. child := end while child > start parent := iParent(child) if a[parent] < a[child] then (out of max-heap order) swap(a[parent], a[child]) child := parent (repeat to continue sifting up the parent now) else returnVariations
Bottom-up heapsort
Bottom-up heapsort was announced as beating quicksort (with median-of-three pivot selection) on arrays of size ≥16000. This version of heapsort keeps the linear-time heap-building phase, but changes the second phase, as follows.
Ordinary heapsort extracts the top of the heap, a[0], and fills the gap it leaves with a[end], then sifts this latter element down the heap; but this element comes from the lowest level of the heap, meaning it is one of the smallest elements in the heap, so the sift-down will likely take many steps to move it back down. Each step of the sift-down requires two comparisons, to find the minimum of the new node and its two children.
Bottom-up heapsort instead finds the path of largest children to the leaf level of the tree (as if it were inserting −∞) using only one comparison per level. Put another way, it finds the leaf which has the property that it and all of its ancestors are greater than their siblings. (In the absence of equal keys, this leaf is unique.) Then, from this leaf, it searches upward (using one comparison per level) for the correct position in that path to insert a[end]. This is the same location as ordinary heapsort finds, and requires the same number of exchanges to perform the insert, but fewer comparisons are required to find that location.
function leafSearch(a, i, end) is j ← i while iLeftChild(j) ≤ end do (Determine which of j's children is the greater) if iRightChild(j) ≤ end and a[iRightChild(j)] > a[iLeftChild(j)] then j ← iRightChild(j) else j ← iLeftChild(j) return jThe return value of the leafSearch is used in the modified siftDown routine:
Bottom-up heapsort requires only 1.5 n log2 n + O(n) comparisons in the worst case and n log2 n + O(1) on average. For comparison, ordinary heapsort requires 2 n log2 n + O(n) comparisons worst-case and on average.
A 2008 re-evaluation of this algorithm showed it to be no faster than ordinary heapsort for integer keys, though, presumably because modern branch prediction nullifies the cost of the predictable comparisons which bottom-up heapsort manages to avoid. (It still has an advantage if comparisons are expensive.)
A further refinement does a binary search in the path to the selected leaf, and sorts in a worst case of (n+1)(log2(n+1) + log2 log2(n+1) + 1.82) + O(log2 n) comparisons, approaching the information-theoretic lower bound of n log2 n − 1.44 n comparisons.
A variant which uses two extra bits per internal node (n−1 bits total for an n-element heap) to cache information about which child is greater (two bits are required to store three cases: left, right, and unknown) uses less than n log2 n + 1.1 n compares.
Comparison with other sorts
Heapsort primarily competes with quicksort, another very efficient general purpose nearly-in-place comparison-based sort algorithm.
Quicksort is typically somewhat faster due to some factors, but the worst-case running time for quicksort is O(n2), which is unacceptable for large data sets and can be deliberately triggered given enough knowledge of the implementation, creating a security risk. See quicksort for a detailed discussion of this problem and possible solutions.
Thus, because of the O(n log n) upper bound on heapsort's running time and constant upper bound on its auxiliary storage, embedded systems with real-time constraints or systems concerned with security often use heapsort, such as the Linux kernel.
Heapsort also competes with merge sort, which has the same time bounds. Merge sort requires Ω(n) auxiliary space, but heapsort requires only a constant amount. Heapsort typically runs faster in practice on machines with small or slow data caches, and does not require as much external memory. On the other hand, merge sort has several advantages over heapsort:
Introsort is an alternative to heapsort that combines quicksort and heapsort to retain advantages of both: worst case speed of heapsort and average speed of quicksort.
Example
Let { 6, 5, 3, 1, 8, 7, 2, 4 } be the list that we want to sort from the smallest to the largest. (NOTE, for 'Building the Heap' step: Larger nodes don't stay below smaller node parents. They are swapped with parents, and then recursively checked if another swap is needed, to keep larger numbers above smaller numbers on the heap binary tree.)
1. Build the heap
2. Sorting.