
Worst-case performance O(n log n) Average performance O(n log n) | Data structure Array Best-case performance O(n) | |
 | ||
Worst-case space complexity O(n) total, O(1) auxiliary | ||
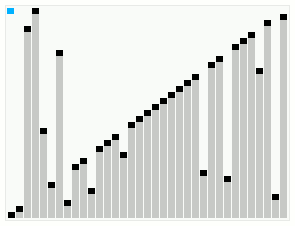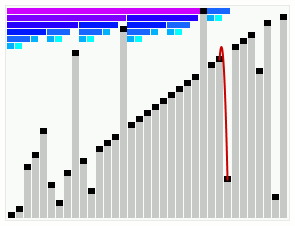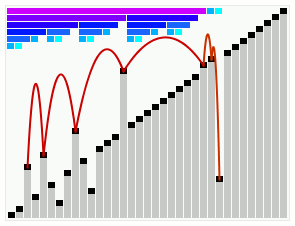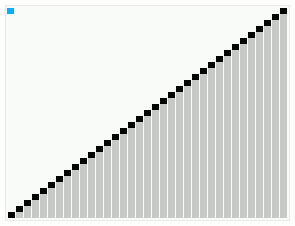
In computer science, smoothsort is a comparison-based sorting algorithm. A variant of heapsort, it was invented and published by Edsger Dijkstra in 1981. Like heapsort, smoothsort is an in-place algorithm with an upper bound of O(n log n), but it is not a stable sort. The advantage of smoothsort is that it comes closer to O(n) time if the input is already sorted to some degree, whereas heapsort averages O(n log n) regardless of the initial sorted state.
Contents
Overview
Like heapsort, smoothsort builds up an implicit heap data structure in the array to be sorted, then sorts the array by repeatedly extracting the maximum element from that heap. Unlike heapsort, which places the root of the heap and largest element at the beginning (left) of the array before swapping it to the end (right), smoothsort places the root of the heap at the right, already in its final location. This, however, considerably complicates the algorithm for removing the rightmost element.
Dijkstra's formulation of smoothsort does not use a binary heap, but rather a custom heap based on the Leonardo numbers. As he pointed out in his original paper, it is also possible to use perfect binary trees (of size 2k−1) with the same asymptotic efficiency, but there is a constant factor lost in efficiency due to the greater number of trees required by the larger spacing of permissible sizes.
The Leonardo numbers are similar to the Fibonacci numbers, and defined as:
A Leonardo tree of order k ≥ 2 is a binary tree with a root element, and two children which are themselves Leonardo trees, of orders k−1 and k−2. A Leonardo heap resembles a Fibonacci heap in that it is made up of a collection of heap-ordered Leonardo trees.
Each tree is an implicit binary tree of size L(k), and the heap consists of a list of trees of decreasing size and increasing root elements. Ordered left-to-right, the rightmost tree is the smallest and its root element is the global maximum.
The advantage of this custom heap over a single binary heap is that if the input is already sorted, it can be constructed and deconstructed in O(n) time without moving any data, hence the better runtime.
Breaking the input up into a list of trees is simple – the leftmost nodes of the array are made into the largest tree possible, and the remainder is likewise divided up. The list is constructed to maintain the following size properties (it can be proven that this is always possible):
(In the perfect binary tree variant of smoothsort, the equivalent invariant is that no two trees have the same size, except possibly the last two. This is the skew binary number system.)
An implicit Leonardo tree of order k and size L(k) is either a single node (for orders 0 and 1), or a left subtree of size L(k − 1), followed by a right subtree of size L(k − 2), followed by a root node. Each tree maintains the max-heap property that each node is always at least as large as either of its children (and thus the root of the tree is the largest element of all). The list of trees as a whole maintains the order property that the root node of each tree is at least as large as the root node of its predecessor (to the left).
The consequence of this is that the root of the last (rightmost) tree in the list will always be the largest of the nodes, and, importantly, an array that is already sorted needs no rearrangement to be made into a valid Leonardo heap. This is the source of the adaptive qualities of the algorithm.
Like heapsort, the algorithm consists of two phases. In the first, the heap is grown by repeatedly adding the next unsorted element, and performing rearrangements to restore the heap properties.
In phase two, the root of the last tree in the list will be the largest element in the heap, and will therefore be in its correct, final position. We then reduce the series of heaps back down by removing the rightmost node (which stays in place) and performing re-arrangements to restore the heap invariants. When we are back down to a single heap of one element, the array is sorted.
Operations
Ignoring (for the moment) Dijkstra's optimisations, two operations are necessary: enlarge the heap by adding one element to the right, and shrink the heap by removing the right most element (the root of the last heap), preserving the three types of invariant properties:
- The heap property within each tree,
- The order property, keeping the root elements of the trees in order, and
- The size properties relating the sizes of the various trees.
Grow the heap by adding an element to the right
Enlarging the heap while maintaining the size properties can be done without any data motion at all by just rearranging the boundaries of the component trees:
After this, the newly added element must be moved to the correct location to maintain the heap and order properties. Because there are O(log n) trees, each of depth O(log n), it is simple to do this in O(log n) time, as follows:
- First, restore the order property by moving the new element left until it is at the root of the correct tree:
- Begin with the rightmost tree (the one that has just been created) as the "current" tree.
- While there is a tree to the left of the current tree and its root is greater than the new element (the current root) and both of its children,
- swap the new element with the root of the tree to the left. This preserves the heap property of the current tree. The tree on the left then becomes the current tree, and we repeat this step.
- Second, restore the heap property to the current tree by "sifting down" the new element to its correct position. (This is a standard heap operation, as used in heapsort.)
- While the current tree has a size greater than 1 and either child of is greater than the current root, then
- Swap the greater child root with the current root. That child tree becomes the current tree and sift-down continues.
The sift-down operation is slightly simpler than in binary heaps, because each node has either two children or zero. One does not need to handle the condition of one of the child heaps not being present.
Optimisation
There are two opportunities to omit some operations during heap construction:
Shrink the heap by removing the rightmost element
This is the reverse of the grow process:
Optimisation
Analysis
Smoothsort takes O(n) time to process a presorted array and O(n log n) in the worst case, and achieves nearly-linear performance on many nearly-sorted inputs. However, it does not handle all nearly-sorted sequences optimally. Using the count of inversions as a measure of un-sortedness (the number of pairs of indices i and j with i < j and A[i] > A[j]; for randomly sorted input this is approximately n2/4), there are possible input sequences with O(n log n) inversions which cause it to take Ω(n log n) time, whereas other adaptive sorting algorithms can solve these cases in O(n log log n) time.
The smoothsort algorithm needs to be able to hold in memory the sizes of all of the trees in the Leonardo heap. Since they are sorted by order and all orders are distinct, this is usually done using a bit vector indicating which orders are present. Moreover, since the largest order is at most O(log n), these bits can be encoded in O(1) machine words, assuming a transdichotomous machine model.
Note that O(1) machine words is not the same thing as one machine word. A 32-bit vector would only suffice for sizes less than L(32) = 7049155. A 64-bit vector will do for sizes less than L(64) = 34335360355129 ≈ 245. In general, it takes 1/log2(φ) ≈ 1.44 bits of vector per bit of size.