Possible features to which an energy can be assigned include torsion angles (such as the ϕ , ψ angles of the Ramachandran plot), solvent exposure or hydrogen bond geometry. The classic application of such potentials is however pairwise amino acid contacts or distances. For pairwise amino acid contacts, a statistical potential is formulated as an interaction matrix that assigns a weight or energy value to each possible pair of standard amino acids. The energy of a particular structural model is then the combined energy of all pairwise contacts (defined as two amino acids within a certain distance of each other) in the structure. The energies are determined using statistics on amino acid contacts in a database of known protein structures (obtained from the Protein Data Bank).
Many textbooks present the potentials of mean force (PMFs) as proposed by Sippl as a simple consequence of the Boltzmann distribution, as applied to pairwise distances between amino acids. This is incorrect, but a useful start to introduce the construction of the potential in practice. The Boltzmann distribution applied to a specific pair of amino acids, is given by:
P ( r ) = 1 Z e − F ( r ) k T where r is the distance, k is the Boltzmann constant, T is the temperature and Z is the partition function, with
Z = ∫ e − F ( r ) k T d r The quantity F ( r ) is the free energy assigned to the pairwise system. Simple rearrangement results in the inverse Boltzmann formula, which expresses the free energy F ( r ) as a function of P ( r ) :
F ( r ) = − k T ln P ( r ) − k T ln Z To construct a PMF, one then introduces a so-called reference state with a corresponding distribution Q R and partition function Z R , and calculates the following free energy difference:
Δ F ( r ) = − k T ln P ( r ) Q R ( r ) − k T ln Z Z R The reference state typically results from a hypothetical system in which the specific interactions between the amino acids are absent. The second term involving Z and Z R can be ignored, as it is a constant.
In practice, P ( r ) is estimated from the database of known protein structures, while Q R ( r ) typically results from calculations or simulations. For example, P ( r ) could be the conditional probability of finding the C β atoms of a valine and a serine at a given distance r from each other, giving rise to the free energy difference Δ F . The total free energy difference of a protein, Δ F T , is then claimed to be the sum of all the pairwise free energies:
Δ F T = ∑ i < j Δ F ( r i j ∣ a i , a j ) = − k T ∑ i < j ln P ( r i j ∣ a i , a j ) Q R ( r i j ∣ a i , a j ) where the sum runs over all amino acid pairs a i , a j (with i < j ) and r i j is their corresponding distance. It should be noted that in many studies Q R does not depend on the amino acid sequence.
Intuitively, it is clear that a low value for Δ F T indicates that the set of distances in a structure is more likely in proteins than in the reference state. However, the physical meaning of these PMFs have been widely disputed since their introduction. The main issues are the interpretation of this "potential" as a true, physically valid potential of mean force, the nature of the reference state and its optimal formulation, and the validity of generalizations beyond pairwise distances.
The first, qualitative justification of PMFs is due to Sippl, and based on an analogy with the statistical physics of liquids. For liquids, the potential of mean force is related to the radial distribution function g ( r ) , which is given by:
g ( r ) = P ( r ) Q R ( r ) where P ( r ) and Q R ( r ) are the respective probabilities of finding two particles at a distance r from each other in the liquid and in the reference state. For liquids, the reference state is clearly defined; it corresponds to the ideal gas, consisting of non-interacting particles. The two-particle potential of mean force W ( r ) is related to g ( r ) by:
W ( r ) = − k T log g ( r ) = − k T log P ( r ) Q R ( r ) According to the reversible work theorem, the two-particle potential of mean force W ( r ) is the reversible work required to bring two particles in the liquid from infinite separation to a distance r from each other.
Sippl justified the use of PMFs - a few years after he introduced them for use in protein structure prediction - by appealing to the analogy with the reversible work theorem for liquids. For liquids, g ( r ) can be experimentally measured using small angle X-ray scattering; for proteins, P ( r ) is obtained from the set of known protein structures, as explained in the previous section. However, as Ben-Naim writes in a publication on the subject:
[...]the quantities, referred to as `statistical potentials,' `structure based potentials,' or `pair potentials of mean force', as derived from the protein data bank, are neither `potentials' nor `potentials of mean force,' in the ordinary sense as used in the literature on liquids and solutions.
Another issue is that the analogy does not specify a suitable reference state for proteins.
Baker and co-workers justified PMFs from a Bayesian point of view and used these insights in the construction of the coarse grained ROSETTA energy function. According to Bayesian probability calculus, the conditional probability P ( X ∣ A ) of a structure X , given the amino acid sequence A , can be written as:
P ( X ∣ A ) = P ( A ∣ X ) P ( X ) P ( A ) ∝ P ( A ∣ X ) P ( X ) P ( X ∣ A ) is proportional to the product of the likelihood P ( A ∣ X ) times the prior P ( X ) . By assuming that the likelihood can be approximated as a product of pairwise probabilities, and applying Bayes' theorem, the likelihood can be written as:
P ( A ∣ X ) ≈ ∏ i < j P ( a i , a j ∣ r i j ) ∝ ∏ i < j P ( r i j ∣ a i , a j ) P ( r i j ) where the product runs over all amino acid pairs a i , a j (with i < j ), and r i j is the distance between amino acids i and j . Obviously, the negative of the logarithm of the expression has the same functional form as the classic pairwise distance PMFs, with the denominator playing the role of the reference state. This explanation has two shortcomings: it is purely qualitative, and relies on the unfounded assumption the likelihood can be expressed as a product of pairwise probabilities.
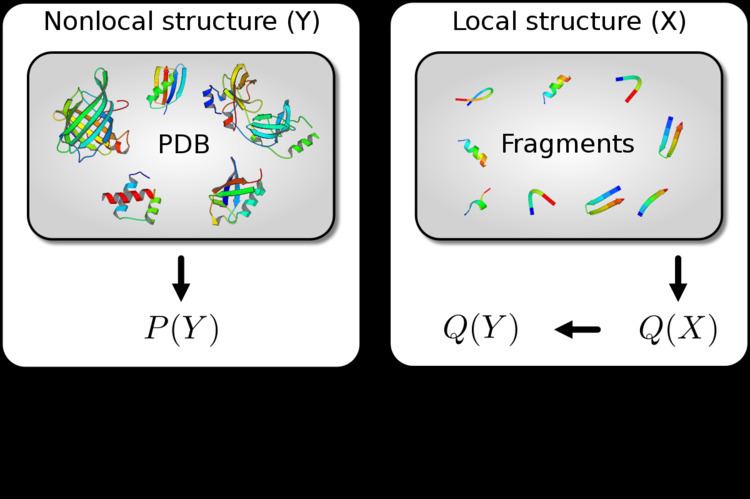
Expressions that resemble PMFs naturally result from the application of probability theory to solve a fundamental problem that arises in protein structure prediction: how to improve an imperfect probability distribution Q ( X ) over a first variable X using a probability distribution P ( Y ) over a second variable Y , with Y = f ( X ) . Typically, X and Y are fine and coarse grained variables, respectively. For example, Q ( X ) could concern the local structure of the protein, while P ( Y ) could concern the pairwise distances between the amino acids. In that case, X could for example be a vector of dihedral angles that specifies all atom positions (assuming ideal bond lengths and angles). In order to combine the two distributions, such that the local structure will be distributed according to Q ( X ) , while the pairwise distances will be distributed according to P ( Y ) , the following expression is needed:
P ( X , Y ) = P ( Y ) Q ( Y ) Q ( X ) where Q ( Y ) is the distribution over Y implied by Q ( X ) . The ratio in the expression corresponds to the PMF. Typically, Q ( X ) is brought in by sampling (typically from a fragment library), and not explicitly evaluated; the ratio, which in contrast is explicitly evaluated, corresponds to Sippl's potential of mean force. This explanation is quantitive, and allows the generalization of PMFs from pairwise distances to arbitrary coarse grained variables. It also provides a rigorous definition of the reference state, which is implied by Q ( X ) . Conventional applications of pairwise distance PMFs usually lack two necessary features to make them fully rigorous: the use of a proper probability distribution over pairwise distances in proteins, and the recognition that the reference state is rigorously defined by Q ( X ) .
Statistical potentials are used as energy functions in the assessment of an ensemble of structural models produced by homology modeling or protein threading - predictions for the tertiary structure assumed by a particular amino acid sequence made on the basis of comparisons to one or more homologous proteins with known structure. Many differently parameterized statistical potentials have been shown to successfully identify the native state structure from an ensemble of "decoy" or non-native structures. Statistical potentials are not only used for protein structure prediction, but also for modelling the protein folding pathway.