
 | ||
A race condition or race hazard is the behavior of an electronic, software, or other system where the output is dependent on the sequence or timing of other uncontrollable events. It becomes a bug when events do not happen in the order the programmer intended. The term originates with the idea of two signals racing each other to influence the output first.
Contents
- Electronics
- Critical and non critical forms
- Static dynamic and essential forms
- Software
- Example
- File systems
- Networking
- Life critical systems
- Computer security
- Biology
- Tools
- References
Race conditions can occur in electronics systems, especially logic circuits, and in computer software, especially multithreaded or distributed programs.
Electronics
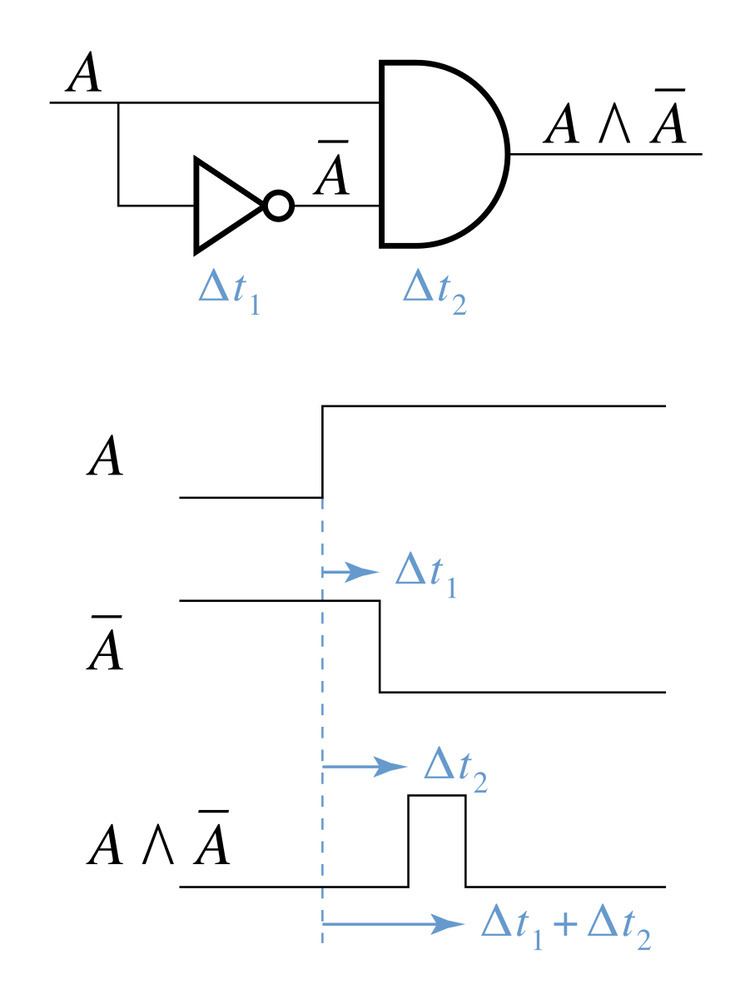
A typical example of a race condition may occur in a system of logic gates where inputs vary. If a given output depends on the state of the inputs it may only be defined for steady-state signals. As the inputs change state a small delay will occur before the output changes due to the physical nature of the electronic system. The output may, for a brief period, change to an unwanted state before settling back to the designed state. Certain systems can tolerate such glitches but if this output functions as a clock signal for further systems that contain memory, for example, the system can rapidly depart from its designed behaviour (in effect, the temporary glitch becomes a permanent glitch).
Consider, for example, a two-input AND gate fed with a logic signal A on one input and its negation, NOT A, on another input. In theory the output (A AND NOT A) should never be true. If, however, changes in the value of A take longer to propagate to the second input than the first when A changes from false to true then a brief period will ensue during which both inputs are true, and so the gate's output will also be true.
Design techniques such as Karnaugh maps encourage designers to recognize and eliminate race conditions before they cause problems. Often logic redundancy can be added to eliminate some kinds of races.
As well as these problems, some logic elements can enter metastable states, which create further problems for circuit designers.
Critical and non-critical forms
A critical race condition occurs when the order in which internal variables are changed determines the eventual state that the state machine will end up in.
A non-critical race condition occurs when the order in which internal variables are changed does not determine the eventual state that the state machine will end up in.
Static, dynamic, and essential forms
A static race condition occurs when a signal and its complement are combined together.
A dynamic race condition occurs when it results in multiple transitions when only one is intended. They are due to interaction between gates. It can be eliminated by using no more than two levels of gating.
An essential race condition occurs when an input has two transitions in less than the total feedback propagation time. Sometimes they are cured using inductive delay line elements to effectively increase the time duration of an input signal.
Software
Race conditions arise in software when an application depends on the sequence or timing of processes or threads for it to operate properly. As with electronics, there are critical race conditions that result in invalid execution and bugs as well as non-critical race conditions that result in unanticipated behavior. Critical race conditions often happen when the processes or threads depend on some shared state. Operations upon shared states are critical sections that must be mutually exclusive. Failure to obey this rule opens up the possibility of corrupting the shared state.
The memory model defined in the C11 and C++11 standards uses the term "data race" for a critical race condition caused by concurrent reads and writes of a shared memory location. A C or C++ program containing a data race has undefined behavior.
Race conditions have a reputation of being difficult to reproduce and debug, since the end result is nondeterministic and depends on the relative timing between interfering threads. Problems occurring in production systems can therefore disappear when running in debug mode, when additional logging is added, or when attaching a debugger, often referred to as a "Heisenbug". It is therefore better to avoid race conditions by careful software design rather than attempting to fix them afterwards.
Example
As a simple example, let us assume that two threads want to increment the value of a global integer variable by one. Ideally, the following sequence of operations would take place:
In the case shown above, the final value is 2, as expected. However, if the two threads run simultaneously without locking or synchronization, the outcome of the operation could be wrong. The alternative sequence of operations below demonstrates this scenario:
In this case, the final value is 1 instead of the expected result of 2. This occurs because here the increment operations are not mutually exclusive. Mutually exclusive operations are those that cannot be interrupted while accessing some resource such as a memory location.
File systems
In file systems, two or more programs may collide in their attempts to modify or access a file, which could result in data corruption. File locking provides a commonly used solution. A more cumbersome remedy involves organizing the system in such a way that one unique process (running a daemon or the like) has exclusive access to the file, and all other processes that need to access the data in that file do so only via interprocess communication with that one process.This requires synchronization at the process level.
A different form of race condition exists in file systems where unrelated programs may affect each other by suddenly using up available resources such as disk space, memory space, or processor cycles. Software not carefully designed to anticipate and handle this race situation may then become unpredictable. Such a risk may be overlooked for a long time in a system that seems very reliable. But eventually enough data may accumulate or enough other software may be added to critically destabilize many parts of a system. An example of this occurred with the near loss of the Mars Rover "Spirit" not long after landing. A solution is for software to request and reserve all the resources it will need before beginning a task; if this request fails then the task is postponed, avoiding the many points where failure could have occurred. Alternatively, each of those points can be equipped with error handling, or the success of the entire task can be verified afterwards, before continuing. A more common approach is to simply verify that enough system resources are available before starting a task; however, this may not be adequate because in complex systems the actions of other running programs can be unpredictable.
Networking
In networking, consider a distributed chat network like IRC, where a user who starts a channel automatically acquires channel-operator privileges. If two users on different servers, on different ends of the same network, try to start the same-named channel at the same time, each user's respective server will grant channel-operator privileges to each user, since neither server will yet have received the other server's signal that it has allocated that channel. (This problem has been largely solved by various IRC server implementations.)
In this case of a race condition, the concept of the "shared resource" covers the state of the network (what channels exist, as well as what users started them and therefore have what privileges), which each server can freely change as long as it signals the other servers on the network about the changes so that they can update their conception of the state of the network. However, the latency across the network makes possible the kind of race condition described. In this case, heading off race conditions by imposing a form of control over access to the shared resource—say, appointing one server to control who holds what privileges—would mean turning the distributed network into a centralized one (at least for that one part of the network operation).
Race conditions can also exist when a computer program is written with non-blocking sockets, in which case the performance of the program can be dependent on the speed of the network link.
Life-critical systems
Software flaws in life-critical systems can be disastrous. Race conditions were among the flaws in the Therac-25 radiation therapy machine, which led to the death of at least three patients and injuries to several more.
Another example is the Energy Management System provided by GE Energy and used by Ohio-based FirstEnergy Corp (among other power facilities). A race condition existed in the alarm subsystem; when three sagging power lines were tripped simultaneously, the condition prevented alerts from being raised to the monitoring technicians, delaying their awareness of the problem. This software flaw eventually led to the North American Blackout of 2003. GE Energy later developed a software patch to correct the previously undiscovered error.
Computer security
A specific kind of race condition involves checking for a predicate (e.g. for authentication), then acting on the predicate, while the state can change between the time of check and the time of use. When this kind of bug exists in security-conscious code, a security vulnerability called a time-of-check-to-time-of-use (TOCTTOU) bug is created.
Biology
Neuroscience is demonstrating that race conditions can occur in mammal (rat) brains as well.
Tools
Many software tools exist to help detect race conditions in software. They can be largely categorized into two groups: static analysis tools and dynamic analysis tools.
Thread Safety Analysis is a static analysis tool for annotation-based intra-procedural static analysis, originally implemented as a branch of gcc, and now reimplemented in Clang, supporting PThreads.
Dynamic analysis tools include: Intel Inspector, a memory and thread checking and debugging tool to increase the reliability, security, and accuracy of C/C++ and Fortran applications; Intel Advisor, a sampling based, SIMD vectorization optimization and shared memory threading assistance tool for C, C++, C#, and Fortran software developers and architects; ThreadSanitizer, which uses binary (Valgrind-based) or source, LLVM-based instrumentation, and supports PThreads); and Helgrind, a Valgrind tool for detecting synchronisation errors in C, C++, and Fortran programs that use the POSIX pthreads threading primitives.