
 | ||
The mathematical theory of information is based on probability theory and statistics, and measures information with several quantities of information. The choice of logarithmic base in the following formulae determines the unit of information entropy that is used. The most common unit of information is the bit, based on the binary logarithm. Other units include the nat, based on the natural logarithm, and the hartley, based on the base 10 or common logarithm.
Contents
In what follows, an expression of the form
Self-information
Shannon derived a measure of information content called the self-information or "surprisal" of a message m:
where
Information is transferred from a source to a recipient only if the recipient of the information did not already have the information to begin with. Messages that convey information that is certain to happen and already known by the recipient contain no real information. Infrequently occurring messages contain more information than more frequently occurring messages. This fact is reflected in the above equation - a certain message, i.e. of probability 1, has an information measure of zero. In addition, a compound message of two (or more) unrelated (or mutually independent) messages would have a quantity of information that is the sum of the measures of information of each message individually. That fact is also reflected in the above equation, supporting the validity of its derivation.
An example: The weather forecast broadcast is: "Tonight's forecast: Dark. Continued darkness until widely scattered light in the morning." This message contains almost no information. However, a forecast of a snowstorm would certainly contain information since such does not happen every evening. There would be an even greater amount of information in an accurate forecast of snow for a warm location, such as Miami. The amount of information in a forecast of snow for a location where it never snows (impossible event) is the highest (infinity).
Entropy
The entropy of a discrete message space
where
An important property of entropy is that it is maximized when all the messages in the message space are equiprobable (e.g.
Sometimes the function H is expressed in terms of the probabilities of the distribution:
An important special case of this is the binary entropy function:
Joint entropy
The joint entropy of two discrete random variables
If
(Note: The joint entropy should not be confused with the cross entropy, despite similar notations.)
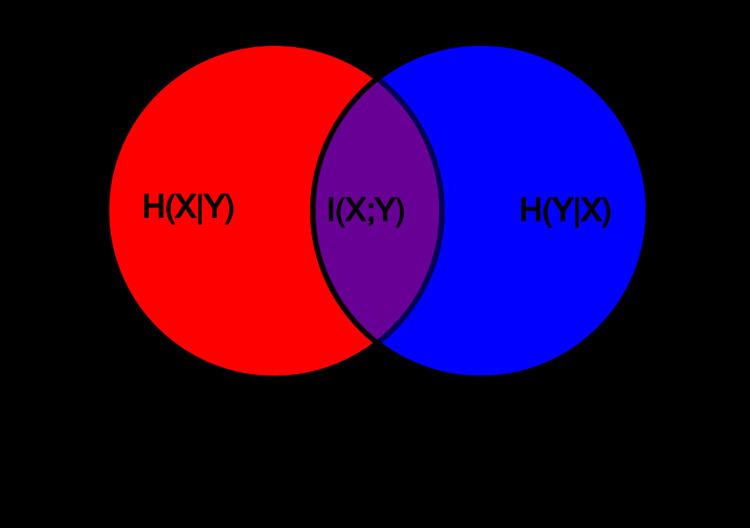
Conditional entropy (equivocation)
Given a particular value of a random variable
where
The conditional entropy of
A basic property of the conditional entropy is that: