
 | ||
The generalized distributive law (GDL) is a generalization of the distributive property which gives rise to a general message passing algorithm. It is a synthesis of the work of many authors in the information theory, digital communications, signal processing, statistics, and artificial intelligence communities. The law and algorithm were introduced in a semi-tutorial by Srinivas M. Aji and Robert J. McEliece with the same title.
Contents
Introduction
"The distributive law in mathematics is the law relating the operations of multiplication and addition, stated symbolically,
As it can be observed from the definition, application of distributive law to an arithmetic expression reduces the number of operations in it. In the previous example the total number of operations reduced from three (two multiplications and an addition in
This is explained in a more formal way in the example below:
Here we are "marginalizing out" the independent variables (
If we apply the distributive law to the RHS of the equation, we get the following:
This implies that
Now, when we are calculating the computational complexity, we can see that there are
History
Some of the problems that used distributive law to solve can be grouped as follows
1. Decoding algorithms
A GDL like algorithm was used by Gallager's for decoding low density parity-check codes. Based on Gallager's work Tanner introduced the Tanner graph and expressed Gallagers work in message passing form. The tanners graph also helped explain the Viterbi algorithm.
It is observed by Forney that Viterbi's maximum likelihood decoding of convolutional codes also used algorithms of GDL-like generality.
2. Forward-backward algorithm
The forward backward algorithm helped as an algorithm for tracking the states in the markov chain. And this also was used the algorithm of GDL like generality
3. Artificial intelligence
The notion of junction trees has been used to solve many problems in AI. Also the concept of bucket elimination used many of the concepts.
The MPF problem
MPF or marginalize a product function is a general computational problem which as special case includes many classical problems such as computation of discrete Hadamard transform, maximum likelihood decoding of a linear code over a memory-less channel, and matrix chain multiplication. The power of the GDL lies in the fact that it applies to situations in which additions and multiplications are generalized. A commutative semiring is a good framework for explaining this behavior. It is defined over a set
Let
Let
Now the global kernel
Definition of MPF problem: For one or more indices
Here
The following is an example of the MPF problem. Let
Here local domains and local kernels are defined as follows:
where
Let us consider another example where
Now since the global kernel is defined as the product of the local kernels, it is
and the objective function at the local domain
This is the Hadamard transform of the function
GDL: an algorithm for solving the MPF problem
If one can find a relationship among the elements of a given set
For example,
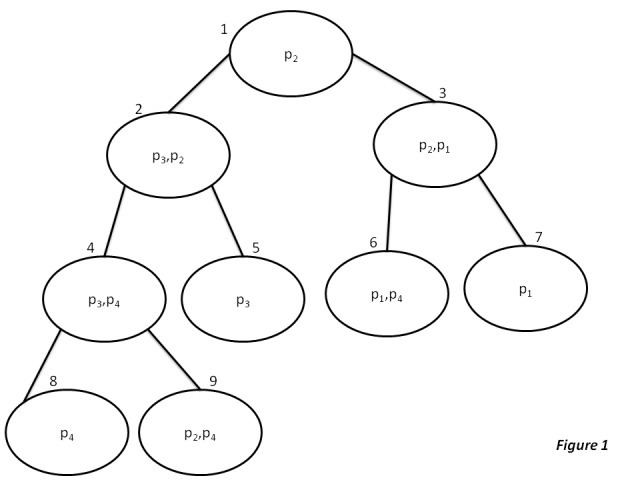
Example 1: Consider the following nine local domains:
-
{ p 2 } -
{ p 3 , p 2 } -
{ p 2 , p 1 } -
{ p 3 , p 4 } -
{ p 3 } -
{ p 1 , p 4 } -
{ p 1 } -
{ p 4 } -
{ p 2 , p 4 }
For the above given set of local domains, one can organize them into a junction tree as shown below:
Similarly If another set like the following is given
Example 2: Consider the following four local domains:
-
{ p 1 , p 2 } -
{ p 2 , p 3 } -
{ p 3 , p 4 } -
{ p 1 , p 4 }
Then constructing the tree only with these local domains is not possible since this set of values has no common domains which can be placed between any two values of the above set. But however if add the two dummy domains as shown below then organizing the updated set into a junction tree would be possible and easy too.
5.
6.
Similarly for these set of domains, the junction tree looks like shown below:
Generalized distributive law (GDL) algorithm
Input: A set of local domains.
Output: For the given set of domains, possible minimum number of operations that is required to solve the problem is computed.
So, if
where
Similarly each vertex has a state which is defined as a table containing the values from the function
Basic working of the algorithm
For the given set of local domains as input, we find out if we can create a junction tree, either by using the set directly or by adding dummy domains to the set first and then creating the junction tree, if construction junction is not possible then algorithm output that there is no way to reduce the number of steps to compute the given equation problem, but once we have junction tree, algorithm will have to schedule messages and compute states, by doing these we can know where steps can be reduced, hence will be discusses this below.
Scheduling of the message passing and the state computation
There are two special cases we are going to talk about here namely Single Vertex Problem in which the objective function is computed at only one vertex
Lets begin with the single-vertex problem, GDL will start by directing each edge towards the targeted vertex
For Example, Lets consider a junction tree constructed from the set of local domains given above i.e. the set from example 1,
Now the Scheduling table for these domains is (where the target vertex is
Thus the complexity for Single Vertex GDL can be shown as
Where (Note: The explanation for the above equation is explained later in the article )
To solve the All-Vertices problem, we can schedule GDL in several ways, some of them are parallel implementation where in each round, every state is updated and every message is computed and transmitted at the same time. In this type of implementation the states and messages will stabilizes after number of rounds that is at most equal to the diameter of the tree. At this point all the all states of the vertices will be equal to the desired objective function.
Another way to schedule GDL for this problem is serial implementation where its similar to the Single vertex problem except that we don't stop the algorithm until all the vertices of a required set have not got all the messages from all their neighbors and have compute their state.
Thus the number of arithmetic this implementation requires is at most
Constructing a junction tree
The key to constructing a junction tree lies in the local domain graph
if
where n is the number of elements in that set. For more clarity and details, please refer to these.
Scheduling theorem
Let
NOTE:
The schedule for the GDL is defined as a finite sequence of subsets of
Having defined/seen some notations, we will see want the theorem says, When we are given a schedule
and iff there is a path from
Computational complexity
Here we try to explain the complexity of solving the MPF problem in terms of the number of mathematical operations required for the calculation. i.e. We compare the number of operations required when calculated using the normal method (Here by normal method we mean by methods that do not use message passing or junction trees in short methods that do not use the concepts of GDL)and the number of operations using the generalized distributive law.
Example: Let us consider the simplest case where we need to compute the following expression
To evaluate this expression naively requires two multiplications and one addition. The expression when expressed using the distributive law can be written as
Similar to the above explained example we will be expressing the equations in different forms to perform as few operation as possible by applying the GDL.
As explained in the previous sections we solve the problem by using the concept of the junction trees. The optimization obtained by the use of these trees is comparable to the optimization obtained by solving a semi group problem on trees. For example, to find the minimum of a group of numbers we can observe that if we have a tree and the elements are all at the bottom of the tree, then we can compare the minimum of two items in parallel and the resultant minimum will be written to the parent. When this process is propagated up the tree the minimum of the group of elements will be found at the root.
The following is the complexity for solving the junction tree using message passing
We rewrite the formula used earlier to the following form. This is the eqn for a message to be sent from vertex v to w
Similarly we rewrite the equation for calculating the state of vertex v as follows
We first will analyze for the single-vertex problem and assume the target vertex is
additions and
multiplications.
(We represent the
But there will be many possibilities for
additions and
multiplications
The total number of arithmetic operations required to send a message towards
additions and
multiplications.
Once all the messages have been transmitted the algorithm terminates with the computation of state at
additions and
multiplications
Thus the grand total of the number of calculations is
where
The formula above gives us the upper bound.
If we define the complexity of the edge
Therefore,
We now calculate the edge complexity for the problem defined in Figure 1 as follows
The total complexity will be
Now we consider the all-vertex problem where the message will have to be sent in both the directions and state must be computed at both the vertexes. This would take
There is not much we can do when it comes to the construction of the junction tree except that we may have many maximal weight spanning tree and we should choose the spanning tree with the least
It may seem that GDL is correct only when the local domains can be expressed as a junction tree. But even in cases where there are cycles and a number of iterations the messages will approximately be equal to the objective function. The experiments on Gallager–Tanner–Wiberg algorithm for low density parity-check codes were supportive of this claim.