
Direction Left-to-right | ||
 | ||
Time period Early signs: 1st century CE, modern form: 10th century CE Parent systems BrāhmīGuptaNāgarīDevanagari Child systems Gujarati alphabet, Modi alphabet Similar Kharosthi, Abugida, Latin script | ||
Devanagari script
Devanagari (DAY-və-NAH-gər-ee; देवनागरी, IAST: Devanāgarī, a compound of "deva" देव and "nāgarī" नागरी; Hindi pronunciation: [d̪eːʋˈnaːɡri]; ), also called Nagari (Nāgarī, नागरी), is an Abugida (alphasyllabary) alphabet of India and Nepal. It is written from left to right, has a strong preference for symmetrical rounded shapes within squared outlines, and is recognisable by a horizontal line that runs along the top of full letters. In a cursory look, the Devanagari script appears different from other Indic scripts such as Bengali, Oriya, or Gurmukhi, but a closer examination reveals they are very similar except for angles and structural emphasis.
Contents
- Devanagari script
- Learn to write read hindi script learn devanagari script vowel sounds
- Origins
- Principle
- Letters
- Vowels
- Consonants
- Schwa syncope in consonants
- Allophony of v and w in Hindi
- Compounds
- Conjuncts
- Accent marks
- Punctuation
- Old forms
- Fonts
- Transliteration
- Hunterian system
- ISO 15919
- IAST
- Harvard Kyoto
- ITRANS
- Velthuis
- ALA LC Romanisation
- WX
- ISCII
- Unicode
- Devanagari keyboard layouts
- InScript layout
- Typewriter
- Phonetic
- References
The Nagari script has roots in the ancient Brāhmī script family. Some of the earliest epigraphical evidence attesting to the developing Sanskrit Nagari script in ancient India, in a form similar to Devanagari, is from the 1st to 4th century CE inscriptions discovered in Gujarat. The Nagari script was in regular use by the 7th century CE and it was fully developed by about the end of first millennium. The use of Sanskrit in Nagari script in medieval India is attested by numerous pillar and cave temple inscriptions, including the 11th-century Udayagiri inscriptions in Madhya Pradesh, and an inscribed brick found in Uttar Pradesh, dated to be from 1217 CE, which is now held at the British Museum. The script's proto- and related versions have been discovered in ancient relics outside of India, such as in Sri Lanka, Myanmar and Indonesia; while in East Asia, Siddha Matrika script considered as the closest precursor to Nagari was in use by Buddhists. Nagari has been the primus inter pares of the Indic scripts.

The Devanagari script is used for over 120 languages, including Hindi, Marathi, Nepali, Pali, Konkani, Bodo, Sindhi and Maithili among other languages and dialects, making it one of the most used and adopted writing systems in the world. The Devanagari script is also used for classical Sanskrit texts. The Devanagari script is closely related to the Nandinagari script commonly found in numerous ancient manuscripts of South India, and it is distantly related to a number of southeast Asian scripts.
Devanagari script has forty-seven primary characters, of which fourteen are vowels and thirty-three are Consonants. The ancient Nagari script for Sanskrit had two additional consonantal characters. The script has no distinction similar to the capital and small letters of the Latin alphabet. Generally the orthography of the script reflects the pronunciation of the language.
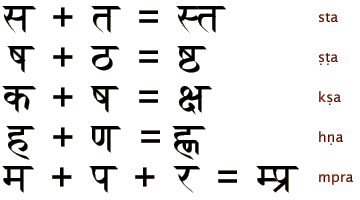
Learn to write read hindi script learn devanagari script vowel sounds
Origins

Devanagari is part of the Brahmic family of scripts of India, Nepal, Tibet, and South-East Asia. It is a descendant of the Gupta script, along with Siddham and Sharada. Variants of script called Nāgarī, recognisably close to Devanagari, are first attested from the 1st century CE Rudradaman inscriptions in Sanskrit, while the modern standardised form of Devanagari was in use by about 1000 CE. Medieval inscriptions suggest widespread diffusion of the Nagari-related scripts, with biscripts presenting local script along with the adoption of Nagari scripts. For example, the mid 8th century Pattadakal pillar in Karnataka has text in both Siddha Matrika script, and an early Telugu-Kannada script; while, the Kangra Jvalamukhi inscription in Himachal Pradesh is written in both Sharada and Devanagari scripts.

The 7th-century Tibetan king Srong-tsan-gambo ordered that all foreign books be transcribed into the Tibetan language. He sent his ambassador Tonmi Sambota to India to acquire alphabet and writing methods; returning with Sanskrit Nagari script from Kashmir corresponding to 24 Tibetan sounds and innovating new symbols for 6 local sounds. Other closely related scripts such as Siddham Matrka was in use in Indonesia, Vietnam, Japan and other parts of East Asia by between 7th- to 10th-century. Sharada remained in parallel use in Kashmir. An early version of Devanagari is visible in the Kutila inscription of Bareilly dated to Vikram Samvat 1049 (i.e. 992 CE), which demonstrates the emergence of the horizontal bar to group letters belonging to a word. One of the oldest surviving Sanskrit text from early post-Maurya period available consists of 1,413 Nagari pages of a commentary by Patanjali, with a composition date of about 150 BCE, the surviving copy transcribed about 14th century CE.
Nāgarī is the Sanskrit feminine of Nāgara "relating or belonging to a town or city, urban". It is a phrasing with lipi ("script") as nāgarī lipi "script relating to a city", or "spoken in city".
The use of the name devanāgarī is relatively recent, and the older term nāgarī is still common. The rapid spread of the term devanāgarī may be related to the almost exclusive use of this script to publish Sanskrit texts in print since the 1870s.
Principle
As a Brahmic abugida, the fundamental principle of Devanagari is that each letter represents a consonant, which carries an inherent schwa vowel. This is usually written in Latin as a, though it is represented as [ə] in the International phonetic Alphabet. The letter क is read ka, the two letters कन are kana, the three कनय are kanaya, etc. Other vowels, or the absence of vowels, require modification of these consonants or their own letters:
Such a letter or ligature, with its diacritics, is called an akṣara "syllable". For example, कनय kanaya is written with what are counted as three akshara, whereas क्न्य knya and कु ku are each written with one.
When handwriting, letters are usually written without the distinctive horizontal bar, which is added only once the word is completed.
Letters
The letter order of Devanagari, like nearly all Brahmic scripts, is based on phonetic principles that consider both the manner and place of articulation of the consonants and vowels they represent. This arrangement is usually referred to as the varṇamālā "garland of letters". The format of Devanagari for Sanskrit serves as the prototype for its application, with minor variations or additions, to other languages.
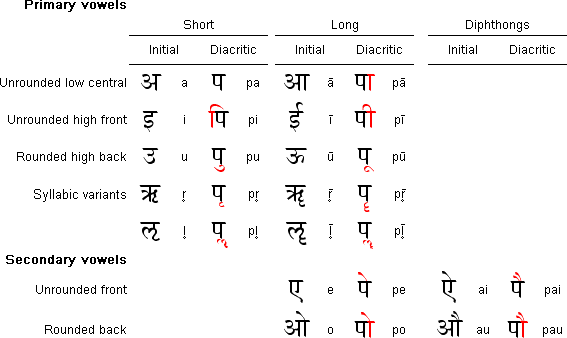
Vowels
The vowels and their arrangement are:
- Arranged with the vowels are two consonantal diacritics, the final nasal anusvāra ं ṃ and the final Fricative visarga ः ḥ (called अं aṃ and अः aḥ). Masica (1991:146) notes of the anusvāra in Sanskrit that "there is some controversy as to whether it represents a homorganic nasal stop [...], a nasalised vowel, a nasalised semivowel, or all these according to context". The visarga represents post-vocalic voiceless glottal fricative [h], in Sanskrit an allophone of s, or less commonly r, usually in word-final position. Some traditions of recitation append an echo of the vowel after the breath: इः [ihi]. Masica (1991:146) considers the visarga along with letters ङ ṅa and ञ ña for the "largely predictable" velar and Palatal nasals to be examples of "phonetic overkill in the system".
- Another diacritic is the candrabindu/anunāsika ँ अँ. Salomon (2003:76–77) describes it as a "more emphatic form" of the anusvāra, "sometimes [...] used to mark a true [vowel] nasalization". In a New Indo-Aryan language such as Hindi the distinction is formal: the candrabindu indicates vowel nasalisation while the anusvār indicates a homorganic nasal preceding another consonant: e.g. हँसी [ɦə̃si] "laughter", गंगा [ɡəŋɡɑ] "the Ganges". When an akshara has a vowel diacritic above the top line, that leaves no room for the candra ("moon") stroke candrabindu, which is dispensed with in favour of the lone dot: हूँ [ɦũ] "am", but हैं [ɦɛ̃] "are". Some writers and typesetters dispense with the "moon" stroke altogether, using only the dot in all situations.
- The avagraha ऽ अऽ (usually transliterated with an apostrophe) is a Sanskrit punctuation mark for the elision of a vowel in sandhi: एकोऽयम् eko'yam ( ← ekas + ayam) "this one". An original long vowel lost to coalescence is sometimes marked with a double avagraha: सदाऽऽत्मा sadā'tmā ( ← sadā + ātmā) "always, the self". In Hindi, Snell (2000:77) states that its "main function is to show that a vowel is sustained in a cry or a shout": आईऽऽऽ! āīīī!. In Madhyadeshi Languages like Bhojpuri, Awadhi, Maithili, etc. which have "quite a number of verbal forms [that] end in that inherent vowel", the avagraha is used to mark the non-elision of word-final inherent a, which otherwise is a modern orthographic convention: बइठऽ baiṭha "sit" versus *बइठ baiṭh
- The syllabic consonants ṝ, ḷ, and ḹ are specific to Sanskrit and not included in the varṇamālā of other languages. The sound represented by ṛ has also been lost in the modern languages, and its pronunciation now ranges from [ɾɪ] (Hindi) to [ɾu] (Marathi).
- ḹ is not an actual phoneme of Sanskrit, but rather a graphic convention included among the vowels in order to maintain the symmetry of short–long pairs of letters.
- There are non-regular formations of रु ru and रू rū.
- There are two more vowels in Marathi, अॅ and ऑ, that respectively represent [æ], similar to the English pronunciation of <a> in "act", and [ɒ], similar to the English pronunciation of
in "c ot". These vowels are sometimes used in Hindi too.
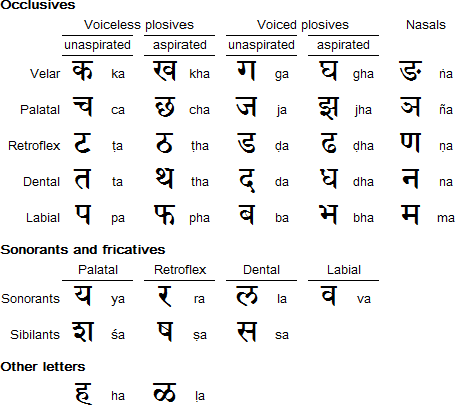
Consonants
The table below shows the consonant letters (in combination with inherent vowel a) and their arrangement. To the right of the Devanagari letter it shows the Latin script transliteration using IAST, and the phonetic value (IPA).
For a list of the 297 (33×9) possible Sanskrit consonant-(short) vowel phonemes, see Āryabhaṭa numeration.
Schwa syncope in consonants
In many Indo-Aryan languages, the schwa ('ə') implicit in each consonant of the script is "obligatorily deleted" at the end of words and in certain other contexts, unlike in Marathi or Sanskrit. This phenomenon has been termed the "schwa syncope rule" or the "Schwa deletion rule" of Hindi. One formalisation of this rule has been summarised as ə → ∅ | VC_CV. In other words, when a schwa-succeeded consonant is followed by a vowel-succeeded consonant, the schwa inherent in the first consonant is deleted. However, this formalisation is inexact and incomplete (it sometimes deletes a schwa when it should not and, at other times, it fails to delete it when it should) and can cause errors. Schwa deletion is computationally important because it is essential to building text-to-speech software for Hindi.
As a result of schwa syncope, the Hindi pronunciation of many words differs from that expected from a literal Sanskrit-style rendering of Devanagari. For instance, राम is rām (not rāma), रचना is racnā (not racanā), वेद is vēd (not vēda) and नमकीन is namkīn (not namakīna). The name of the script itself is pronounced devnāgrī (not devanāgarī).
Correct schwa deletion is also critical because, in some cases, the same Devanagari letter sequence is pronounced two different ways in Hindi depending on context, and failure to delete the appropriate schwas can change the sense of the word. For instance, the letter sequence 'रक' is pronounced differently in हरकत (harkat, meaning movement or activity) and सरकना (saraknā, meaning to slide). Similarly, the sequence धड़कने in दिल धड़कने लगा (the heart started beating) and in दिल की धड़कनें (beats of the heart) is identical prior to the nasalisation in the second usage. Yet, it is pronounced dhaṛaknē in the first and dhaṛkanē in the second. While native speakers correctly pronounce the sequences differently in different contexts, non-native speakers and voice-synthesis software can make them "sound very unnatural", making it "extremely difficult for the listener" to grasp the intended meaning.
Allophony of 'v' and 'w' in Hindi
[v] (the voiced labiodental fricative) and [w] (the voiced labio-velar approximant) are both allophones of the single phoneme represented by the letter 'व' in Hindi Devanagari. More specifically, they are conditional allophones, i.e. rules apply on whether 'व' is pronounced as [v] or [w] depending on context. Native Hindi speakers pronounce 'व' as [v] in vrat (व्रत, fast) and [w] in pakvān (पकवान, food dish), perceiving them as a single phoneme and without being aware of the allophone distinctions they are systematically making. However, this specific allophony can become obvious when speakers switch languages. Non-native speakers of Hindi might pronounce 'व' in 'व्रत' as [w], i.e. as wrat instead of the more correct vrat. This results in a minor intelligibility problem because wrat can easily be confused for aurat, which means woman, instead of the intended fast (abstaining from food), in Hindi.
Compounds
Table: Compounds. Vowels in their independent form on the left and in their corresponding dependent form (vowel sign) combined with the consonant 'k' on the right. 'ka' is without any added vowel sign, where the vowel 'a' is inherent. ISO 15919 transliteration is on the top two rows.
A vowel combines with a consonant to form their compound letter. For example, the vowel आ (ā) combines with the consonant क् (k) to form the compound का (kā), with halant removed and added vowel sign which is indicated by diacritics. The vowel अ (a) combines with the consonant क् (k) to form the compound क (ka) with halant removed. But, the compound letter series of क, ख, ग, घ... (ka, kha, ga, gha) is without any added vowel sign, as the vowel अ (a) is inherent.
Conjuncts
You will be able to see the ligatures only if your system has a Unicode font installed that includes the required ligature glyphs (such as one of the TDIL fonts, see "external links" below).As mentioned, successive consonants lacking a vowel in between them may physically join together as a conjunct or ligature. Conjuncts are used mostly with loan words. Native words typically use the basic consonant and native speakers know to suppress the vowel. For example, the native Hindi word karnā is written करना (ka-ra-nā). The government of these clusters ranges from widely to narrowly applicable rules, with special exceptions within. While standardised for the most part, there are certain variations in clustering, of which the Unicode used on this page is just one scheme. The following are a number of rules:
The table below shows all the 1296 viable symbols for the biconsonantal clusters formed by collating the 36 fundamental symbols of Sanskrit as listed in Masica (1991:161–162). Scroll your cursor over the conjuncts to reveal their romanisations (in ISO 15919) and IPA transcriptions. Note that not all these conjuncts appear in genuine words.
Accent marks
The pitch accent of Vedic Sanskrit is written with various symbols depending on shakha. In the Rigveda, anudātta is written with a bar below the line (◌॒), svarita with a stroke above the line (◌॑) while udātta is unmarked.
Punctuation
The end of a sentence or half-verse may be marked with the "।" symbol (called a danda, meaning "bar", or called a pūrṇa virām, meaning "complete stop/pause"). The end of a full verse may be marked with a double-danda, a "॥" symbol. A comma (called an alpa virām, meaning "short stop/pause") is used to denote a natural pause in speech. Other punctuation marks such as colon, semi-colon, exclamation mark, dash, and question mark are currently in use in Devanagari script, matching their use in European languages.
Old forms
The following letter variants are also in use, particularly in older texts.
Fonts
A variety of unicode fonts are in use for Devanagari. These include, but are not limited to, Akshar, Annapurna, Arial, CDAC-Gist Surekh, CDAC-Gist Yogesh, Chandas, Gargi, Gurumaa, Jaipur, Jana, Kalimati, Kanjirowa, Lohit Devanagari, Mangal, Raghu, Sanskrit2003, Santipur OT, Siddhdnta, Thyaka, and Uttara.
The form of Devanagari fonts vary with function. According to Harvard College for Sanskrit studies, "Uttara [companion to Chandas] is the best in terms of ligatures but, because it is designed for Vedic as well, requires so much vertical space that it is not well suited for the "user interface font" (though an excellent choice for the "original field" font). Santipur OT is a beautiful font reflecting a very early [medieval era] typesetting style for Devanagari. Sanskrit 2003 is a good all-around font and has more ligatures than most fonts, though students will probably find the spacing of the CDAC-Gist Surekh font makes for quicker comprehension and reading."
Google Fonts project now has a number of new unicode fonts for Devanagari in a variety of typefaces in Serif, Sans-Serif, Display and Handwriting categories.
Transliteration
There are several methods of Romanisation or transliteration from Devanagari to the Roman script.
Hunterian system
The Hunterian system is the "national system of romanisation in India" and the one officially adopted by the Government of India.
ISO 15919
A standard transliteration convention was codified in the ISO 15919 standard of 2001. It uses diacritics to map the much larger set of Brahmic graphemes to the Latin script. The Devanagari-specific portion is nearly identical to the academic standard for Sanskrit, IAST.
IAST
The International Alphabet of Sanskrit Transliteration (IAST) is the academic standard for the romanisation of Sanskrit. IAST is the de facto standard used in printed publications, like books, magazines, and electronic texts with Unicode fonts. It is based on a standard established by the Congress of Orientalists at Athens in 1912. The ISO 15919 standard of 2001 codified the transliteration convention to include an expanded standard for sister scripts of Devanagari.
The National Library at Kolkata romanisation, intended for the romanisation of all Indic scripts, is an extension of IAST.
Harvard-Kyoto
Compared to IAST, Harvard-Kyoto looks much simpler. It does not contain all the diacritic marks that IAST contains. It was designed to simplify the task of putting large amount of Sanskrit textual material into machine readable form, and the inventors stated that it reduces the effort needed in transliteration of Sanskrit texts on the keyboard. This makes typing in Harvard-Kyoto much easier than IAST. Harvard-Kyoto uses capital letters that can be difficult to read in the middle of words.
ITRANS
ITRANS is a lossless transliteration scheme of Devanagari into ASCII that is widely used on Usenet. It is an extension of the Harvard-Kyoto scheme. In ITRANS, the word devanāgarī is written "devanaagarii" or "devanAgarI". ITRANS is associated with an application of the same name that enables typesetting in Indic scripts. The user inputs in Roman letters and the ITRANS pre-processor translates the Roman letters into Devanagari (or other Indic languages). The latest version of ITRANS is version 5.30 released in July, 2001. It is similar to Velthius system and was created by Avinash Chopde to help print various Indic scripts with personal computers.
Velthuis
The disadvantage of the above ASCII schemes is case-sensitivity, implying that transliterated names may not be capitalised. This difficulty is avoided with the system developed in 1996 by Frans Velthuis for TeX, loosely based on IAST, in which case is irrelevant.
ALA-LC Romanisation
ALA-LC romanisation is a transliteration scheme approved by the Library of Congress and the American Library Association, and widely used in North American libraries. Transliteration tables are based on languages, so there is a table for Hindi, one for Sanskrit and Prakrit, etc.
WX
WX is a Roman transliteration scheme for Indian languages, widely used among the natural language processing community in India. It originated at IIT Kanpur for computational processing of Indian languages. The salient features of this transliteration scheme are as follows.
ISCII
ISCII is an 8-bit encoding. The lower 128 codepoints are plain ASCII, the upper 128 codepoints are ISCII-specific.
It has been designed for representing not only Devanagari but also various other Indic scripts as well as a Latin-based script with diacritic marks used for transliteration of the Indic scripts.
ISCII has largely been superseded by Unicode, which has, however, attempted to preserve the ISCII layout for its Indic language blocks.
Unicode
The Unicode Standard defines three blocks for Devanagari: Devanagari (U+0900–U+097F), Devanagari Extended (U+A8E0–U+A8FF), and Vedic Extensions (U+1CD0–U+1CFF).
Devanagari keyboard layouts
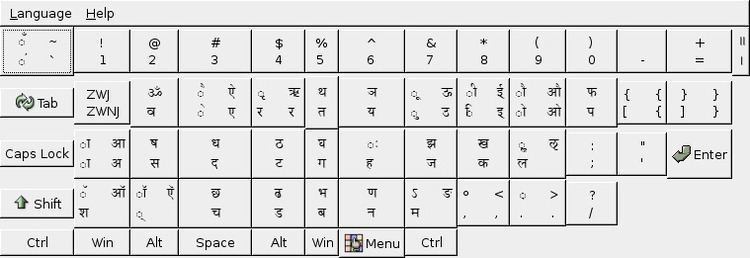
For a list of Devanagari input tools and fonts, please see Help:Multilingual support (Indic).Inscript is the standard keyboard layout for Devanagari. It is inbuilt in all modern major operating systems. Microsoft Windows supports the inscript layout (using the Mangal font), which can be used to input unicode Devanagari characters. InScript is also available in some touchscreen mobile phones.
InScript layout
A Devanagari INSCRIPT bilingual keyboard.
Typewriter
This layout was used on manual typewriters when computers were not available or were uncommon. For backward compatibility some typing tools like Indic IME still provide this layout.
Phonetic
Such tools work on phonetic transliteration. The user writes in Roman and the IME automatically converts it into Devanagari. Some popular phonetic typing tools are Baraha IME and Google IME.
The Mac OS X operating system includes two different keyboard layouts for Devanagari: one is much like INSCRIPT/KDE Linux, the other is a phonetic layout called "Devanagari QWERTY".
Any one of Unicode fonts input system is fine for Indic language Wikipedia and other wikiprojects, including Hindi, Bhojpuri, Marathi, Nepali Wikipedia. Some people use inscript. Majority uses either Google phonetic transliteration or input facility Universal Language Selector provided on Wikipedia. On Indic language wikiprojects Phonetic facility provided initially was java-based later supported by Narayam extension for phonetic input facility. Currently Indic language Wiki projects are supported by Universal Language Selector (ULS), that offers both phonetic keyboard (Aksharantaran, Marathi: अक्षरांतरण, Hindi: लिप्यंतरण, बोलनागरी) and InScript keyboard (Marathi: मराठी लिपी).
The Ubuntu Linux operating system supports several keyboard layouts for Devanagari, including Harvard-Kyoto, WX notation, Bolanagari and phonetic.