
 | ||
CMA-ES stands for Covariance Matrix Adaptation Evolution Strategy. Evolution strategies (ES) are stochastic, derivative-free methods for numerical optimization of non-linear or non-convex continuous optimization problems. They belong to the class of evolutionary algorithms and evolutionary computation. An evolutionary algorithm is broadly based on the principle of biological evolution, namely the repeated interplay of variation (via recombination and mutation) and selection: in each generation (iteration) new individuals (candidate solutions, denoted as
Contents
- Principles
- Algorithm
- Theoretical foundations
- Variable metric
- Maximum likelihood updates
- Natural gradient descent in the space of sample distributions
- Stationarity or unbiasedness
- Invariance
- Convergence
- Interpretation as coordinate system transformation
- Performance in practice
- Variations and extensions
- References
In an evolution strategy, new candidate solutions are sampled according to a multivariate normal distribution in the
Adaptation of the covariance matrix amounts to learning a second order model of the underlying objective function similar to the approximation of the inverse Hessian matrix in the Quasi-Newton method in classical optimization. In contrast to most classical methods, fewer assumptions on the nature of the underlying objective function are made. Only the ranking between candidate solutions is exploited for learning the sample distribution and neither derivatives nor even the function values themselves are required by the method.
Principles
Two main principles for the adaptation of parameters of the search distribution are exploited in the CMA-ES algorithm.
First, a maximum-likelihood principle, based on the idea to increase the probability of successful candidate solutions and search steps. The mean of the distribution is updated such that the likelihood of previously successful candidate solutions is maximized. The covariance matrix of the distribution is updated (incrementally) such that the likelihood of previously successful search steps is increased. Both updates can be interpreted as a natural gradient descent. Also, in consequence, the CMA conducts an iterated principal components analysis of successful search steps while retaining all principal axes. Estimation of distribution algorithms and the Cross-Entropy Method are based on very similar ideas, but estimate (non-incrementally) the covariance matrix by maximizing the likelihood of successful solution points instead of successful search steps.
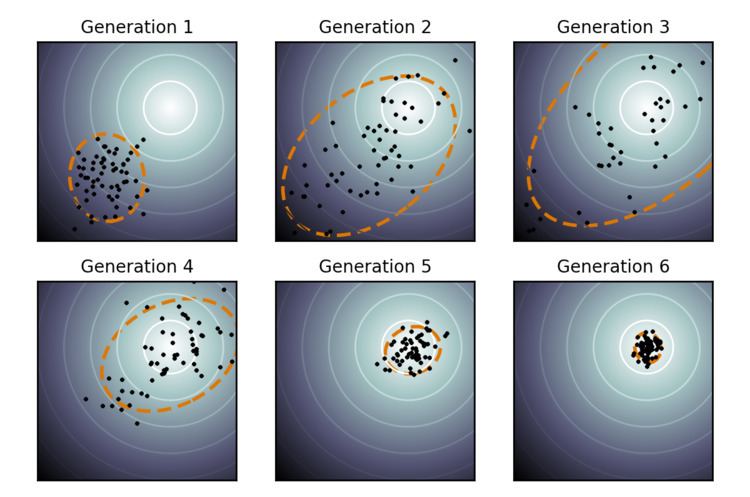
Second, two paths of the time evolution of the distribution mean of the strategy are recorded, called search or evolution paths. These paths contain significant information about the correlation between consecutive steps. Specifically, if consecutive steps are taken in a similar direction, the evolution paths become long. The evolution paths are exploited in two ways. One path is used for the covariance matrix adaptation procedure in place of single successful search steps and facilitates a possibly much faster variance increase of favorable directions. The other path is used to conduct an additional step-size control. This step-size control aims to make consecutive movements of the distribution mean orthogonal in expectation. The step-size control effectively prevents premature convergence yet allowing fast convergence to an optimum.
Algorithm
In the following the most commonly used (μ/μw, λ)-CMA-ES is outlined, where in each iteration step a weighted combination of the μ best out of λ new candidate solutions is used to update the distribution parameters. The main loop consists of three main parts: 1) sampling of new solutions, 2) re-ordering of the sampled solutions based on their fitness, 3) update of the internal state variables based on the re-ordered samples. A pseudocode of the algorithm looks as follows.
setThe order of the five update assignments is relevant. In the following, the update equations for the five state variables are specified.
Given are the search space dimension
The iteration starts with sampling
The second line suggests the interpretation as perturbation (mutation) of the current favorite solution vector
the new mean value is computed as
where the positive (recombination) weights
The step-size
where
The step-size
and decreased if it is smaller. For this reason, the step-size update tends to make consecutive steps
Finally, the covariance matrix is updated, where again the respective evolution path is updated first.
where
The covariance matrix update tends to increase the likelihood for
The number of candidate samples per iteration,
Theoretical foundations
Given the distribution parameters—mean, variances and covariances—the normal probability distribution for sampling new candidate solutions is the maximum entropy probability distribution over
Variable metric
The CMA-ES implements a stochastic variable-metric method. In the very particular case of a convex-quadratic objective function
the covariance matrix
Maximum-likelihood updates
The update equations for mean and covariance matrix maximize a likelihood while resembling an expectation-maximization algorithm. The update of the mean vector
where
denotes the log-likelihood of
The rank-
for
Natural gradient descent in the space of sample distributions
Akimoto et al. and Glasmachers et al. discovered independently that the update of the distribution parameters resembles the descend in direction of a sampled natural gradient of the expected objective function value E f (x) (to be minimized), where the expectation is taken under the sample distribution. With the parameter setting of
where
where the Fisher information matrix
A Monte Carlo approximation of the latter expectation takes the average over λ samples from p
where the notation
Ollivier et al. finally found a rigorous derivation for the more robust weights,
Let
such that
and for
and, after some calculations, the updates in the CMA-ES turn out as
and
where mat forms the proper matrix from the respective natural gradient sub-vector. That means, setting
Stationarity or unbiasedness
It is comparatively easy to see that the update equations of CMA-ES satisfy some stationarity conditions, in that they are essentially unbiased. Under neutral selection, where
and under some mild additional assumptions on the initial conditions
and with an additional minor correction in the covariance matrix update for the case where the indicator function evaluates to zero, we find
Invariance
Invariance properties imply uniform performance on a class of objective functions. They have been argued to be an advantage, because they allow to generalize and predict the behavior of the algorithm and therefore strengthen the meaning of empirical results obtained on single functions. The following invariance properties have been established for CMA-ES.
Any serious parameter optimization method should be translation invariant, but most methods do not exhibit all the above described invariance properties. A prominent example with the same invariance properties is the Nelder–Mead method, where the initial simplex must be chosen respectively.
Convergence
Conceptual considerations like the scale-invariance property of the algorithm, the analysis of simpler evolution strategies, and overwhelming empirical evidence suggest that the algorithm converges on a large class of functions fast to the global optimum, denoted as
for some
or similarly,
This means that on average the distance to the optimum decreases in each iteration by a "constant" factor, namely by
Interpretation as coordinate-system transformation
Using a non-identity covariance matrix for the multivariate normal distribution in evolution strategies is equivalent to a coordinate system transformation of the solution vectors, mainly because the sampling equation
can be equivalently expressed in an "encoded space" as
The covariance matrix defines a bijective transformation (encoding) for all solution vectors into a space, where the sampling takes place with identity covariance matrix. Because the update equations in the CMA-ES are invariant under linear coordinate system transformations, the CMA-ES can be re-written as an adaptive encoding procedure applied to a simple evolution strategy with identity covariance matrix. This adaptive encoding procedure is not confined to algorithms that sample from a multivariate normal distribution (like evolution strategies), but can in principle be applied to any iterative search method.
Performance in practice
In contrast to most other evolutionary algorithms, the CMA-ES is, from the users perspective, quasi parameter-free. The user has to choose an initial solution point,
The CMA-ES has been empirically successful in hundreds of applications and is considered to be useful in particular on non-convex, non-separable, ill-conditioned, multi-modal or noisy objective functions. The search space dimension ranges typically between two and a few hundred. Assuming a black-box optimization scenario, where gradients are not available (or not useful) and function evaluations are the only considered cost of search, the CMA-ES method is likely to be outperformed by other methods in the following conditions:
On separable functions, the performance disadvantage is likely to be most significant in that CMA-ES might not be able to find at all comparable solutions. On the other hand, on non-separable functions that are ill-conditioned or rugged or can only be solved with more than
Variations and extensions
The (1+1)-CMA-ES generates only one candidate solution per iteration step which becomes the new distribution mean if it is better than the current mean. For
With the advent of niching methods in evolutionary strategies, the question of an optimal niche radius arises. An "adaptive individual niche radius" is introduced in