
 | ||
In cryptography, a block cipher is a deterministic algorithm operating on fixed-length groups of bits, called blocks, with an unvarying transformation that is specified by a symmetric key. Block ciphers operate as important elementary components in the design of many cryptographic protocols, and are widely used to implement encryption of bulk data.
Contents
- Definition
- Iterated block ciphers
- Substitution permutation networks
- Feistel ciphers
- Lai Massey ciphers
- ARX add rotate xor
- other operations
- Modes of operation
- Padding
- Brute force attacks
- Linear cryptanalysis
- Integral cryptanalysis
- Other techniques
- Provable security
- Standard model
- Practical evaluation
- Lucifer DES
- IDEA
- RC5
- Rijndael AES
- Blowfish
- Tweakable block ciphers
- Format preserving encryption
- Relation to other cryptographic primitives
- References
The modern design of block ciphers is based on the concept of an iterated product cipher. In his seminal 1949 publication, Communication Theory of Secrecy Systems, Claude Shannon analyzed product ciphers and suggested them as a means of effectively improving security by combining simple operations such as substitutions and permutations. Iterated product ciphers carry out encryption in multiple rounds, each of which uses a different subkey derived from the original key. One widespread implementation of such ciphers, named a Feistel network after Horst Feistel, is notably implemented in the DES cipher. Many other realizations of block ciphers, such as the AES, are classified as substitution-permutation networks.
The publication of the DES cipher by the United States National Bureau of Standards (subsequently the U.S. National Institute of Standards and Technology, NIST) in 1977 was fundamental in the public understanding of modern block cipher design. It also influenced the academic development of cryptanalytic attacks. Both differential and linear cryptanalysis arose out of studies on the DES design. As of 2016 there is a palette of attack techniques against which a block cipher must be secure, in addition to being robust against brute force attacks.
Even a secure block cipher is suitable only for the encryption of a single block under a fixed key. A multitude of modes of operation have been designed to allow their repeated use in a secure way, commonly to achieve the security goals of confidentiality and authenticity. However, block ciphers may also feature as building-blocks in other cryptographic protocols, such as universal hash functions and pseudo-random number generators.
Definition
A block cipher consists of two paired algorithms, one for encryption, E, and the other for decryption, D. Both algorithms accept two inputs: an input block of size n bits and a key of size k bits; and both yield an n-bit output block. The decryption algorithm D is defined to be the inverse function of encryption, i.e., D = E−1. More formally, a block cipher is specified by an encryption function
which takes as input a key K of bit length k, called the key size, and a bit string P of length n, called the block size, and returns a string C of n bits. P is called the plaintext, and C is termed the ciphertext. For each K, the function EK(P) is required to be an invertible mapping on {0,1}n. The inverse for E is defined as a function
taking a key K and a ciphertext C to return a plaintext value P, such that
For example, a block cipher encryption algorithm might take a 128-bit block of plaintext as input, and output a corresponding 128-bit block of ciphertext. The exact transformation is controlled using a second input – the secret key. Decryption is similar: the decryption algorithm takes, in this example, a 128-bit block of ciphertext together with the secret key, and yields the original 128-bit block of plain text.
For each key K, EK is a permutation (a bijective mapping) over the set of input blocks. Each key selects one permutation from the possible set of
Iterated block ciphers
Most block cipher algorithms are classified as iterated block ciphers which means that they transform fixed-size blocks of plain-text into identical size blocks of ciphertext, via the repeated application of an invertible transformation known as the round function, with each iteration referred to as a round.
Usually, the round function R takes different round keys Ki as second input, which are derived from the original key:
where
Frequently, key whitening is used in addition to this. At the beginning and the end, the data is modified with key material (often with XOR, but simple arithmetic operations like adding and subtracting are also used):
Given one of the standard iterated block cipher design schemes, it is fairly easy to construct a block cipher that is cryptographically secure, simply by using a large number of rounds. However, this will make the cipher inefficient. Thus, efficiency is the most important additional design criterion for professional ciphers. Further, a good block cipher is designed to avoid side-channel attacks, such as input-dependent memory accesses that might leak secret data via the cache state or the execution time. In addition, the cipher should be concise, for small hardware and software implementations. Finally, the cipher should be easily cryptanalyzable, such that it can be shown to how many rounds the cipher needs to be reduced such that the existing cryptographic attacks would work and, conversely, that the number of actual rounds is large enough to protect against them.
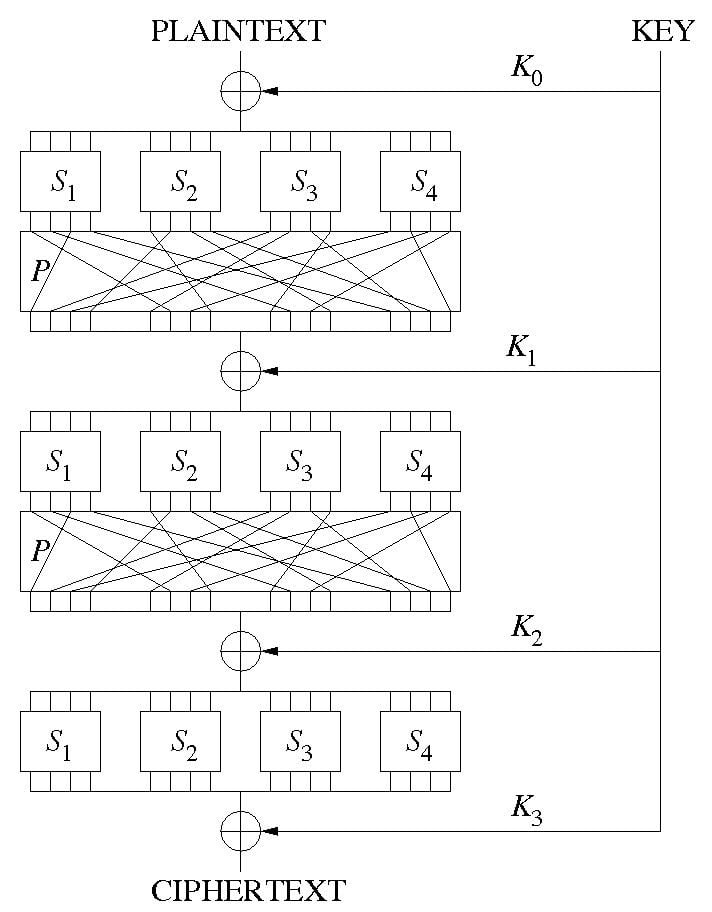
Substitution-permutation networks
One important type of iterated block cipher known as a substitution-permutation network (SPN) takes a block of the plaintext and the key as inputs, and applies several alternating rounds consisting of a substitution stage followed by a permutation stage—to produce each block of ciphertext output. The non-linear substitution stage mixes the key bits with those of the plaintext, creating Shannon's confusion. The linear permutation stage then dissipates redundancies, creating diffusion.
A substitution box (S-box) substitutes a small block of input bits with another block of output bits. This substitution must be one-to-one, to ensure invertibility (hence decryption). A secure S-box will have the property that changing one input bit will change about half of the output bits on average, exhibiting what is known as the avalanche effect—i.e. it has the property that each output bit will depend on every input bit.
A permutation box (P-box) is a permutation of all the bits: it takes the outputs of all the S-boxes of one round, permutes the bits, and feeds them into the S-boxes of the next round. A good P-box has the property that the output bits of any S-box are distributed to as many S-box inputs as possible.
At each round, the round key (obtained from the key with some simple operations, for instance, using S-boxes and P-boxes) is combined using some group operation, typically XOR.
Decryption is done by simply reversing the process (using the inverses of the S-boxes and P-boxes and applying the round keys in reversed order).
Feistel ciphers
In a Feistel cipher, the block of plain text to be encrypted is split into two equal-sized halves. The round function is applied to one half, using a subkey, and then the output is XORed with the other half. The two halves are then swapped.
Let
Then the basic operation is as follows:
Split the plaintext block into two equal pieces, (
For each round
Then the ciphertext is
Decryption of a ciphertext
Then
One advantage of the Feistel model compared to a substitution-permutation network is that the round function
Lai-Massey ciphers
The Lai-Massey scheme offers security properties similar to those of the Feistel structure. It also shares its advantage that the round function
Let
Then the basic operation is as follows:
Split the plaintext block into two equal pieces, (
For each round
where
Then the ciphertext is
Decryption of a ciphertext
where
Then
ARX add-rotate-xor
Many modern block ciphers and hashes are ARX algorithms—their round function involves only three operations: modular addition, rotation with fixed rotation amounts, and XOR (ARX). Examples include Salsa20, Speck, XXTEA, and BLAKE. Many authors draw an ARX network, a kind of data flow diagram, to illustrate such a round function.
These ARX operations are popular because they are relatively fast and cheap in hardware and software, and also because they run in constant time, and are therefore immune to timing attacks. The rotational cryptanalysis technique attempts to attack such round functions.
other operations
Other operations often used in block ciphers include data-dependent rotations as in RC5 and RC6, a substitution box implemented as a lookup table as in Data Encryption Standard and Advanced Encryption Standard, a permutation box, and multiplication as in IDEA.
Modes of operation
A block cipher by itself allows encryption only of a single data block of the cipher's block length. For a variable-length message, the data must first be partitioned into separate cipher blocks. In the simplest case, known as the electronic codebook (ECB) mode, a message is first split into separate blocks of the cipher's block size (possibly extending the last block with padding bits), and then each block is encrypted and decrypted independently. However, such a naive method is generally insecure because equal plaintext blocks will always generate equal ciphertext blocks (for the same key), so patterns in the plaintext message become evident in the ciphertext output.
To overcome this limitation, several so-called block cipher modes of operation have been designed and specified in national recommendations such as NIST 800-38A and BSI TR-02102 and international standards such as ISO/IEC 10116. The general concept is to use randomization of the plaintext data based on an additional input value, frequently called an initialization vector, to create what is termed probabilistic encryption. In the popular cipher block chaining (CBC) mode, for encryption to be secure the initialization vector passed along with the plaintext message must be a random or pseudo-random value, which is added in an exclusive-or manner to the first plaintext block before it is being encrypted. The resultant ciphertext block is then used as the new initialization vector for the next plaintext block. In the cipher feedback (CFB) mode, which emulates a self-synchronizing stream cipher, the initialization vector is first encrypted and then added to the plaintext block. The output feedback (OFB) mode repeatedly encrypts the initialization vector to create a key stream for the emulation of a synchronous stream cipher. The newer counter (CTR) mode similarly creates a key stream, but has the advantage of only needing unique and not (pseudo-)random values as initialization vectors; the needed randomness is derived internally by using the initialization vector as a block counter and encrypting this counter for each block.
From a security-theoretic point of view, modes of operation must provide what is known as semantic security. Informally, it means that given some ciphertext under an unknown key one cannot practically derive any information from the ciphertext (other than the length of the message) over what one would have known without seeing the ciphertext. It has been shown that all of the modes discussed above, with the exception of the ECB mode, provide this property under so-called chosen plaintext attacks.
Padding
Some modes such as the CBC mode only operate on complete plaintext blocks. Simply extending the last block of a message with zero-bits is insufficient since it does not allow a receiver to easily distinguish messages that differ only in the amount of padding bits. More importantly, such a simple solution gives rise to very efficient padding oracle attacks. A suitable padding scheme is therefore needed to extend the last plaintext block to the cipher's block size. While many popular schemes described in standards and in the literature have been shown to be vulnerable to padding oracle attacks, a solution which adds a one-bit and then extends the last block with zero-bits, standardized as "padding method 2" in ISO/IEC 9797-1, has been proven secure against these attacks.
Brute force attacks
Due to a block cipher's characteristic as an invertible function, its output becomes distinguishable from a truly random output string over time due to the birthday attack. This property results in the cipher's security degrading quadratically, and needs to be taken into account when selecting a block size. There is a trade-off though as large block sizes can result in the algorithm becoming inefficient to operate. Earlier block ciphers such as the DES have typically selected a 64-bit block size, while newer designs such as the AES support block sizes of 128 bits or more, with some ciphers supporting a range of different block sizes.
Linear cryptanalysis
Linear cryptanalysis is a form of cryptanalysis based on finding affine approximations to the action of a cipher. Linear cryptanalysis is one of the two most widely used attacks on block ciphers; the other being differential cryptanalysis.
The discovery is attributed to Mitsuru Matsui, who first applied the technique to the FEAL cipher (Matsui and Yamagishi, 1992).
Integral cryptanalysis
Integral cryptanalysis is a cryptanalytic attack that is particularly applicable to block ciphers based on substitution-permutation networks. Unlike differential cryptanalysis, which uses pairs of chosen plaintexts with a fixed XOR difference, integral cryptanalysis uses sets or even multisets of chosen plaintexts of which part is held constant and another part varies through all possibilities. For example, an attack might use 256 chosen plaintexts that have all but 8 of their bits the same, but all differ in those 8 bits. Such a set necessarily has an XOR sum of 0, and the XOR sums of the corresponding sets of ciphertexts provide information about the cipher's operation. This contrast between the differences of pairs of texts and the sums of larger sets of texts inspired the name "integral cryptanalysis", borrowing the terminology of calculus.
Other techniques
In addition to linear and differential cryptanalysis, there is a growing catalog of attacks: truncated differential cryptanalysis, partial differential cryptanalysis, integral cryptanalysis, which encompasses square and integral attacks, slide attacks, boomerang attacks, the XSL attack, impossible differential cryptanalysis and algebraic attacks. For a new block cipher design to have any credibility, it must demonstrate evidence of security against known attacks.
Provable security
When a block cipher is used in a given mode of operation, the resulting algorithm should ideally be about as secure as the block cipher itself. ECB (discussed above) emphatically lacks this property: regardless of how secure the underlying block cipher is, ECB mode can easily be attacked. On the other hand, CBC mode can be proven to be secure under the assumption that the underlying block cipher is likewise secure. Note, however, that making statements like this requires formal mathematical definitions for what it means for an encryption algorithm or a block cipher to "be secure". This section describes two common notions for what properties a block cipher should have. Each corresponds to a mathematical model that can be used to prove properties of higher level algorithms, such as CBC.
This general approach to cryptography---proving higher-level algorithms (such as CBC) are secure under explicitly stated assumptions regarding their components (such as a block cipher)---is known as provable security.
Standard model
Informally, a block cipher is secure in the standard model if an attacker cannot tell the difference between the block cipher (equipped with a random key) and a random permutation.
To be a bit more precise, let E be an n-bit block cipher. We imagine the following game:
- The person running the game flips a coin.
- If the coin lands on heads, he chooses a random key K and defines the function f = EK.
- If the coin lands on tails, he chooses a random permutation π on the set of n-bit strings, and defines the function f = π.
- The attacker chooses an n-bit string X, and the person running the game tells him the value of f(X).
- Step 2 is repeated a total of q times. (Each of these q interactions is a query.)
- The attacker guesses how the coin landed. He wins if his guess is correct.
The attacker, which we can model as an algorithm, is called an adversary. The function f (which the adversary was able to query) is called an oracle.
Note that an adversary can trivially ensure a 50% chance of winning simply by guessing at random (or even by, for example, always guessing "heads"). Therefore, let PE(A) denote the probability that the adversary A wins this game against E, and define the advantage of A as 2(PE(A) - 1/2). It follows that if A guesses randomly, its advantage will be 0; on the other hand, if A always wins, then its advantage is 1. The block cipher E is a pseudo-random permutation (PRP) if no adversary has an advantage significantly greater than 0, given specified restrictions on q and the adversary's running time. If in Step 2 above adversaries have the option of learning f−1(X) instead of f(X) (but still have only small advantages) then E is a strong PRP (SPRP). An adversary is non-adaptive if it chooses all q values for X before the game begins (that is, it does not use any information gleaned from previous queries to choose each X as it goes).
These definitions have proven useful for analyzing various modes of operation. For example, one can define a similar game for measuring the security of a block cipher-based encryption algorithm, and then try to show (through a reduction argument) that the probability of an adversary winning this new game is not much more than PE(A) for some A. (The reduction typically provides limits on q and the running time of A.) Equivalently, if PE(A) is small for all relevant A, then no attacker has a significant probability of winning the new game. This formalizes the idea that the higher-level algorithm inherits the block cipher's security.
Practical evaluation
Block ciphers may be evaluated according to multiple criteria in practice. Common factors include:
Lucifer / DES
Lucifer is generally considered to be the first civilian block cipher, developed at IBM in the 1970s based on work done by Horst Feistel. A revised version of the algorithm was adopted as a U.S. government Federal Information Processing Standard: FIPS PUB 46 Data Encryption Standard (DES). It was chosen by the U.S. National Bureau of Standards (NBS) after a public invitation for submissions and some internal changes by NBS (and, potentially, the NSA). DES was publicly released in 1976 and has been widely used.
DES was designed to, among other things, resist a certain cryptanalytic attack known to the NSA and rediscovered by IBM, though unknown publicly until rediscovered again and published by Eli Biham and Adi Shamir in the late 1980s. The technique is called differential cryptanalysis and remains one of the few general attacks against block ciphers; linear cryptanalysis is another, but may have been unknown even to the NSA, prior to its publication by Mitsuru Matsui. DES prompted a large amount of other work and publications in cryptography and cryptanalysis in the open community and it inspired many new cipher designs.
DES has a block size of 64 bits and a key size of 56 bits. 64-bit blocks became common in block cipher designs after DES. Key length depended on several factors, including government regulation. Many observers in the 1970s commented that the 56-bit key length used for DES was too short. As time went on, its inadequacy became apparent, especially after a special purpose machine designed to break DES was demonstrated in 1998 by the Electronic Frontier Foundation. An extension to DES, Triple DES, triple-encrypts each block with either two independent keys (112-bit key and 80-bit security) or three independent keys (168-bit key and 112-bit security). It was widely adopted as a replacement. As of 2011, the three-key version is still considered secure, though the National Institute of Standards and Technology (NIST) standards no longer permit the use of the two-key version in new applications, due to its 80-bit security level.
IDEA
The International Data Encryption Algorithm (IDEA) is a block cipher designed by James Massey of ETH Zurich and Xuejia Lai; it was first described in 1991, as an intended replacement for DES.
IDEA operates on 64-bit blocks using a 128-bit key, and consists of a series of eight identical transformations (a round) and an output transformation (the half-round). The processes for encryption and decryption are similar. IDEA derives much of its security by interleaving operations from different groups — modular addition and multiplication, and bitwise exclusive or (XOR) — which are algebraically "incompatible" in some sense.
The designers analysed IDEA to measure its strength against differential cryptanalysis and concluded that it is immune under certain assumptions. No successful linear or algebraic weaknesses have been reported. As of 2012, the best attack which applies to all keys can break full 8.5 round IDEA using a narrow-bicliques attack about four times faster than brute force.
RC5
RC5 is a block cipher designed by Ronald Rivest in 1994 which, unlike many other ciphers, has a variable block size (32, 64 or 128 bits), key size (0 to 2040 bits) and number of rounds (0 to 255). The original suggested choice of parameters were a block size of 64 bits, a 128-bit key and 12 rounds.
A key feature of RC5 is the use of data-dependent rotations; one of the goals of RC5 was to prompt the study and evaluation of such operations as a cryptographic primitive. RC5 also consists of a number of modular additions and XORs. The general structure of the algorithm is a Feistel-like network. The encryption and decryption routines can be specified in a few lines of code. The key schedule, however, is more complex, expanding the key using an essentially one-way function with the binary expansions of both e and the golden ratio as sources of "nothing up my sleeve numbers". The tantalising simplicity of the algorithm together with the novelty of the data-dependent rotations has made RC5 an attractive object of study for cryptanalysts.
12-round RC5 (with 64-bit blocks) is susceptible to a differential attack using 244 chosen plaintexts. 18–20 rounds are suggested as sufficient protection.
Rijndael / AES
DES has been superseded as a United States Federal Standard by the AES, adopted by NIST in 2001 after a 5-year public competition. The cipher was developed by two Belgian cryptographers, Joan Daemen and Vincent Rijmen, and submitted under the name Rijndael.
AES has a fixed block size of 128 bits and a key size of 128, 192, or 256 bits, whereas Rijndael can be specified with block and key sizes in any multiple of 32 bits, with a minimum of 128 bits. The blocksize has a maximum of 256 bits, but the keysize has no theoretical maximum. AES operates on a 4×4 column-major order matrix of bytes, termed the state (versions of Rijndael with a larger block size have additional columns in the state).
Blowfish
Blowfish is a block cipher, designed in 1993 by Bruce Schneier and included in a large number of cipher suites and encryption products. Blowfish has a 64-bit block size and a variable key length from 1 bit up to 448 bits. It is a 16-round Feistel cipher and uses large key-dependent S-boxes. Notable features of the design include the key-dependent S-boxes and a highly complex key schedule.
Schneier designed Blowfish as a general-purpose algorithm, intended as an alternative to the ageing DES and free of the problems and constraints associated with other algorithms. At the time Blowfish was released, many other designs were proprietary, encumbered by patents or were commercial/government secrets. Schneier has stated that, "Blowfish is unpatented, and will remain so in all countries. The algorithm is hereby placed in the public domain, and can be freely used by anyone." Blowfish provides a good encryption rate in software and no effective cryptanalysis of the full-round version has been found to date.
Tweakable block ciphers
M. Liskov, R. Rivest, and D. Wagner have described a generalized version of block ciphers called "tweakable" block ciphers. A tweakable block cipher accepts a second input called the tweak along with its usual plaintext or ciphertext input. The tweak, along with the key, selects the permutation computed by the cipher. If changing tweaks is sufficiently lightweight (compared with a usually fairly expensive key setup operation), then some interesting new operation modes become possible. The disk encryption theory article describes some of these modes.
Format-preserving encryption
Block ciphers traditionally work over a binary alphabet. That is, both the input and the output are binary strings, consisting of n zeroes and ones. In some situations, however, one may wish to have a block cipher that works over some other alphabet; for example, encrypting 16-digit credit card numbers in such a way that the ciphertext is also a 16-digit number might facilitate adding an encryption layer to legacy software. This is an example of format-preserving encryption. More generally, format-preserving encryption requires a keyed permutation on some finite language. This makes format-preserving encryption schemes a natural generalization of (tweakable) block ciphers. In contrast, traditional encryption schemes, such as CBC, are not permutations because the same plaintext can encrypt to multiple different ciphertexts, even when using a fixed key.
Relation to other cryptographic primitives
Block ciphers can be used to build other cryptographic primitives, such as those below. For these other primitives to be cryptographically secure, care has to be taken to build them the right way.
Just as block ciphers can be used to build hash functions, hash functions can be used to build block ciphers. Examples of such block ciphers are SHACAL, BEAR and LION.