
 | ||
In statistics and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term); thus the model is in the form of a stochastic difference equation.
Contents
- Definition
- Intertemporal effect of shocks
- Characteristic polynomial
- Graphs of ARp processes
- Example An AR1 process
- Explicit meandifference form of AR1 process
- Choosing the maximum lag
- Calculation of the AR parameters
- YuleWalker equations
- Estimation of AR parameters
- Spectrum
- AR0
- AR1
- AR2
- Implementations in statistics packages
- Impulse response
- n step ahead forecasting
- Evaluating the quality of forecasts
- References
Together with the moving-average (MA) model, it is a special case and key component of the more general ARMA and ARIMA models of time series, which have a more complicated stochastic structure; it is also a special case of the vector autoregressive model (VAR), which consists of a system of more than one stochastic difference equation.
Contrary to the moving-average model, the autoregressive model is not always stationary as it may contain a unit root.
Definition
The notation
where
so that, moving the summation term to the left side and using polynomial notation, we have
An autoregressive model can thus be viewed as the output of an all-pole infinite impulse response filter whose input is white noise.
Some parameter constraints are necessary for the model to remain wide-sense stationary. For example, processes in the AR(1) model with
Intertemporal effect of shocks
In an AR process, a one-time shock affects values of the evolving variable infinitely far into the future. For example, consider the AR(1) model
Because each shock affects X values infinitely far into the future from when they occur, any given value Xt is affected by shocks occurring infinitely far into the past. This can also be seen by rewriting the autoregression
(where the constant term has been suppressed by assuming that the variable has been measured as deviations from its mean) as
When the polynomial division on the right side is carried out, the polynomial in the backshift operator applied to
Characteristic polynomial
The autocorrelation function of an AR(p) process can be expressed as
where
where B is the backshift operator, where
The autocorrelation function of an AR(p) process is a sum of decaying exponentials.
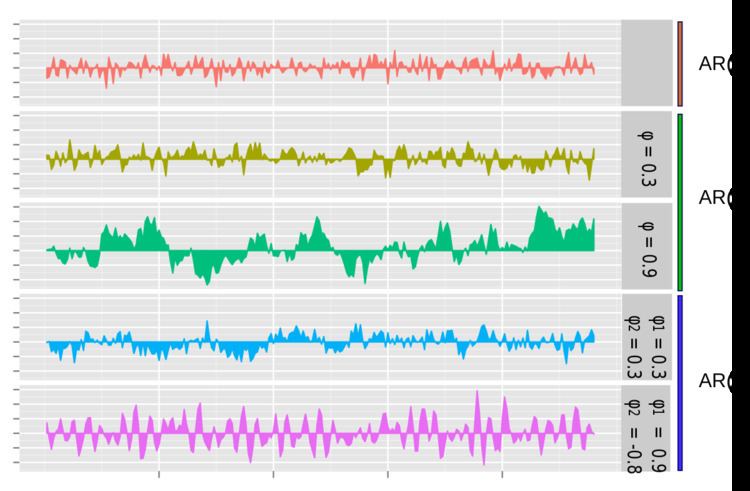
Graphs of AR(p) processes
The simplest AR process is AR(0), which has no dependence between the terms. Only the error/innovation/noise term contributes to the output of the process, so in the figure, AR(0) corresponds to white noise.
For an AR(1) process with a positive
For an AR(2) process, the previous two terms and the noise term contribute to the output. If both
Example: An AR(1) process
An AR(1) process is given by:
where
that
and hence
In particular, if
The variance is
where
and then by noticing that the quantity above is a stable fixed point of this relation.
The autocovariance is given by
It can be seen that the autocovariance function decays with a decay time (also called time constant) of
The spectral density function is the Fourier transform of the autocovariance function. In discrete terms this will be the discrete-time Fourier transform:
This expression is periodic due to the discrete nature of the
which yields a Lorentzian profile for the spectral density:
where
An alternative expression for
For N approaching infinity,
It is seen that
Explicit mean/difference form of AR(1) process
The AR(1) model is the discrete time analogy of the continuous Ornstein-Uhlenbeck process. It is therefore sometimes useful to understand the properties of the AR(1) model cast in an equivalent form. In this form, the AR(1) model is given by:
By putting this in the form
Choosing the maximum lag
The partial autocorrelation of an AR(p) process is zero at lag p + 1 and greater, so the appropriate maximum lag is the one beyond which the partial autocorrelations are all zero.
Calculation of the AR parameters
There are many ways to estimate the coefficients, such as the ordinary least squares procedure or method of moments (through Yule–Walker equations).
The AR(p) model is given by the equation
It is based on parameters
Yule–Walker equations
The Yule–Walker equations, named for Udny Yule and Gilbert Walker, are the following set of equations.
where m = 0, ..., p, yielding p + 1 equations. Here
Because the last part of an individual equation is non-zero only if m = 0, the set of equations can be solved by representing the equations for m > 0 in matrix form, thus getting the equation
which can be solved for all
which, once
An alternative formulation is in terms of the autocorrelation function. The AR parameters are determined by the first p+1 elements
Examples for some Low-order AR(p) processes
Estimation of AR parameters
The above equations (the Yule–Walker equations) provide several routes to estimating the parameters of an AR(p) model, by replacing the theoretical covariances with estimated values. Some of these variants can be described as follows:
Other possible approaches to estimation include maximum likelihood estimation. Two distinct variants of maximum likelihood are available: in one (broadly equivalent to the forward prediction least squares scheme) the likelihood function considered is that corresponding to the conditional distribution of later values in the series given the initial p values in the series; in the second, the likelihood function considered is that corresponding to the unconditional joint distribution of all the values in the observed series. Substantial differences in the results of these approaches can occur if the observed series is short, or if the process is close to non-stationarity.
Spectrum
The power spectral density of an AR(p) process with noise variance
AR(0)
For white noise (AR(0))
AR(1)
For AR(1)
AR(2)
AR(2) processes can be split into three groups depending on the characteristics of their roots:
Otherwise the process has real roots, and:
The process is non-stationary when the roots are outside the unit circle. The process is stable when the roots are within the unit circle, or equivalently when the coefficients are in the triangle
The full PSD function can be expressed in real form as:
Implementations in statistics packages
Impulse response
The impulse response of a system is the change in an evolving variable in response to a change in the value of a shock term k periods earlier, as a function of k. Since the AR model is a special case of the vector autoregressive model, the computation of the impulse response in Vector autoregression#Impulse response applies here.
n-step-ahead forecasting
Once the parameters of the autoregression
have been estimated, the autoregression can be used to forecast an arbitrary number of periods into the future. First use t to refer to the first period for which data is not yet available; substitute the known prior values Xt-i for i=1, ..., p into the autoregressive equation while setting the error term
There are four sources of uncertainty regarding predictions obtained in this manner: (1) uncertainty as to whether the autoregressive model is the correct model; (2) uncertainty about the accuracy of the forecasted values that are used as lagged values in the right side of the autoregressive equation; (3) uncertainty about the true values of the autoregressive coefficients; and (4) uncertainty about the value of the error term
Evaluating the quality of forecasts
The predictive performance of the autoregressive model can be assessed as soon as estimation has been done if cross-validation is used. In this approach, some of the initially available data was used for parameter estimation purposes, and some (from available observations later in the data set) was held back for out-of-sample testing. Alternatively, after some time has passed after the parameter estimation was conducted, more data will have become available and predictive performance can be evaluated then using the new data.
In either case, there are two aspects of predictive performance that can be evaluated: one-step-ahead and n-step-ahead performance. For one-step-ahead performance, the estimated parameters are used in the autoregressive equation along with observed values of X for all periods prior to the one being predicted, and the output of the equation is the one-step-ahead forecast; this procedure is used to obtain forecasts for each of the out-of-sample observations. To evaluate the quality of n-step-ahead forecasts, the forecasting procedure in the previous section is employed to obtain the predictions.
Given a set of predicted values and a corresponding set of actual values for X for various time periods, a common evaluation technique is to use the mean squared prediction error; other measures are also available (see Forecasting#Forecasting accuracy).
The question of how to interpret the measured forecasting accuracy arises—for example, what is a "high" (bad) or a "low" (good) value for the mean squared prediction error? There are two possible points of comparison. First, the forecasting accuracy of an alternative model, estimated under different modeling assumptions or different estimation techniques, can be used for comparison purposes. Second, the out-of-sample accuracy measure can be compared to the same measure computed for the in-sample data points (that were used for parameter estimation) for which enough prior data values are available (that is, dropping the first p data points, for which p prior data points are not available). Since the model was estimated specifically to fit the in-sample points as well as possible, it will usually be the case that the out-of-sample predictive performance will be poorer than the in-sample predictive performance. But if the predictive quality deteriorates out-of-sample by "not very much" (which is not precisely definable), then the forecaster may be satisfied with the performance.