
 | ||
In probability theory and statistics, a Gaussian process (also known as kriging) is a statistical model where observations occur in a continuous domain, e.g. time or space. In a Gaussian process, every point in some continuous input space is associated with a normally distributed random variable. Moreover, every finite collection of those random variables has a multivariate normal distribution. The distribution of a Gaussian process is the joint distribution of all those (infinitely many) random variables, and as such, it is a distribution over functions with a continuous domain, e.g. time or space.
Contents
- Definition
- Alternative definitions
- Covariance functions
- Usual covariance functions
- Brownian Motion as the Integral of Gaussian processes
- Applications
- Gaussian process prediction or kriging
- References
Viewed as a machine-learning algorithm, a Gaussian process uses lazy learning and a measure of the similarity between points (this is the kernel function) to predict the value for an unseen point from training data. The prediction is not just an estimate for that point, but also has uncertainty information -- it is a one-dimensional Gaussian distribution (which is the marginal distribution at that point).
For some kernel functions, matrix algebra can be used to calculate the predictions, as described in the kriging article. When a parameterised kernel is used, optimisation software is typically used to fit a Gaussian process model.
The concept of Gaussian processes is named after Carl Friedrich Gauss because it is based on the notion of the Gaussian distribution (normal distribution). Gaussian processes can be seen as an infinite-dimensional generalization of multivariate normal distributions.
Gaussian processes are useful in statistical modelling, benefiting from properties inherited from the normal. For example, if a random process is modelled as a Gaussian process, the distributions of various derived quantities can be obtained explicitly. Such quantities include the average value of the process over a range of times and the error in estimating the average using sample values at a small set of times.
Definition
A Gaussian process is a statistical distribution Xt, t ∈ T, for which any finite linear combination of samples has a joint Gaussian distribution. More accurately, any linear functional applied to the sample function Xt will give a normally distributed result. Notation-wise, one can write X ~ GP(m,K), meaning the random function X is distributed as a GP with mean function m and covariance function K. When the input vector t is two- or multi-dimensional, a Gaussian process might be also known as a Gaussian random field.
Some authors assume the random variables Xt have mean zero; this simplifies calculations without loss of generality and allows the mean square properties of the process to be entirely determined by the covariance function K.
Alternative definitions
Alternatively, a time continuous stochastic process is Gaussian if and only if for every finite set of indices
is a multivariate Gaussian random variable. Using characteristic functions of random variables, the Gaussian property can be formulated as follows:
where
The numbers
Covariance functions
A key fact of Gaussian processes is that they can be completely defined by their second-order statistics. Thus, if a Gaussian process is assumed to have mean zero, defining the covariance function completely defines the process' behaviour. Importantly the non-negative definiteness of this function enables its spectral decomposition using the Karhunen–Loeve expansion. Basic aspects that can be defined through the covariance function are the process' stationarity, isotropy, smoothness and periodicity.
Stationarity refers to the process' behaviour regarding the separation of any two points x and x' . If the process is stationary, it depends on their separation, x − x', while if non-stationary it depends on the actual position of the points x and x'. For example, the special case of an Ornstein–Uhlenbeck process, a Brownian motion process, is stationary.
If the process depends only on |x − x'|, the Euclidean distance (not the direction) between x and x', then the process is considered isotropic. A process that is concurrently stationary and isotropic is considered to be homogeneous; in practice these properties reflect the differences (or rather the lack of them) in the behaviour of the process given the location of the observer.
Ultimately Gaussian processes translate as taking priors on functions and the smoothness of these priors can be induced by the covariance function. If we expect that for "near-by" input points x and x' their corresponding output points y and y' to be "near-by" also, then the assumption of continuity is present. If we wish to allow for significant displacement then we might choose a rougher covariance function. Extreme examples of the behaviour is the Ornstein–Uhlenbeck covariance function and the squared exponential where the former is never differentiable and the latter infinitely differentiable.
Periodicity refers to inducing periodic patterns within the behaviour of the process. Formally, this is achieved by mapping the input x to a two dimensional vector u(x) = (cos(x), sin(x)).
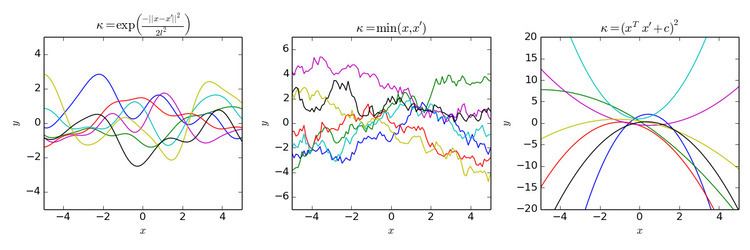
Usual covariance functions
There are a number of common covariance functions:
Here
Clearly, the inferential results are dependent on the values of the hyperparameters θ (e.g.
Brownian Motion as the Integral of Gaussian processes
A Wiener process (aka Brownian motion) is the integral of a white noise Gaussian process. It is not stationary, but it has stationary increments.
The Ornstein–Uhlenbeck process is a stationary Gaussian process.
The Brownian bridge is the integral of a Gaussian process whose increments are not independent.
The fractional Brownian motion is the integral of a Gaussian process whose covariance function is a generalisation of Wiener process.
Applications
A Gaussian process can be used as a prior probability distribution over functions in Bayesian inference. Given any set of N points in the desired domain of your functions, take a multivariate Gaussian whose covariance matrix parameter is the Gram matrix of your N points with some desired kernel, and sample from that Gaussian.
Inference of continuous values with a Gaussian process prior is known as Gaussian process regression, or kriging; extending Gaussian process regression to multiple target variables is known as cokriging. Gaussian processes are thus useful as a powerful non-linear multivariate interpolation tool. Gaussian process regression can be further extended to address learning tasks in both supervised (e.g. probabilistic classification) and unsupervised (e.g. manifold learning) learning frameworks.
Gaussian process prediction, or kriging
When concerned with a general Gaussian process regression problem (kriging), it is assumed that for a Gaussian process f observed at coordinates x, the vector of values
and maximizing this marginal likelihood towards θ provides the complete specification of the Gaussian process f. One can briefly note at this point that the first term corresponds to a penalty term for a model's failure to fit observed values and the second term to a penalty term that increases proportionally to a model's complexity. Having specified θ making predictions about unobserved values
and the posterior variance estimate B is defined as:
where