
Developer(s) DATADVANCE LLC Available in English | Development status Active License Proprietary | |
 | ||
Stable release 6.10 / January 11, 2017; 2 months ago (2017-01-11) Operating system | ||
pSeven is a design space exploration software platform developed by DATADVANCE LLC, extending design, simulation and analysis capabilities and assisting in smarter and faster design decisions. It provides a seamless integration with third party CAD and CAE software tools, powerful multi-objective and robust optimization algorithms, data analysis and uncertainty management tools. pSeven comes under the notion of PIDO (Process Integration and Design Optimization) software. Design space exploration functionality is based on the mathematical algorithms of pSeven Core (formerly known as MACROS) software library, also developed by DATADVANCE.
Contents
- History
- Functionality
- Process integration
- Design space exploration
- Design of experiments
- Sensitivity and dependency analysis
- Surrogate modeling
- Data fusion
- Optimization
- Uncertainty management
- Visualization and post processing
- Application areas and customers
- Modules and Packs
- References
Design Space Exploration with pSeven allows creating predictive modes, integrating CAD/CAE tools, identify models, analyze data and models, explore design alternatives and make smart decisions. SmartSelection technology implemented in pSeven Core automatically selects the most efficient method for a given data or optimization problem that makes advance math easy to use to a wide range of experts.
History
The foundation for the pSeven Core library as pSeven's background was laid in 2003, when the researchers from the Institute for Information Transmission Problems of the Russian Academy of Sciences started collaborating with Airbus Group to perform R&D in the domains of simulation and data analysis. The first version of pSeven Core library was created in association with EADS Innovation Works in 2009. Since 2012, pSeven software platform for simulation automation, data analysis and optimization is developed and marketed by DATADVANCE, incorporating pSeven Core.
Functionality
pSeven's functionality includes three major blocks: Process integration, Design Space Exploration, Vizualisation and Post-processing.
Process integration
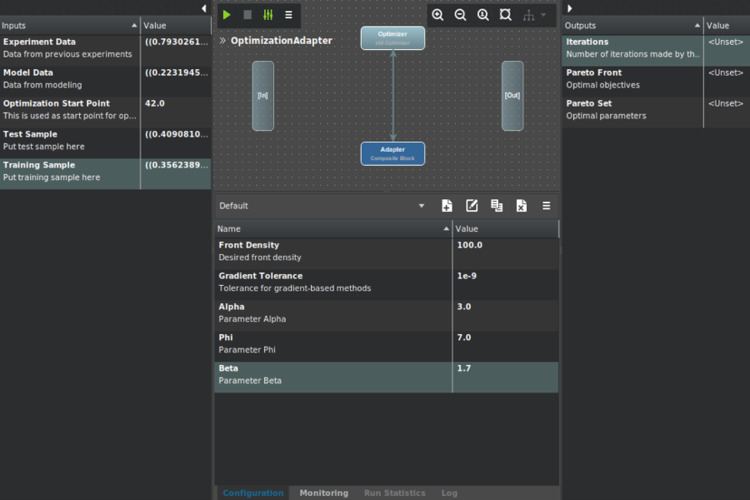
Process integration capabilities are used to capture the design process by automating single simulation, trade-off studies and design space exploration. For that, pSeven provides tools to build and automatically run the workflow, to configure and share workflows with other design team members, to distribute computation over different computing resources, including HPC. Main process integration tools of pSeven:
Design space exploration
Design Space Exploration toolset in pSeven offers a variety of methods for:
Design of experiments
Design of Experiments includes the following techniques: Space Filling
Optimal Designs for RSM
Adaptive DoE with Uniform, Maximum Variance and Integrated Mean Squared Errors Gain - Maximum Variance criteria.
Design of Experiments allows controlling the process of surrogate modeling via adaptive sampling plan, which benefits quality of approximation. As a result, it ensures time and resource saving on experiments and smarter decision-making based on the detailed knowledge of the design space.
Sensitivity and dependency analysis
Sensitivity and Dependency Analysis is used to filter non-informative design parameters in the study, ranking the informative ones with respect to their influence on the given response function and selecting parameters that provide the best approximation. It is applied to better understand the variables affecting the design process. It comprises the following steps:
The techniques below are included in pSeven to perform Sensitivity and Dependency Analysis: Popular correlation coefficients:
Screening indices:
Sobol indices:
Taguchi scores:
Surrogate modeling
Surrogate modeling (or Approximation) capabilities in pSeven incorporate several proprietary surrogate modeling techniques, including methods for ordered and structured data, allowing to understand behavior of user's system with minimal costs, replace expensive computations by surrogate models (metamodels) and make smarter decisions based on detailed knowledge of the design space
These methods provide users with the following features:
"Smart Selection" automatically picks the best suitable technique based on a few user-defined problem settings. Surrogate modeling allows user getting value from experimental data and perform faster and cheaper system behavior analysis.
Data fusion
Data fusion in pSeven's functionality is used to better handle and increase efficiency of surrogate modeling. It allows constructing surrogate models using data of different levels of fidelity, handle samples of varied sizes and perform accuracy evaluation. It allows managing a surrogate model construction time, estimate uncertainty for predictions obtained with a Data Fusion-based surrogate model and estimate the quality of models constructed. Data Fusion technology works in two modes:
Data Fusion techniques available in pSeven:
Optimization
Optimization algorithms implemented in pSeven allow solving single and multiobjective constrained optimization problems as well as robust and reliability based design optimization problems. Users can solve both engineering optimization problems with cheap to evaluate semi-analytical models and the problems with expensive (in terms of CPU time) objective functions and constraints. Smart Selection technique automatically and adaptively selects the most suitable optimization algorithm for a given optimization problem from a pool of optimization methods and algorithms in pSeven. Main classes of optimization problems which are supported:
Optimization methods available in pSeven:
Uncertainty management
Uncertainty Management capabilities in pSeven are based on OpenTURNS library. They are used to improve the quality of products designed, manage potential risks at the design, manufacturing and operating stages and to guarantee product reliability. A range of uncertainty management algorithms allows to perform: Quantification of uncertainty sources (based on experimental data or expert knowledge)
Uncertainty propagation using Monte-Carlo simulation
Reliability analysis
Reliability-based design optimization
Visualization and post-processing
Visualization and post-processing tools in pSeven are used to analyze the results of design space exploration procedures and include:
Application areas and customers
pSeven's application areas are different industries such as aerospace, automotive, energy, electronics and electrical appliances, banking, insurance, biotechnology and others. Application examples:
Modules and Packs
Three pSeven configurations are available, each of them with different functionality modules: