
 | ||
In computer science, the longest repeated substring problem is the problem of finding the longest substring of a string that occurs at least twice.
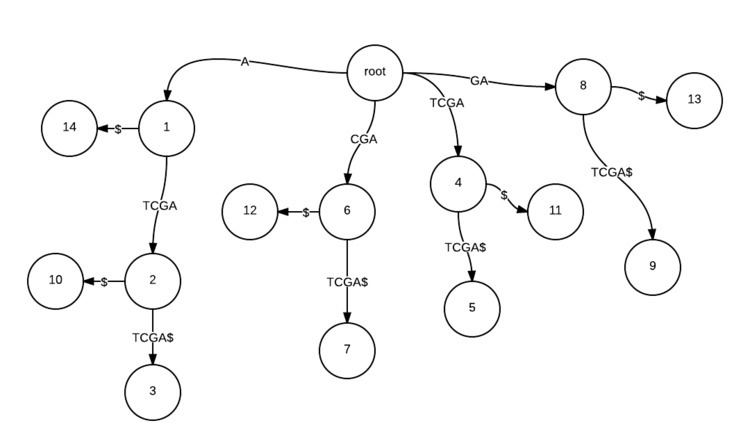
This problem can be solved in linear time and space [ Θ(n) ] by building a suffix tree for the string (with a special end-of-string symbol like '$' appended), and finding the deepest internal node in the tree. Depth is measured by the number of characters traversed from the root. The string spelled by the edges from the root to such a node is a longest repeated substring. The problem of finding the longest substring with at least
In the figure with the string "ATCGATCGA$", the longest substring that repeats at least twice is "ATCGA".