
 | ||
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation. The rise of lambda architecture is correlated with the growth of big data, real-time analytics, and the drive to mitigate the latencies of map-reduce.
Contents
- Overview
- Batch layer
- Speed layer
- Serving layer
- Optimizations
- Lambda architecture in use
- Criticism
- References
Lambda architecture depends on a data model with an append-only, immutable data source that serves as a system of record. It is intended for ingesting and processing timestamped events that are appended to existing events rather than overwriting them. State is determined from the natural time-based ordering of the data.
Overview
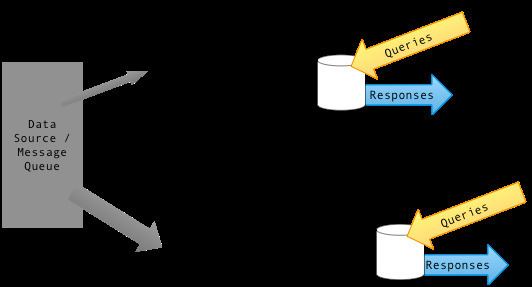
Lambda architecture describes a system consisting of three layers: batch processing, speed (or real-time) processing, and a serving layer for responding to queries. The processing layers ingest from an immutable master copy of the entire data set.
Batch layer
The batch layer precomputes results using a distributed processing system that can handle very large quantities of data. The batch layer aims at perfect accuracy by being able to process all available data when generating views. This means it can fix any errors by recomputing based on the complete data set, then updating existing views. Output is typically stored in a read-only database, with updates completely replacing existing precomputed views.
Apache Hadoop is the de facto standard batch-processing system used in most high-throughput architectures.
Speed layer
The speed layer processes data streams in real time and without the requirements of fix-ups or completeness. This layer sacrifices throughput as it aims to minimize latency by providing real-time views into the most recent data. Essentially, the speed layer is responsible for filling the "gap" caused by the batch layer's lag in providing views based on the most recent data. This layer's views may not be as accurate or complete as the ones eventually produced by the batch layer, but they are available almost immediately after data is received, and can be replaced when the batch layer's views for the same data become available.
Stream-processing technologies typically used in this layer include Apache Storm, SQLstream and Apache Spark. Output is typically stored on fast NoSQL databases.
Serving layer
Output from the batch and speed layers are stored in the serving layer, which responds to ad-hoc queries by returning precomputed views or building views from the processed data.
Examples of technologies used in the serving layer include Druid, which provides a single cluster to handle output from both layers. Dedicated stores used in the serving layer include Apache Cassandra or Apache HBase for speed-layer output, and Elephant DB or Cloudera Impala for batch-layer output.
Optimizations
To optimize the data set and improve query efficiency, various rollup and aggregation techniques are executed on raw data, while estimation techniques are employed to further reduce computation costs. And while expensive full recomputation is required for fault tolerance, incremental computation algorithms may be selectively added to increase efficiency, and techniques such as partial computation and resource-usage optimizations can effectively help lower latency.
Lambda architecture in use
Metamarkets, which provides analytics for companies in the programmatic advertising space, employs a version of the lambda architecture that uses Druid for storing and serving both the streamed and batch-processed data.
For running analytics on its advertising data warehouse, Yahoo has taken a similar approach, also using Apache Storm, Apache Hadoop, and Druid.
The Netflix Suro project has separate processing paths for data, but does not strictly follow lambda architecture since the paths may be intended to serve different purposes and not necessarily to provide the same type of views. Nevertheless, the overall idea is to make selected real-time event data available to queries with very low latency, while the entire data set is also processed via a batch pipeline. The latter is intended for applications that are less sensitive to latency and require a map-reduce type of processing.
Criticism
Criticism of lambda architecture has focused on its inherent complexity and its limiting influence. The batch and streaming sides each require a different code base that must be maintained and kept in sync so that processed data produces the same result from both paths. Yet attempting to abstract the code bases into a single framework puts many of the specialized tools in the batch and real-time ecosystems out of reach.
In a technical discussion over the merits of employing a pure streaming approach, it was noted that using a flexible streaming framework such as Apache Samza could provide some of the same benefits as batch processing without the latency. Such a streaming framework could allow for collecting and processing arbitrarily large windows of data, accommodate blocking, and handle state.