
 | ||
In mathematical optimization, the Karush–Kuhn–Tucker (KKT) conditions, also known as the Kuhn–Tucker conditions, are first-order necessary conditions for a solution in nonlinear programming to be optimal, provided that some regularity conditions are satisfied. Allowing inequality constraints, the KKT approach to nonlinear programming generalizes the method of Lagrange multipliers, which allows only equality constraints. The system of equations corresponding to the KKT conditions is usually not solved directly, except in the few special cases where a closed-form solution can be derived analytically. In general, many optimization algorithms can be interpreted as methods for numerically solving the KKT system of equations.
Contents
- Nonlinear optimization problem
- Necessary conditions
- Regularity conditions or constraint qualifications
- Sufficient conditions
- Second order sufficient conditions
- Economics
- Value function
- Generalizations
- References
The KKT conditions were originally named after Harold W. Kuhn, and Albert W. Tucker, who first published the conditions in 1951. Later scholars discovered that the necessary conditions for this problem had been stated by William Karush in his master's thesis in 1939.
Nonlinear optimization problem
Consider the following nonlinear optimization problem:
Minimizewhere x is the optimization variable,
Necessary conditions
Suppose that the objective function
In the particular case
If some of the functions are non-differentiable, subdifferential versions of Karush–Kuhn–Tucker (KKT) conditions are available.
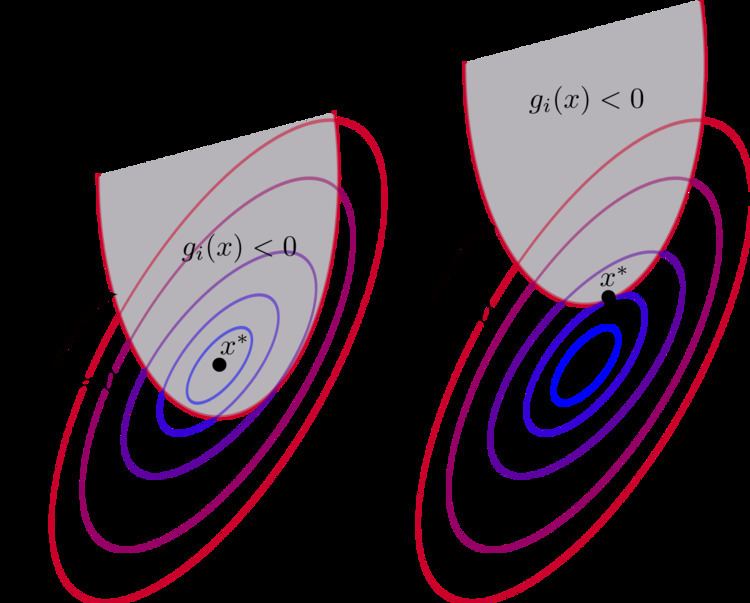
Regularity conditions (or constraint qualifications)
In order for a minimum point
(
It can be shown that
LICQ⇒MFCQ⇒CPLD⇒QNCQ
and
LICQ⇒CRCQ⇒CPLD⇒QNCQ
(and the converses are not true), although MFCQ is not equivalent to CRCQ. In practice weaker constraint qualifications are preferred since they provide stronger optimality conditions.
Sufficient conditions
In some cases, the necessary conditions are also sufficient for optimality. In general, the necessary conditions are not sufficient for optimality and additional information is necessary, such as the Second Order Sufficient Conditions (SOSC). For smooth functions, SOSC involve the second derivatives, which explains its name.
The necessary conditions are sufficient for optimality if the objective function
It was shown by Martin in 1985 that the broader class of functions in which KKT conditions guarantees global optimality are the so-called Type 1 invex functions.
Second-order sufficient conditions
For smooth, non-linear optimisation problems, a second order sufficient condition is given as follows. Consider
the following equation must hold;
If the above condition is strictly met, the function is a strict constrained local minimum.
Economics
Often in mathematical economics the KKT approach is used in theoretical models in order to obtain qualitative results. For example, consider a firm that maximizes its sales revenue subject to a minimum profit constraint. Letting Q be the quantity of output produced (to be chosen), R(Q) be sales revenue with a positive first derivative and with a zero value at zero output, C(Q) be production costs with a positive first derivative and with a non-negative value at zero output, and
and the KKT conditions are
Since Q = 0 would violate the minimum profit constraint, we have Q > 0 and hence the third condition implies that the first condition holds with equality. Solving that equality gives
Because it was given that
Value function
If we reconsider the optimization problem as a maximization problem with constant inequality constraints,v.
The value function is defined as
(So the domain of V is
Given this definition, each coefficient,
Generalizations
With an extra constant multiplier
which are called the Fritz John conditions.
The KKT conditions belong to a wider class of the first-order necessary conditions (FONC), which allow for non-smooth functions using subderivatives.