
 | ||
In statistics, inter-rater reliability, inter-rater agreement, or concordance is the degree of agreement among raters. It gives a score of how much homogeneity, or consensus, there is in the ratings given by judges. It is useful in refining the tools given to human judges, for example by determining if a particular scale is appropriate for measuring a particular variable. If various raters do not agree, either the scale is defective or the raters need to be re-trained.
Contents
- The philosophy of inter rater agreement
- Joint probability of agreement
- Kappa statistics
- Correlation coefficients
- Intra class correlation coefficient
- Limits of agreement
- Krippendorffs Alpha
- References
There are a number of statistics which can be used to determine inter-rater reliability. Different statistics are appropriate for different types of measurement. Some options are: joint-probability of agreement, Cohen's kappa and the related Fleiss' kappa, inter-rater correlation, concordance correlation coefficient and intra-class correlation.
The philosophy of inter-rater agreement
There are several operational definitions [1] of "inter-rater reliability" in use by Examination Boards, reflecting different viewpoints about what is reliable agreement between raters.
There are three operational definitions of agreement:
- Reliable raters agree with the "official" rating of a performance.
- Reliable raters agree with each other about the exact ratings to be awarded.
- Reliable raters agree about which performance is better and which is worse.
These combine with two operational definitions of behavior:
Joint probability of agreement
The joint-probability of agreement is probably the most simple and least robust measure. It is the number of times each rating (e.g. 1, 2, ... 5) is assigned by each rater divided by the total number of ratings. It assumes that the data are entirely nominal. It does not take into account that agreement may happen solely based on chance. Some question, though, whether there is a need to 'correct' for chance agreement; and suggest that, in any case, any such adjustment should be based on an explicit model of how chance and error affect raters' decisions.[3]
When the number of categories being used is small (e.g. 2 or 3), the likelihood for 2 raters to agree by pure chance increases dramatically. This is because both raters must confine themselves to the limited number of options available, which impacts the overall agreement rate, and not necessarily their propensity for "intrinsic" agreement (an agreement is considered "intrinsic" if it is not due to chance). Therefore, the joint probability of agreement will remain high even in the absence of any "intrinsic" agreement among raters[4]. A useful inter-rater reliability coefficient is expected (a) to be close to 0, when there is no "intrinsic" agreement, and (b) to increase as the "intrinsic" agreement rate improves. Most chance-corrected agreement coefficients achieve the first objective[5]. However, the second objective is not achieved by many known chance-corrected measures[6].
Kappa statistics
Cohen's kappa[7], which works for two raters, and Fleiss' kappa[8], an adaptation that works for any fixed number of raters, improve upon the joint probability in that they take into account the amount of agreement that could be expected to occur through chance. They suffer from the same problem as the joint-probability in that they treat the data as nominal and assume the ratings have no natural ordering. If the data do have an order, the information in the measurements is not fully taken advantage of.
Correlation coefficients
Either Pearson's
Intra-class correlation coefficient
Another way of performing reliability testing is to use the intra-class correlation coefficient (ICC) [9]. There are several types of this and one is defined as, "the proportion of variance of an observation due to between-subject variability in the true scores".[10] The range of the ICC may be between 0.0 and 1.0 (an early definition of ICC could be between −1 and +1). The ICC will be high when there is little variation between the scores given to each item by the raters, e.g. if all raters give the same, or similar scores to each of the items. The ICC is an improvement over Pearson's
Limits of agreement
Another approach to agreement (useful when there are only two raters and the scale is continuous) is to calculate the differences between each pair of the two raters' observations. The mean of these differences is termed bias and the reference interval (mean +/- 1.96 x standard deviation) is termed limits of agreement. The limits of agreement provide insight into how much random variation may be influencing the ratings. If the raters tend to agree, the differences between the raters' observations will be near zero. If one rater is usually higher or lower than the other by a consistent amount, the bias (mean of differences) will be different from zero. If the raters tend to disagree, but without a consistent pattern of one rating higher than the other, the mean will be near zero. Confidence limits (usually 95%) can be calculated for both the bias and each of the limits of agreement.
There are several formulae that can be used to calculate limits of agreement. The simple formula, which was given in the previous paragraph and works well for sample size greater than 60[11], is
For smaller sample sizes, another common simplification[12] is
However, the most accurate formula (which is applicable for all sample sizes)[13] is
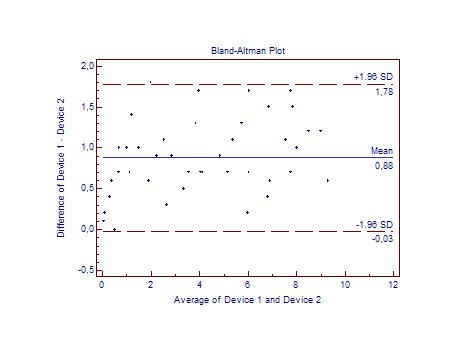
Bland and Altman [14] have expanded on this idea by graphing the difference of each point, the mean difference, and the limits of agreement on the vertical against the average of the two ratings on the horizontal. The resulting Bland–Altman plot demonstrates not only the overall degree of agreement, but also whether the agreement is related to the underlying value of the item. For instance, two raters might agree closely in estimating the size of small items, but disagree about larger items.
When comparing two methods of measurement it is not only of interest to estimate both bias and limits of agreement between the two methods (inter-rater agreement), but also to assess these characteristics for each method within itself (intra-rater agreement). It might very well be that the agreement between two methods is poor simply because one of the methods has wide limits of agreement while the other has narrow. In this case the method with the narrow limits of agreement would be superior from a statistical point of view, while practical or other considerations might change this appreciation. What constitutes narrow or wide limits of agreement or large or small bias is a matter of a practical assessment in each case.
Krippendorff’s Alpha
Krippendorff's alpha[15] is a versatile statistic that assesses the agreement achieved among observers who categorize, evaluate, or measure a given set of objects in terms of the values of a variable. It generalizes several specialized agreement coefficients by accepting any number of observers, being applicable to nominal, ordinal, interval, and ratio levels of measurement, being able to handle missing data, and being corrected for small sample sizes. Alpha emerged in content analysis where textual units are categorized by trained coders and is used in counseling and survey research where experts code open-ended interview data into analyzable terms, in psychometrics where individual attributes are tested by multiple methods, in observational studies where unstructured happenings are recorded for subsequent analysis, and in computational linguistics where texts are annotated for various syntactic and semantic qualities.