
Authors | Release date 2009 | |
 | ||
Description Convergence towards a standard set of gene annotations Research center National Center for Biotechnology InformationEuropean Bioinformatics InstituteUniversity of California, Santa CruzWellcome Trust Sanger Institute Primary citation Pruitt KD, et al (2009) | ||
The Consensus Coding Sequence (CCDS) Project is a collaborative effort to maintain a dataset of protein-coding regions that are identically annotated on the human and mouse reference genome assemblies. The CCDS project tracks identical protein annotations on the reference mouse and human genomes with a stable identifier (CCDS ID), and ensures that they are consistently represented by the National Center for Biotechnology Information (NCBI), Ensembl, and UCSC Genome Browser. The integrity of the CCDS dataset is maintained through stringent quality assurance testing and on-going manual curation.
Contents
Motivation and background
Biological and biomedical research has come to rely on accurate and consistent annotation of genes and their products on genome assemblies. Reference annotations of genomes are available from various sources, each with their own independent goals and policies, which results in some annotation variation.
The CCDS project was established to identify a gold standard set of protein-coding gene annotations that are identically annotated on the human and mouse reference genome assemblies by the participating annotation groups. The CCDS gene sets that have been arrived at by consensus of the different partners now consist of over 18,000 human and over 20,000 mouse genes (see CCDS release history). The CCDS dataset is increasingly representing more alternative splicing events with each new release.
Contributing groups
Participating annotation groups include:
Manual annotation is provided by:
Defining the CCDS gene set
"Consensus" is defined as protein-coding regions that agree at the start codon, stop codon, and splice junctions, and for which the prediction meets quality assurance benchmarks. A combination of manual and automated genome annotations provided by (NCBI) and Ensembl (which incorporates manual HAVANA annotations) are compared to identify annotations with matching genomic coordinates.
Quality assurance testing
In order to ensure that CDSs are of high quality, multiple quality assurance (QA) tests are performed (Table 1). All tests are performed following the annotation comparison step of each CCDS build and are independent of individual annotation group QA tests performed prior to the annotation comparison.
Annotations that fail QA tests undergo a round of manual checking that may improve results or reach a decision to reject annotation matches based on QA failure.
Review process
The CCDS database is unique in that the review process must be carried out by multiple collaborators, and agreement must be reached before any changes can be made. This is made possible with a collaborator coordination system that includes a work process flow and forums for analysis and discussion. The CCDS database operates an internal website that serves multiple purposes including curator communication, collaborator voting, providing special reports and tracking the status of CCDS representations. When a collaborating CCDS group member identifies a CCDS ID that may need review, a voting process is employed to decide on the final outcome.
Manual curation
Coordinated manual curation is supported by a restricted-access website and a discussion e-mail list. CCDS curation guidelines were established to address specific conflicts that were observed at a higher frequency. Establishment of CCDS curation guidelines has helped to make the CCDS curation process more efficient by reducing the number of conflicting votes and time spent in discussion to reach a consensus agreement. A link to the CCDS curation guidelines can be found here.
Curation policies established for the CCDS data set have been integrated in to the RefSeq and HAVANA annotation guidelines and thus, new annotations provided by both groups are more likely to be concordant and result in addition of a CCDS ID. These standards address specific problem areas, are not a comprehensive set of annotation guidelines, and do not restrict the annotation polices of any collaborating group. Examples include, standardized curation guidelines for selection of the initiation codon and interpretation of upstream ORFs and transcripts that are predicted to be candidates for nonsense-mediated decay. Curation occurs continuously, and any of the collaborating centers can flag a CCDS ID as a potential update or withdrawal.
Conflicting opinions are addressed by consulting with scientific experts or other annotation curation groups such as the HUGO Gene Nomenclature Committee (HGNC) and Mouse Genome Informatics (MGI). If a conflict cannot be resolved, then collaborators agree to withdraw the CCDS ID until more information becomes available.
Curation challenges and annotation guidelines
Nonsense-mediated decay (NMD): NMD is the most powerful mRNA surveillance process. NMD eliminates defective mRNA before it can be translated into protein. This is important because if the defective mRNA is translated, the truncated protein may cause disease. Different mechanisms have been proposed to explain NMD; one being the exon junction complex (EJC) model. In this model, if the stop codon is >50 nt upstream of the last exon-exon junction, the transcript is assumed to be a NMD candidate. The CCDS collaborators utilise a conservative method, based on the EJC model, to screen mRNA transcripts. Any transcripts determined to be NMD candidates are excluded from the CCDS data set except in the following situations:
- all transcripts at one particular locus are assessed to be NMD candidates however the locus is previously known to be protein coding region;
- there is experimental evidence suggesting that a functional protein is produced from the NMD candidate transcript.
Previously, NMD candidate transcripts were considered to be protein coding transcripts by both RefSeq and HAVANA, and thereby, these NMD candidate transcripts were represented in the CCDS data set. The RefSeq group and the HAVANA project have subsequently revised their annotation policies.
Multiple in-frame translation start sites: Multiple factors contribute to translation initiation, such as upstream open reading frames (uORFs), secondary structure and the sequence context around the translation initiation site. A common start site is defined within Kozak consensus sequence: (GCC) GCCACCAUGG in vertebrates. The sequence in brackets (GCC) is the motif with unknown biological impact. There are variations within Kozak consensus sequence, such as G or A is observed three nucleotides upstream (at position -3) of AUG. Bases between positions -3 and +4 of Kozak sequence have the most significant impact on translational efficiency. Hence, a sequence (A/G)NNAUGG is defined as a strong Kozak signal in the CCDS project.
According to the scanning mechanism, the small ribosomal subunit can initiate translation from the first reached start codon. There are exceptions to the scanning model:
- when the initiation site is not surrounded by a strong Kozak signal, which results in leaky scanning. Thereby, the ribosome skips this AUG and initiates translation from a downstream start site;
- when a shorter ORF can allow the ribosome to re-initiate translation at a downstream ORF.
According to the CCDS annotation guidelines, the longest ORF must be annotated except when there is experimental evidence that an internal start site is used to initiate translation. Additionally, other types of new data, such as ribosome profiling data, can be used to identify start codons. The CCDS data set records one translation initiation site per CCDS ID. Any alternative start sites may be used for translation and will be stated in a CCDS public note.
Upstream open reading frames: AUG initiation codons located within transcript leaders are known as upstream AUGs (uAUGs). Sometimes, uAUGs are associated with uORFs . uORFs are found in approximately 50% of human and mouse transcripts. The existence of uORFs are another challenge for the CCDS data set. The scanning mechanism for translation initiation suggests that small ribosomal subunits (40S) bind at the 5’ end of a nascent mRNA transcript and scan for the first AUG start codon. It is possible that an uAUG is recognised first, and the corresponding uORF is then translated. The translated uORF could be a NMD candidate, although studies have shown that some uORFs can avoid NMD. The average size limit for uORFs that will escape NMD is approximately 35 amino acids. It also has been suggested that uORFs inhibit translation of the downstream gene by trapping a ribosome initiation complex and causing the ribosome to dissociate from the mRNA transcript before it reaches the protein-coding regions. Currently, no studies have reported the global impact of uORFs on translational regulation.
The current CCDS annotation guidelines allow the inclusion of mRNA transcripts containing uORFs if they meet the following two biological requirements:
- the mRNA transcript has a strong Kozak signal;
- the mRNA transcript is either ≥ 35 amino acids or overlaps with the primary open reading frame.
Read-through transcripts: Read-through transcripts are also known as conjoined genes or co-transcribed genes. Read-through transcripts are defined as transcripts combining at least part of one exon from each of two or more distinct known (partner) genes which lie on the same chromosome in the same orientation. The biological function of read-through transcripts and their corresponding protein molecules remain unknown. However, the definition of a read-through gene in the CCDS data set is that the individual partner genes must be distinct, and the read-through transcripts must share ≥ 1 exon (or ≥ 2 splice sites except in the case of a shared terminal exon) with each of the distinct shorter loci. Transcripts are not considered to be read-through transcripts in the following circumstances:
- when transcripts are produced from overlapping genes but do not share same splice sites;
- when transcripts are translated from genes that have nested structures relative to each other. In this instance, the CCDS collaborators and the HGNC have agreed that the read-through transcript be represented as a separate locus.
Quality of reference genome sequence: As the CCDS data set is built to represent genomic annotations of human and mouse, the quality problems with the human and mouse reference genome sequences become another challenge. Quality problems occur when the reference genome is misassembled. Thereby the misassembled genome may contain premature stop codons, frame-shift indels, or likely polymorphic pseudogenes. Once these quality problems are identified, the CCDS collaborators report the issues to the Genome Reference Consortium, which investigates and makes the necessary corrections.
Access to CCDS data
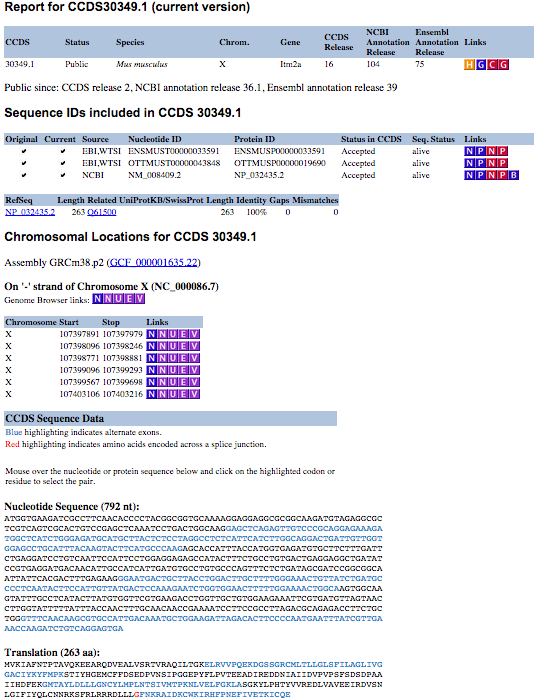
The CCDS project is available from the NCBI CCDS data set page (here), which provides FTP download links and a query interface to acquire information about CCDS sequences and locations. CCDS reports can be obtained by using the query interface, which is located at the top of the CCDS data set page. Users can select various types of identifiers such as CCDS ID, gene ID, gene symbol, nucleotide ID and protein ID to search for specific CCDS information. The CCDS reports (Figure 1) are presented in a table format, providing links to specific resources, such as a history report, Entrez Gene or re-query the CCDS data set. The sequence identifiers table presents transcript information in VEGA, Ensembl and Blink. The chromosome location table includes the genomic coordinates for each individual exon of the specific coding sequence. This table also provides links to several different genome browsers, which allow you to visualise the structure of the coding region. Exact nucleotide sequence and protein sequence of the specific coding sequence are also displayed in the section of CCDS sequence data.
Current applications
The CCDS dataset is an integral part of the GENCODE gene annotation project and it is used as a standard for high-quality coding exon definition in various research fields, including clinical studies, large-scale epigenomic studies, exome projects and exon array design. Due to the consensus annotation of CCDS exons by the independent annotation groups, exome projects in particular have regarded CCDS coding exons as reliable targets for downstream studies (e.g., for single nucleotide variant detection), and these exons have been used as coding region targets in commercially available exome kits.
CCDS release history
The CCDS data set size has continued to increase with both the computational genome annotation updates, which integrate new data sets submitted to the International Nucleotide Sequence Database Collaboration (INSDC), and on ongoing curation activities that supplement or improve upon that annotation. Table 2 summarises the key statistics for each CCDS build where Public CCDS IDs are all those that were not under review or pending an update or withdrawal at the time of the current release date.
The complete set of release statistics can be found at the official CCDS website on their Releases & Statistics page.
Future prospects
Long-term goals include the addition of attributes that indicate where transcript annotation is also identical (including the UTRs) and to indicate splice variants with different UTRs that have the same CCDS ID. It is also anticipated that as more complete and high-quality genome sequence data become available for other organisms, annotations from these organisms may be in scope for CCDS representation.
The CCDS set will become more complete as the independent curation groups agree on cases where they initially differ, as additional experimental validation of weakly supported genes occurs, and as automatic annotation methods continue to improve. Communication among the CCDS collaborating groups is ongoing and will resolve differences and identify refinements between CCDS update cycles. Human updates are expected to occur roughly every 6 months and mouse releases yearly.
Publications
The consensus coding sequence (CCDS) project: Identifying a common protein-coding gene set for the human and mouse genomes. Pruitt KD, Harrow J, Harte RA, Wallin C, Diekhans M, Maglott DR, Searle S, Farrell CM, Loveland JE, Ruef BJ, Hart E, Suner MM, Landrum MJ, Aken B, Ayling S, Baertsch R, Fernandez-Banet J, Cherry JL, Curwen V, Dicuccio M, Kellis M, Lee J, Lin MF, Schuster M, Shkeda A, Amid C, Brown G, Dukhanina O, Frankish A, Hart J, Maidak BL, Mudge J, Murphy MR, Murphy T, Rajan J, Rajput B, Riddick LD, Snow C, Steward C, Webb D, Weber JA, Wilming L, Wu W, Birney E, Haussler D, Hubbard T, Ostell J, Durbin R, Lipman D. Genome Res. 2009 Jul;19(7):1316-23. PMID 19498102
Tracking and coordinating an international curation effort for the CCDS Project. Harte RA, Farrell CM, Loveland JE, Suner MM, Wilming L, Aken B, Barrell D, Frankish A, Wallin C, Searle S, Diekhans M, Harrow J, Pruitt KD. Database 2012 Mar 20;2012:bas008. doi: 10.1093/database/bas008. PMID 22434842
Current status and new features of the Consensus Coding Sequence database. Farrell CM, O'Leary NA, Harte RA, Loveland JE, Wilming LG, Wallin C, Diekhans M, Barrell D, Searle SM, Aken B, Hiatt SM, Frankish A, Suner MM, Rajput B, Steward CA, Brown GR, Bennett R, Murphy M, Wu W, Kay MP, Hart J, Rajan J, Weber J, Snow C, Riddick LD, Hunt T, Webb D, Thomas M, Tamez P, Rangwala SH, McGarvey KM, Pujar S, Shkeda A, Mudge JM, Gonzalez JM, Gilbert JG, Trevanion SJ, Baertsch R, Harrow JL, Hubbard T, Ostell JM, Haussler D, Pruitt KD. Nucleic Acids Res. 2014 Jan 1;42(1):D865-72. doi: 10.1093/nar/gkt1059. PMID 24217909