
 | ||
In statistical inference, the concept of a confidence distribution (CD) has often been loosely referred to as a distribution function on the parameter space that can represent confidence intervals of all levels for a parameter of interest. Historically, it has typically been constructed by inverting the upper limits of lower sided confidence intervals of all levels, and it was also commonly associated with a fiducial interpretation (fiducial distribution), although it is a purely frequentist concept. A confidence distribution is NOT a probability distribution function of the parameter of interest, but may still be a function useful for making inferences.
Contents
- The history of CD concept
- Classical definition
- The modern definition
- Examples
- Confidence interval
- Point estimation
- Hypothesis testing
- References
In recent years, there has been a surge of renewed interest in confidence distributions. In the more recent developments, the concept of confidence distribution has emerged as a purely frequentist concept, without any fiducial interpretation or reasoning. Conceptually, a confidence distribution is no different from a point estimator or an interval estimator (confidence interval), but it uses a sample-dependent distribution function on the parameter space (instead of a point or an interval) to estimate the parameter of interest.
A simple example of a confidence distribution, that has been broadly used in statistical practice, is a bootstrap distribution. The development and interpretation of a bootstrap distribution does not involve any fiducial reasoning; the same is true for the concept of a confidence distribution. But the notion of confidence distribution is much broader than that of a bootstrap distribution. In particular, recent research suggests that it encompasses and unifies a wide range of examples, from regular parametric cases (including most examples of the classical development of Fisher's fiducial distribution) to bootstrap distributions, p-value functions, normalized likelihood functions and, in some cases, Bayesian priors and Bayesian posteriors.
Just as a Bayesian posterior distribution contains a wealth of information for any type of Bayesian inference, a confidence distribution contains a wealth of information for constructing almost all types of frequentist inferences, including point estimates, confidence intervals and p-values, among others. Some recent developments have highlighted the promising potentials of the CD concept, as an effective inferential tool.
The history of CD concept
Neyman (1937) introduced the idea of "confidence" in his seminal paper on confidence intervals which clarified the frequentist repetition property. According to Fraser, the seed (idea) of confidence distribution can even be traced back to Bayes (1763) and Fisher (1930). Some researchers view the confidence distribution as "the Neymanian interpretation of Fishers fiducial distribution", which was "furiously disputed by Fisher". It is also believed that these "unproductive disputes" and Fisher's "stubborn insistence" might be the reason that the concept of confidence distribution has been long misconstrued as a fiducial concept and not been fully developed under the frequentist framework. Indeed, the confidence distribution is a purely frequentist concept with a purely frequentist interpretation, and it also has ties to Bayesian inference concepts and the fiducial arguments.
Classical definition
Classically, a confidence distribution is defined by inverting the upper limits of a series of lower sided confidence intervals. In particular,
For every α in (0, 1), let (−∞, ξn(α)] be a 100α% lower-side confidence interval for θ, where ξn(α) = ξn(Xn,α) is continuous and increasing in α for each sample Xn. Then, Hn(•) = ξn−1(•) is a confidence distribution for θ.Efron stated that this distribution "assigns probability 0.05 to θ lying between the upper endpoints of the 0.90 and 0.95 confidence interval, etc." and "it has powerful intuitive appeal". In the classical literature, the confidence distribution function is interpreted as a distribution function of the parameter θ, which is impossible unless fiducial reasoning is involved since, in a frequentist setting, the parameters are fixed and nonrandom.
To interpret the CD function entirely from a frequentist viewpoint and not interpret it as a distribution function of a (fixed/nonrandom) parameter is one of the major departures of recent development relative to the classical approach. The nice thing about treating confidence distribution as a purely frequentist concept (similar to a point estimator) is that it is now free from those restrictive, if not controversial, constraints set forth by Fisher on fiducial distributions.
The modern definition
The following definition applies; Θ is the parameter space of the unknown parameter of interest θ, and χ is the sample space corresponding to data Xn={X1, ..., Xn}:
A function Hn(•) = Hn(Xn, •) on χ × Θ → [0, 1] is called a confidence distribution (CD) for a parameter θ, if it follows two requirements:Also, the function H is an asymptotic CD (aCD), if the U[0, 1] requirement is true only asymptotically and the continuity requirement on Hn(•) is dropped.
In nontechnical terms, a confidence distribution is a function of both the parameter and the random sample, with two requirements. The first requirement (R1) simply requires that a CD should be a distribution on the parameter space. The second requirement (R2) sets a restriction on the function so that inferences (point estimators, confidence intervals and hypothesis testing, etc.) based on the confidence distribution have desired frequentist properties. This is similar to the restrictions in point estimation to ensure certain desired properties, such as unbiasedness, consistency, efficiency, etc.
A confidence distribution derived by inverting the upper limits of confidence intervals (classical definition) also satisfies the requirements in the above definition and this version of the definition is consistent with the classical definition.
Unlike the classical fiducial inference, more than one confidence distributions may be available to estimate a parameter under any specific setting. Also, unlike the classical fiducial inference, optimality is not a part of requirement. Depending on the setting and the criterion used, sometimes there is a unique "best" (in terms of optimality) confidence distribution. But sometimes there is no optimal confidence distribution available or, in some extreme cases, we may not even be able to find a meaningful confidence distribution. This is not different from the practice of point estimation.
Examples
Example 1: Normal Mean and Variance
Suppose a normal sample Xi ~ N(μ, σ2), i = 1, 2, ..., n is given.
(1) Variance σ2 is known
Both the functions
satisfy the two requirements in the CD definition, and they are confidence distribution functions for μ. Here, Φ is the cumulative distribution function of the standard normal distribution, and
satisfies the definition of an asymptotic confidence distribution when n→∞, and it is an asymptotic confidence distribution for μ. The uses of
(2) Variance σ2 is unknown
For the parameter μ, since
For the parameter σ2, the sample-dependent cumulative distribution function
is a confidence distribution function for σ2. Here,
In the case when the variance σ2 is known,
Example 2: Bivariate normal correlation
Let ρ denotes the correlation coefficient of a bivariate normal population. It is well known that Fisher's z defined by the Fisher transformation:
has the limiting distribution
The function
is an asymptotic confidence distribution for ρ.
Confidence interval
From the CD definition, it is evident that the interval
Point estimation
Point estimators can also be constructed given a confidence distribution estimator for the parameter of interest. For example, given Hn(θ) the CD for a parameter θ, natural choices of point estimators include the median Mn = Hn−1(1/2), the mean
Under some modest conditions, among other properties, one can prove that these point estimators are all consistent.
Hypothesis testing
One can derive a p-value for a test, either one-sided or two-sided, concerning the parameter θ, from its confidence distribution Hn(θ). Denote by the probability mass of a set C under the confidence distribution function
(1) For the one-sided test K0: θ ∈ C vs. K1: θ ∈ Cc, where C is of the type of (−∞, b] or [b, ∞), one can show from the CD definition that supθ ∈ CPθ(ps(C) ≤ α) = α. Thus, ps(C) = Hn(C) is the corresponding p-value of the test.
(2) For the singleton test K0: θ = b vs. K1: θ ≠ b, P{K0: θ = b}(2 min{ps(Clo), one can show from the CD definition that ps(Cup)} ≤ α) = α. Thus, 2 min{ps(Clo), ps(Cup)} = 2 min{Hn(b), 1 − Hn(b)} is the corresponding p-value of the test. Here, Clo = (−∞, b] and Cup = [b, ∞).
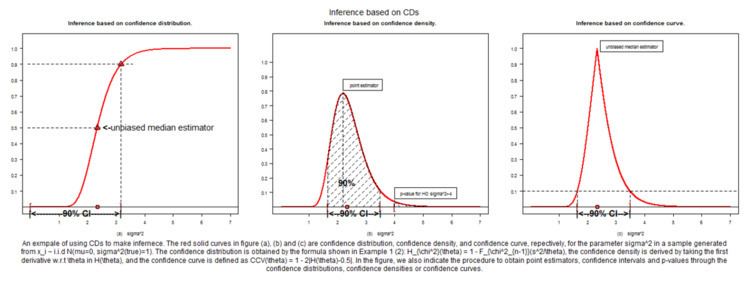
See Figure 1 from Xie and Singh (2011) for a graphical illustration of the CD inference.