
 | ||
Code-excited linear prediction (CELP) is a speech coding algorithm originally proposed by M. R. Schroeder and B. S. Atal in 1985. At the time, it provided significantly better quality than existing low bit-rate algorithms, such as residual-excited linear prediction and linear predictive coding vocoders (e.g., FS-1015). Along with its variants, such as algebraic CELP, relaxed CELP, low-delay CELP and vector sum excited linear prediction, it is currently the most widely used speech coding algorithm. It is also used in MPEG-4 Audio speech coding. CELP is commonly used as a generic term for a class of algorithms and not for a particular codec.
Contents
Introduction
The CELP algorithm is based on four main ideas:
The original algorithm as simulated in 1983 by Schroeder and Atal required 150 seconds to encode 1 second of speech when run on a Cray-1 supercomputer. Since then, more efficient ways of implementing the codebooks and improvements in computing capabilities have made it possible to run the algorithm in embedded devices, such as mobile phones.
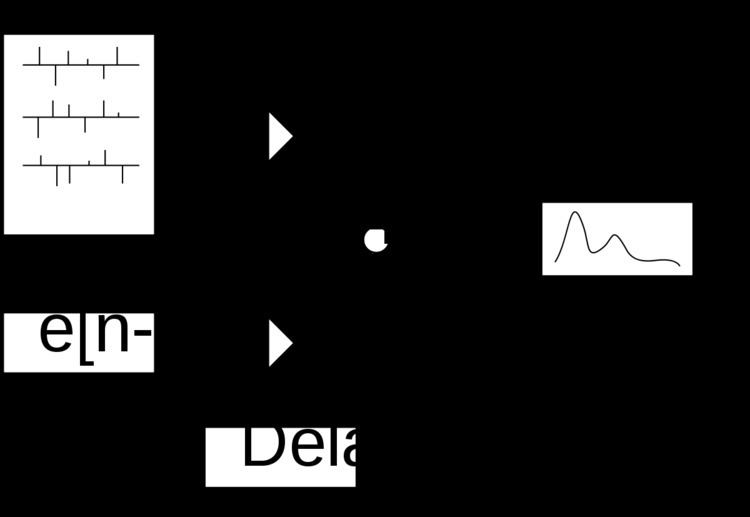
CELP decoder
Before exploring the complex encoding process of CELP we introduce the decoder here. Figure 1 describes a generic CELP decoder. The excitation is produced by summing the contributions from an adaptive (a.k.a. pitch) codebook and a stochastic (a.k.a. innovation or fixed) codebook:
where
The filter that shapes the excitation has an all-pole model of the form
CELP encoder
The main principle behind CELP is called Analysis-by-Synthesis (AbS) and means that the encoding (analysis) is performed by perceptually optimizing the decoded (synthesis) signal in a closed loop. In theory, the best CELP stream would be produced by trying all possible bit combinations and selecting the one that produces the best-sounding decoded signal. This is obviously not possible in practice for two reasons: the required complexity is beyond any currently available hardware and the “best sounding” selection criterion implies a human listener.
In order to achieve real-time encoding using limited computing resources, the CELP search is broken down into smaller, more manageable, sequential searches using a simple perceptual weighting function. Typically, the encoding is performed in the following order:
Noise weighting
Most (if not all) modern audio codecs attempt to shape the coding noise so that it appears mostly in the frequency regions where the ear cannot detect it. For example, the ear is more tolerant to noise in parts of the spectrum that are louder and vice versa. That's why instead of minimizing the simple quadratic error, CELP minimizes the error for the perceptually weighted domain. The weighting filter W(z) is typically derived from the LPC filter by the use of bandwidth expansion:
where