
 | ||
The frequency of letters in text has often been studied for use in cryptanalysis, and frequency analysis in particular.
Contents
No language has an exact letter frequency distribution, as all writers write slightly differently. As a rule texts in different languages using the Arabic script (e.g. Arabic, Old Turkish, Persian and Urdu) will have different letter frequencies, most obviously in the case of letters which are only used in some languages (e.g. the Persian letters پ, چ, گ, which are not used to write in Arabic).
Methods encoding the most frequent letters with the shortest symbols were pioneered by telegraph codes, and are used in modern data-compression techniques such as Huffman coding.
What gets counted in input Arabic text?
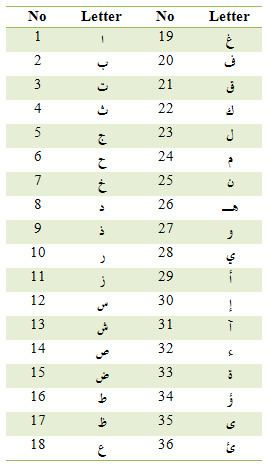
The Arabic alphabet consists of 28 primary letters, these are letters 1 to 28 in Table 1. The eight modified letters listed in positions 29 to 36 in the same table are used just the same. If these 8 modified forms are folded into the primary list based on shape or phonetic similarity, the outcome then is as shown in Table 2. For accurate frequency analysis, each of the 36 letters of Table 1 gets its frequency counted independently.
The ordering of the alphabet shown in the tables is more logical than is used by the Unicode standard.
Although the full set of Arabic characters includes about ten diacritics as shown in the Figure 1, frequency analysis of Arabic characters is only concerned with computing the frequency of alphabet letters shown in Table 2.
Qur'an letter and word frequency statistics
The frequency distribution of letters found in the Qur'an is much the same. The following list highlights statistics particular to one of the most common print editions (the recitation of Hafs through Asim) also available online.
A detailed study of letter and word frequency analysis of the entire Qur'an is provided by Intellaren Articles.