
 | ||
The Viola–Jones object detection framework is the first object detection framework to provide competitive object detection rates in real-time proposed in 2001 by Paul Viola and Michael Jones. Although it can be trained to detect a variety of object classes, it was motivated primarily by the problem of face detection. This algorithm is implemented in OpenCV as cvHaarDetectObjects().
Contents
Problem description
The problem to be solved is detection of faces in an image. A human can do this easily, but a computer needs precise instructions and constraints. To make the task more manageable, Viola–Jones requires full view frontal upright faces. Thus in order to be detected, the entire face must point towards the camera and should not be tilted to either side. While it seems these constraints could diminish the algorithm's utility somewhat, because the detection step is most often followed by a recognition step, in practice these limits on pose are quite acceptable.
Feature types and evaluation
The characteristics of Viola–Jones algorithm which make it a good detection algorithm are:
The algorithm has four stages:
- Haar Feature Selection
- Creating an Integral Image
- Adaboost Training
- Cascading Classifiers
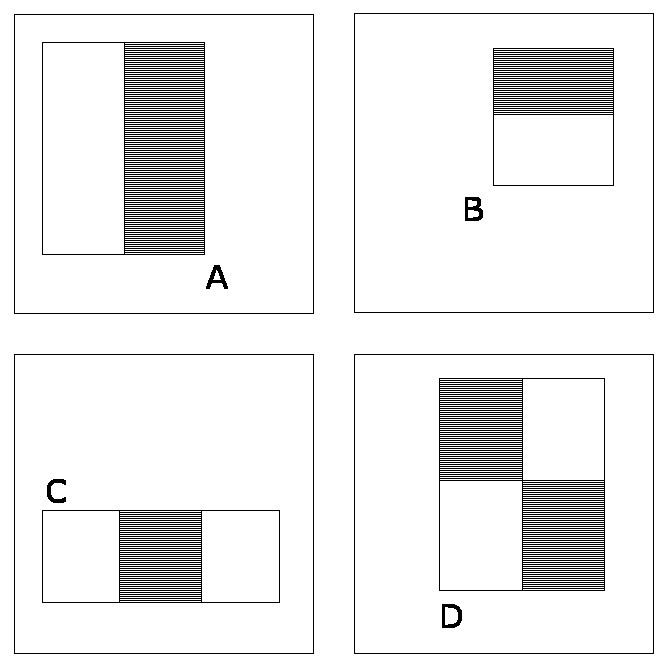
The features sought by the detection framework universally involve the sums of image pixels within rectangular areas. As such, they bear some resemblance to Haar basis functions, which have been used previously in the realm of image-based object detection. However, since the features used by Viola and Jones all rely on more than one rectangular area, they are generally more complex. The figure on the right illustrates the four different types of features used in the framework. The value of any given feature is the sum of the pixels within clear rectangles subtracted from the sum of the pixels within shaded rectangles. Rectangular features of this sort are primitive when compared to alternatives such as steerable filters. Although they are sensitive to vertical and horizontal features, their feedback is considerably coarser.
1. Haar Features – All human faces share some similar properties. These regularities may be matched using Haar Features.
A few properties common to human faces:
Composition of properties forming matchable facial features:
The four features matched by this algorithm are then sought in the image of a face (shown at left).
Rectangle features:
2. An image representation called the integral image evaluates rectangular features in constant time, which gives them a considerable speed advantage over more sophisticated alternative features. Because each feature's rectangular area is always adjacent to at least one other rectangle, it follows that any two-rectangle feature can be computed in six array references, any three-rectangle feature in eight, and any four-rectangle feature in nine.
The integral image at location (x,y), is the sum of the pixels above and to the left of (x,y), inclusive.
Learning algorithm
The speed with which features may be evaluated does not adequately compensate for their number, however. For example, in a standard 24x24 pixel sub-window, there are a total of
Each weak classifier is a threshold function based on the feature
The threshold value
Here a simplified version of the learning algorithm is reported:
Input: Set of
- Initialization: assign a weight
w 1 i = 1 N i . - For each feature
f j j = 1 , . . . , M - Renormalize the weights such that they sum to one.
- Apply the feature to each image in the training set, then find the optimal threshold and polarity
θ j , s j θ j , s j = arg min θ , s ∑ i = 1 N w j i ε j i ε j i = { 0 if y i = h j ( x i , θ j , s j ) 1 otherwise - Assign a weight
α j h j - The weights for the next iteration, i.e.
w j + 1 i i that were correctly classified.
- Set the final classifier to
h ( x ) = sign ( ∑ j = 1 M α j h j ( x ) )
Cascade architecture
In cascading, each stage consists of a strong classifier. So all the features are grouped into several stages where each stage has certain number of features.
The job of each stage is to determine whether a given sub-window is definitely not a face or may be a face. A given sub-window is immediately discarded as not a face if it fails in any of the stages.
A simple framework for cascade training is given below:
The cascade architecture has interesting implications for the performance of the individual classifiers. Because the activation of each classifier depends entirely on the behavior of its predecessor, the false positive rate for an entire cascade is:
Similarly, the detection rate is:
Thus, to match the false positive rates typically achieved by other detectors, each classifier can get away with having surprisingly poor performance. For example, for a 32-stage cascade to achieve a false positive rate of
Advantages of Viola–Jones algorithm
Disadvantages of Viola–Jones algorithm
Related face detection and tracking algorithm
A method similar to Viola–Jones but that can better detect and track tilted and rotated faces is the KLT algorithm. Here numerous feature points are acquired by first scanning the face. These points then may be detected and tracked even when the face is tilted or turned away from the camera, something Viola–Jones has difficulty doing due to its dependence on rectangles.
Improvements over the Viola–Jones algorithm
An improved algorithm on Viola–Jones object detector
MATLAB implementation of Viola–Jones algorithm
OpenCV implementation of Viola–Jones algorithm
Haar Cascade Detection in OpenCV
Cascade Classifier Training in OpenCV
Citations of the Viola–Jones algorithm in Google Scholar
Implementing the Viola–Jones Face Detection Algorithm by Ole Helvig Jensen
Adaboost Explanation from ppt by Qing Chen, Discovery Labs, University of Ottawa and a video lecture by Ramsri Goutham.
Video link -