
 | ||
Variance-based sensitivity analysis is a form of global sensitivity analysis. Working within a probabilistic framework, it decomposes the variance of the output of the model or system into fractions which can be attributed to inputs or sets of inputs. For example, given a model with two inputs and one output, one might find that 70% of the output variance is caused by the variance in the first input, 20% by the variance in the second, and 10% due to Interactions between the two. These percentages are directly interpreted as measures of sensitivity. Variance-based measures of sensitivity are attractive because they measure sensitivity across the whole input space (i.e. it is a global method), they can deal with nonlinear responses, and they can measure the effect of interactions in non-additive systems.
Contents
Decomposition of Variance
From a black box perspective, any model may be viewed as a function Y=f(X), where X is a vector of d uncertain model inputs {X1, X2, ... Xd}, and Y is a chosen univariate model output (note that this approach examines scalar model outputs, but multiple outputs can be analysed by multiple independent sensitivity analyses). Furthermore, it will be assumed that the inputs are independently and uniformly distributed within the unit hypercube, i.e.
where f0 is a constant and fi is a function of Xi, fij a function of Xi and Xj, etc. A condition of this decomposition is that,
i.e. all the terms in the functional decomposition are orthogonal. This leads to definitions of the terms of the functional decomposition in terms of conditional expected values,
From which it can be seen that fi is the effect of varying Xi alone (known as the main effect of Xi), and fij is the effect of varying Xi and Xj simultaneously, additional to the effect of their individual variations. This is known as a second-order interaction. Higher-order terms have analogous definitions.
Now, further assuming that the f(X) is square-integrable, the functional decomposition may be squared and integrated to give,
Notice that the left hand side is equal to the variance of Y, and the terms of the right hand side are variance terms, now decomposed with respect to sets of the Xi. This finally leads to the decomposition of variance expression,
where
and so on. The X~i notation indicates the set of all variables except Xi. The above variance decomposition shows how the variance of the model output can be decomposed into terms attributable to each input, as well as the interaction effects between them. Together, all terms sum to the total variance of the model output.
First-order indices
A direct variance-based measure of sensitivity Si, called the "first-order sensitivity index", or "main effect index" is stated as follows,
This is the contribution to the output variance of the main effect of Xi, therefore it measures the effect of varying Xi alone, but averaged over variations in other input parameters. It is standardised by the total variance to provide a fractional contribution. Higher-order interaction indices Sij, Sijk and so on can be formed by dividing other terms in the variance decomposition by Var(Y). Note that this has the implication that,
Total-effect index
Using the Si, Sij and higher-order indices given above, one can build a picture of the importance of each variable in determining the output variance. However, when the number of variables is large, this requires the evaluation of 2d-1 indices, which can be too computationally demanding. For this reason, a measure known as the "Total-effect index" or "Total-order index", STi, is used. This measures the contribution to the output variance of Xi, including all variance caused by its interactions, of any order, with any other input variables. It is given as,
Note that unlike the Si,
due to the fact that the interaction effect between e.g. Xi and Xj is counted in both STi and STj In fact, the sum of the STi will only be equal to 1 when the model is purely additive.
Calculation of indices
For analytically tractable functions, the indices above may be calculated analytically by evaluating the integrals in the decomposition. However, in the vast majority of cases they are estimated - this is usually done by the Monte Carlo method.
Sampling sequences
The Monte Carlo approach involves generating a sequence of randomly distributed points inside the unit hypercube (strictly speaking these will be pseudorandom). In practice, it is common to substitute random sequences with low-discrepancy sequences to improve the efficiency of the estimators. This is then known as the Quasi-Monte Carlo method. Some low-discrepancy sequences commonly used in sensitivity analysis include the Sobol sequence and the Latin hypercube design.
Procedure
To calculate the indices using the (Quasi) Monte Carlo method, the following steps are used:
- Generate an Nx2d sample matrix, i.e. each row is a sample point in the hyperspace of 2d dimensions. This should be done with respect to the probability distributions of the input variables.
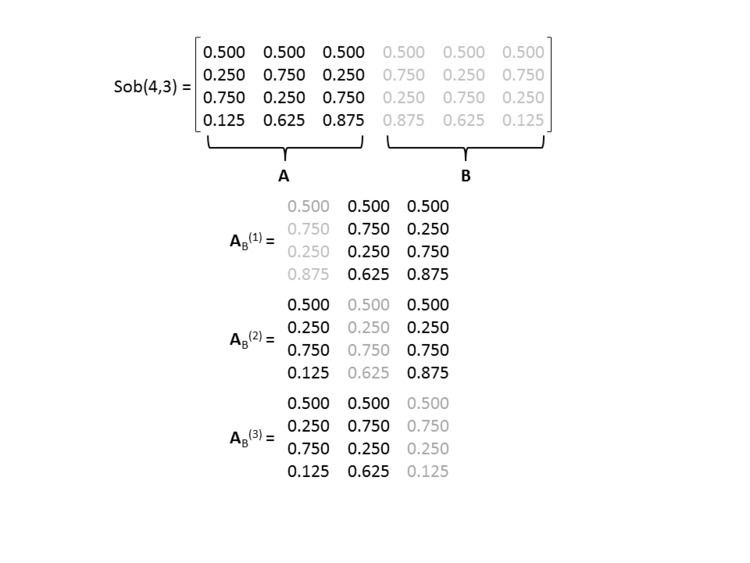
- Use the first d columns of the matrix as matrix A, and the remaining d columns as matrix B. This effectively gives two independent samples of N points in the d-dimensional unit hypercube.
- Build d further Nxd matrices ABi, for i = 1,2,...,d, such that the ith column of ABi is equal to the ith column of B, and the remaining columns are from A.
- The A, B, and the d ABi matrices in total specify N(d+2) points in the input space (one for each row). Run the model at each design point in the A, B, and ABi matrices, giving a total of N(d+2) model evaluations - the corresponding f(A), f(B) and f(ABi) values.
- Calculate the sensitivity indices using the estimators below.
The accuracy of the estimators is of course dependent on N. The value of N can be chosen by sequentially adding points and calculating the indices until the estimated values reach some acceptable convergence. For this reason, when using low-discrepancy sequences, it can be advantageous to use those that allow sequential addition of points (such as the Sobol sequence), as compared to those that do not (such as Latin hypercube sequences).
Estimators
There are a number of possible Monte Carlo estimators available for both indices. Two that are currently in general use are,
and
for the estimation of the Si and the STi respectively.
Computational Expense
For the estimation of the Si and the STi for all input variables, N(d+2) model runs are required. Since N is often of the order of hundreds or thousands of runs, computational expense can quickly become a problem when the model takes a significant amount of time for a single run. In such cases, there are a number of techniques available to reduce the computational cost of estimating sensitivity indices, such as emulators, HDMR and FAST.