
Data structure Array | ||
 | ||
Worst-case performance O ( n log n ) {displaystyle O(nlog n)} Best-case performance O ( n ) {displaystyle O(n)} Average performance O ( n log n ) {displaystyle O(nlog n)} Worst-case space complexity O ( n ) {displaystyle O(n)} | ||
Timsort is a hybrid stable sorting algorithm, derived from merge sort and insertion sort, designed to perform well on many kinds of real-world data. It uses techniques from Peter McIlroy's "Optimistic Sorting and Information Theoretic Complexity", in Proceedings of the Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 467–474, January 1993. It was implemented by Tim Peters in 2002 for use in the Python programming language. The algorithm finds subsequences of the data that are already ordered, and uses that knowledge to sort the remainder more efficiently. This is done by merging an identified subsequence, called a run, with existing runs until certain criteria are fulfilled. Timsort has been Python's standard sorting algorithm since version 2.3. It is also used to sort arrays of non-primitive type in Java SE 7, on the Android platform, and in GNU Octave.
Contents
Operation
Timsort was designed to take advantage of runs of consecutive ordered elements that already exist in most real-world data, natural runs. It iterates over the data collecting elements into runs, and concurrently merging those runs together.
Runs
Timsort iterates over the data looking for natural runs of at least two elements that are either non-descending (each element is greater than or equal to its predecessor) or strictly descending (each element is less than its predecessor). Descending runs are later blindly reversed, so the strict order maintains the algorithm's stability; i.e., equal elements won't be reversed. Note that any two elements are guaranteed to be either descending or non-descending.
Where there are fewer than minrun elements in the run, it is brought up to size by sorting in, using binary insertion sort, the required number of following elements.
A reference to each run is then pushed onto a stack.
Minimum size (minrun)
Timsort is an adaptive sort, using insertion sort to combine runs smaller than the minimum run size (minrun), and merge sort otherwise.
Minrun is selected so most runs in a random array are, or become, minrun in length. It also results in a reasonable number of function calls in the implementation of the sort.
The length and occurrence of natural runs in real-world data varies by the length of data to be sorted. Thus, the minimum run size (minrun) depends on the size of the data being sorted, with a minimum of 64. So, for fewer than 64 elements, Timsort reduces to an insertion sort. For larger arrays, minrun is chosen from the range 32 to 64 inclusive, such that the size of the data, divided by minrun, is equal to, or slightly smaller than, a power of two. The final algorithm takes the six most significant bits of the size of the array, adds one if any of the remaining bits are set, and uses that result as the minrun. This algorithm works for all arrays, including those smaller than 64.
Merging
Concurrently with the search for runs, the runs are merged with merge sort. Except where Timsort tries to optimise for merging disjoint runs in galloping mode, runs are repeatedly merged together 2 at a time, with the only concerns being to maintain stability and merge balance.
Stability requires non-consecutive runs are not merged, as elements could be transferred across equal elements in the intervening run, violating stability. Further, it would be impossible to recover the order of the equal elements at a later point.
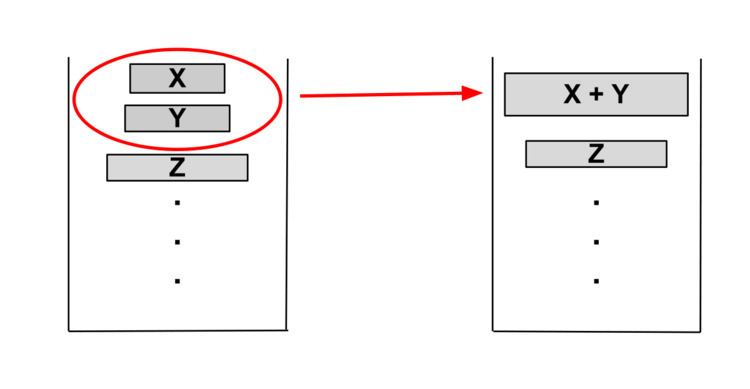
In pursuit of balanced merges, Timsort considers 3 runs on the top of the stack, X, Y, Z, and the invariants:
If the invariants are violated, Y is merged with the smaller of X or Z and the invariants are checked again. If the invariants hold, the next iteration of searching occurs.
Somewhat inappreciably, the invariants maintain merges as being approximately balanced while maintaining a compromise between delaying merging for balance, and exploiting fresh occurrence of runs in cache memory, and also making merge decisions relatively simple.
On reaching the end of the data, Timsort repeatedly merges the 2 runs on the top of the stack, until only one run of the entire data remains.
Individual merges
Timsort performs an almost in-place merge sort, as actual in-place merge sort implementations have a high overhead. The smaller of the two runs is copied into temporary memory, and elements are sorted into the larger run, and the now free space. If the former run is smaller, the sort starts at the bottom, and from the top, if the latter run is smaller. Timsort performs a binary search to find the location in the first run of the first element in the second run, and the location in the second run of the last element in the first run. This not only optimises element movements and running time, but also allows the use of less temporary memory.
Say, for example, two runs A and B are to be merged, with A as the smaller run. In this case a binary search examines A to find the first position larger than the first element of B(aʹ). Note that A and B are already sorted individually. When aʹ is found, the algorithm can ignore elements before that position while inserting B. Similarly, the algorithm also looks for the smallest element in B(bʹ) greater than the largest element in A(aʺ). The elements after bʹ can also be ignored for the merging. This preliminary searching is not efficient for highly random data, but is efficient in other situations and is hence included.
Galloping mode
The individual merging above keeps a count of consecutive elements selected from the same input set. The algorithm switches to galloping mode when this reaches the minimum galloping threshold (min_gallop). This tries to capitalise on sub-runs in the data; as such, the success or failure of galloping is used to adjust the minimum galloping threshold, as an indication of whether the data does or does not contain sufficient sub-runs. (The initial threshold is MIN_GALLOP.)
In galloping mode, the algorithm searches for the first element of one array in the other. This is done by comparing that first element (initial element) with the zeroth element of the other array, then the first, the third and so on, that is (2k − 1)th element, so as to get a range of elements between which the initial element will lie. This shortens the range for binary searching, thus increasing efficiency. Galloping proves to be more efficient except in cases with especially long runs, but random data usually has shorter runs. Also, in cases where galloping is found to be less efficient than binary search, galloping mode is exited.
Galloping is not always efficient. One reason is due to excessive function calls. Function calls are expensive and thus when frequent, they affect program efficiency. In some cases galloping mode requires more comparisons than a simple linear search (one at a time search). While for the first few cases both modes may require the same number of comparisons, over time galloping mode requires 33% more comparisons than linear search to arrive at the same results. Moreover, all comparisons in galloping mode are done by function calls.
Galloping is beneficial only when the initial element of one run is not one of the first seven elements of the other run. This implies a MIN_GALLOP of 7. To avoid the drawbacks of galloping mode, the merging functions adjust the value of min-gallop. If the element is from the array currently that has been returning elements, min-gallop is reduced by one. Otherwise, the value is incremented by one, thus discouraging a return to galloping mode. When this is done, in the case of random data, the value of min-gallop becomes so large that galloping mode never recurs.
In the case where merge-hi is used (that is, merging is done right-to-left), galloping starts from the right end of the data, that is, the last element. Galloping from the beginning also gives the required results, but makes more comparisons. Thus, the galloping algorithm uses a variable that gives the index at which galloping should begin. Timsort can enter galloping mode at any index and continue checking at the next index which is offset by 1, 3, 7, …, (2k − 1)… and so on from the current index. In the case of merge-hi, the offsets to the index will be −1, −3, −7, …
Analysis
In the worst case, Timsort takes
Formal verification
In the scientific article OpenJDK's Java.utils.Collection.sort() Is Broken: The Good, the Bad and the Worst Case, which appeared in 2015 in the Proceedings of Computer Aided Verification (CAV), pages 273–289, the researchers Stijn de Gouw, Jurriaan Rot, Frank S. de Boer, Richard Bubel, and Reiner Hähnle describe how they discovered using formal verification (KeY) that it is not sufficient to check only the three top-most runs in the stack for the following invariant to hold: all three consecutive runs of the stack satisfy the two rules above.
The allocation of the stack which fixes its size however is based on the assumption that this invariant holds. As a consequence for certain inputs the allocated size is not sufficient to hold all generated runs. In Java for example this generates for those inputs an array-out-of-bound exception. The smallest input that triggers this exception in Java and Android v7 is of size 67108864 (older Android versions already triggered this exception for certain inputs of size 65536!).
The Java implementation has been corrected by adapting the size of the stack on the basis of the worst case analysis described in the above mentioned article. In this article it is also shown by formal methods how to establish the invariant by checking that the four top-most runs in the stack satisfy the two rules above. This approach has been followed by Python. Android also in the end decided to follow this approach.
The work underlying this application of formal methods has been carried out in the EU FP7 ENVISAGE project.