
 | ||
Sudoku codes are non-linear forward error correcting codes following rules of sudoku puzzles designed for an erasure channel. Based on this model, the transmitter sends a sequence of all symbols of a solved sudoku. The receiver either receives a symbol correctly or an erasure symbol to indicate that the symbol was not received. The decoder gets a matrix with missing entries and uses the constraints of sudoku puzzles to reconstruct a limited amount of erased symbols.
Contents
- Erasure channel model
- Puzzle description
- Decoding with belief propagation
- Encoding
- Performance of sudoku codes
- Density evolution
- References
Sudoku codes are not suitable for practical usage but are subject of research. Questions like the rate and error performance are still unknown for general dimensions.
In a sudoku one can find missing information by using different techniques to reproduce the full puzzle. This method can be seen as decoding a sudoku coded message that is sent over an erasure channel where some symbols got erased. By using the sudoku rules the decoder can recover the missing information. Sudokus can be modeled as a probabilistic graphical model and thus methods from decoding low-density parity-check codes like belief propagation can be used.
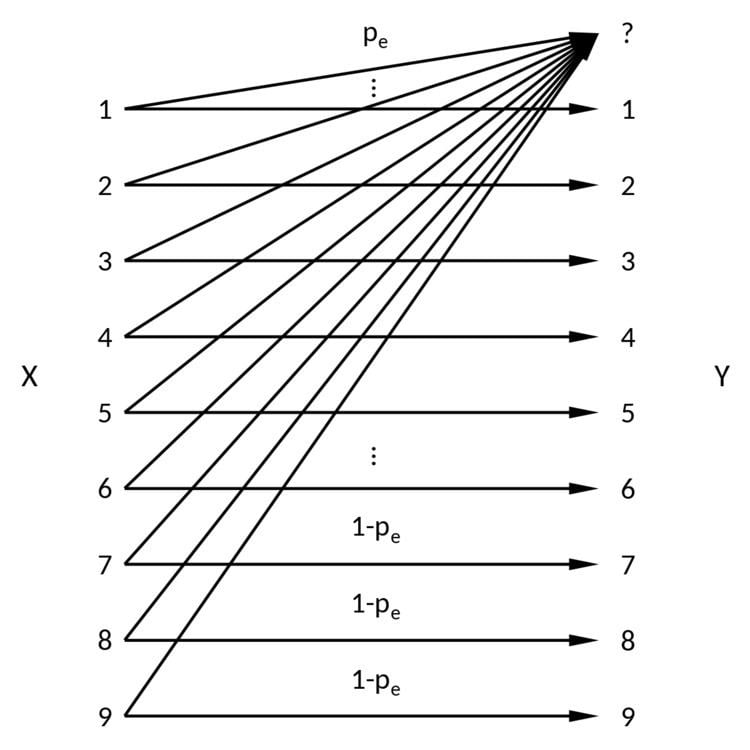
Erasure channel model
In the erasure channel model a symbol gets either transmitted correctly with probability
Note that the symbols sent over the channel are not binary. For a binary channel the symbols (e.g. integers
Puzzle description
A sudoku is a
For channel codes also other varieties of sudokus are conceivable. Diagonal regions instead of square sub-grids can be used for performance investigations. The diagonal sudoku has the advantage, that its size can be chosen more freely. Due to the sub-grid structure normal sudokus can only be of size n², diagonal sudokus have valid solutions for all odd
Sudoku codes are non-linear. In a linear code any linear combination of codewords give a new valid codeword, this does not hold for sudoku codes. The symbols of a sudoku are from a finite alphabet (e.g. integers
Sudoku codes can be represented by probabilistic graphical model in which they take the form of a low-density parity-check code.
Decoding with belief propagation
There are several possible decoding methods for sudoku codes. Some algorithms are very specific developments for Sudoku codes. Several methods are described in sudoku solving algorithms. Another efficient method is with dancing links.
Decoding methods like belief propagation are also used for low-density parity-check codes are of special interest. Performance analysis of these methods on sudoku codes can help to understand decoding problems for low-density parity-check codes better.
By modeling sudoku codes as a probabilistic graphical model belief propagation can be used for Sudoku codes. Belief propagation on the tanner graph or factor graph to decode Sudoku codes is discussed in by Sayir. and Moon This method is originally designed for low-density parity-check codes. Due to its generality belief propagation works not only with the classical
The constraint satisfaction using a tanner graph is shown in the figure on the right.
Every cell
Encoding
The aim of error-correcting codes is to encode data in a way such that it is more resilient to errors in the transmission process. The encoder has to map data
shows the necessary steps.
A standard
A suggested encoding approach by Sayir is as follows:
For a
Performance of sudoku codes
The calculation of the rate of sudoku codes is not trivial. An example rate calculation of a
The exact number of possible Sudoku grids according to Mathematics of Sudoku is
the average rate of a standard Sudoku is
The average number of possible entries for a cell is
The minimum number of given entries that render a unique solution was proven to be 17. In the worst case only four missing entries can lead to ambiguous solutions. For an erasure channel it is very unlikely that 17 successful transmissions are enough to reproduce the puzzle. There are only about 50,000 known solutions with 17 given entries.
Density evolution
Density evolution is a capacity analysis algorithm originally developed for low-density parity-check codes on belief propagation decoding. Density evolution can also be applied to Sudoku-type constraints. One important simplification used in density evolution on LDPC codes is the sufficiency to analyze only the all-one codeword. With the Sudoku constraints however, this is not a valid codeword. Unlike for linear codes the weight-distance equivalence property does not hold for non-linear codes. Therewith it is necessary to compute density evolution recursions for every possible Sudoku puzzle to get precise performance analysis.
A proposed simplification is to analyze the probability distribution of the cardinalities of messages instead of the probability distribution of the message. Density evolution is calculated on the entry nodes and the constraint nodes (compare Tanner graph above). On the entry nodes one analyzes the cardinalities of the constraints. If for example the constraints have the cardinalities
and for output of cardinality 2
For a standard
For constraint nodes the procedure is somewhat similar and described in the following example based on a
If the cardinality converges to 1 the decoding is error-free. To find the threshold the erasure probability must be increased until the decoding error remains positive for any number of iterations. With the method of Sayir density evolution recursions can be used to calculate thresholds also for Sudoku codes up to an alphabet size