
 | ||
Slope One is a family of algorithms used for collaborative filtering, introduced in a 2005 paper by Daniel Lemire and Anna Maclachlan. Arguably, it is the simplest form of non-trivial item-based collaborative filtering based on ratings. Their simplicity makes it especially easy to implement them efficiently while their accuracy is often on par with more complicated and computationally expensive algorithms. They have also been used as building blocks to improve other algorithms. They are part of major open-source libraries such as Apache Mahout and Easyrec.
Contents
Item-based collaborative filtering of purchase statistics
We are not always given ratings: when the users provide only binary data (the item was purchased or not), then Slope One and other rating-based algorithm do not apply. Examples of binary item-based collaborative filtering include Amazon's item-to-item patented algorithm which computes the cosine between binary vectors representing the purchases in a user-item matrix.
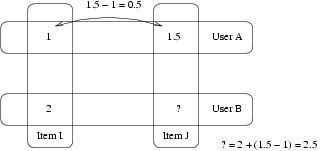
Being arguably simpler than even Slope One, the Item-to-Item algorithm offers an interesting point of reference. Let us consider an example.
In this case, the cosine between items 1 and 2 is:
The cosine between items 1 and 3 is:
Whereas the cosine between items 2 and 3 is:
Hence, a user visiting item 1 would receive item 3 as a recommendation, a user visiting item 2 would receive item 3 as a recommendation, and finally, a user visiting item 3 would receive item 1 (and then item 2) as a recommendation. The model uses a single parameter per pair of item (the cosine) to make the recommendation. Hence, if there are n items, up to n(n-1)/2 cosines need to be computed and stored.
Algorithmic complexity of Slope One
Suppose there are n items, m users, and N ratings. Computing the average rating differences for each pair of items requires up to n(n-1)/2 units of storage, and up to m n2 time steps. This computational bound may be pessimistic: if we assume that users have rated up to y items, then it is possible to compute the differences in no more than n2+my2. If a user has entered x ratings, predicting a single rating requires x time steps, and predicting all of his missing ratings requires up to (n-x)x time steps. Updating the database when a user has already entered x ratings, and enters a new one, requires x time steps.
It is possible to reduce storage requirements by partitioning the data (see Partition (database)) or by using sparse storage: pairs of items having no (or few) corating users can be omitted.