
 | ||
In computer programming, a rope, or cord, is a data structure composed of smaller strings that is used to efficiently store and manipulate a very long string. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done efficiently.
Contents
Description
A rope is a binary tree having leaf nodes that contain a short string. Each node has a weight value equal to the length of its string plus the sum of all leaf nodes' weight in its left subtree, namely the weight of a node is the total string length in its left subtree for a non-leaf node, or the string length of itself for a leaf node. Thus a node with two children divides the whole string into two parts: the left subtree stores the first part of the string. The right subtree stores the second part and its weight is the sum of the left child's weight and the length of its contained string.
The binary tree can be seen as several levels of nodes. The bottom level contains all the nodes that contain a string. Higher levels have fewer and fewer nodes. The top level consists of a single "root" node. The rope is built by putting the nodes with short strings in the bottom level, then attaching a random half of the nodes to parent nodes in the next level.
Operations
In the following definitions, N is the length of the rope.
Index
Definition:Index(i): return the character at position iTime complexity: O(log N)To retrieve the i-th character, we begin a recursive search from the root node:
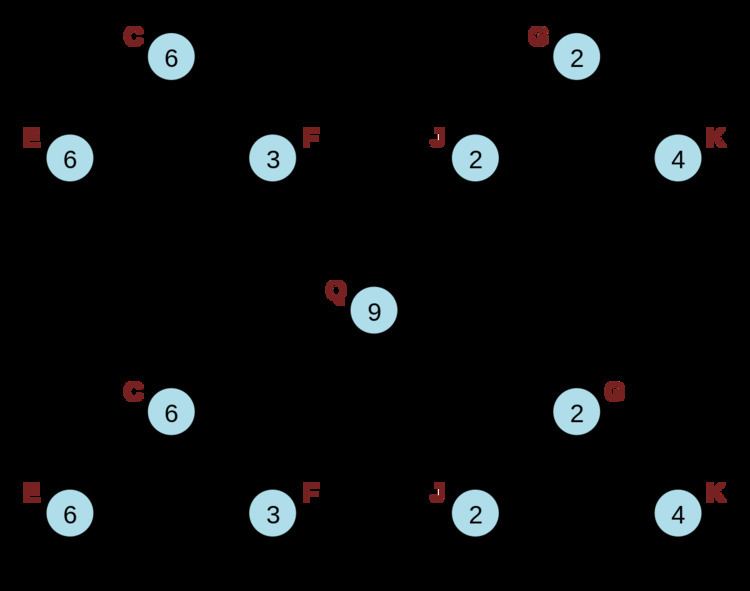
For example, to find the character at i=10 in Figure 2.1 shown on the right, start at the root node (A), find that 22 is greater than 10 and there is a left child, so go to the left child (B). 9 is less than 10, so subtract 9 from 10 (leaving i=1) and go to the right child (D). Then because 6 is greater than 1 and there's a left child, go to the left child (G). 2 is greater than 1 and there's a left child, so go to the left child again (J). Finally 2 is greater than 1 but there is no left child, so the character at index 1 of the short string "na", is the answer.
Concat
Definition:Concat(S1, S2): concatenate two ropes, S1 and S2, into a single rope.Time complexity: O(1) (or O(log N) time to compute the root weight)A concatenation can be performed simply by creating a new root node with left = S1 and right = S2, which is constant time. The weight of the parent node is set to the length of the left child S1, which would take O(log N) time, if the tree is balanced.
As most rope operations require balanced trees, the tree may need to be re-balanced after concatenation.
Split
Definition:Split (i, S): split the string S into two new strings S1 and S2, S1 = C1, …, Ci and S2 = Ci + 1, …, Cm.Time complexity: O(log N)There are two cases that must be dealt with:
- The split point is at the end of a string (i.e. after the last character of a leaf node)
- The split point is in the middle of a string.
The second case reduces to the first by splitting the string at the split point to create two new leaf nodes, then creating a new node that is the parent of the two component strings.
For example, to split the 22-character rope pictured in Figure 2.3 into two equal component ropes of length 11, query the 12th character to locate the node K at the bottom level. Remove the link between K and G. Go to the parent of G and subtract the weight of K from the weight of D. Travel up the tree and remove any right links to subtrees covering characters past position 11, subtracting the weight of K from their parent nodes (only node D and A, in this case). Finally, build up the newly orphaned nodes K and H by concatenating them together and creating a new parent P with weight equal to the length of the left node K.
As most rope operations require balanced trees, the tree may need to be re-balanced after splitting.
Insert
Definition:Insert(i, S’): insert the string S’ beginning at position i in the string s, to form a new string C1, …, Ci, S’, Ci + 1, …, Cm.Time complexity: O(log N).This operation can be done by a Split() and two Concat() operations. The cost is the sum of the three.
Delete
Definition:Delete(i, j): delete the substring Ci, …, Ci + j − 1, from s to form a new string C1, …, Ci − 1, Ci + j, …, Cm.Time complexity: O(log N).This operation can be done by two Split() and one Concat() operation. First, split the rope in three, divided by i-th and i+j-th character respectively, which extracts the string to delete in a separate node. Then concatenate the other two nodes.
Report
Definition:Report(i, j): output the string Ci, …, Ci + j − 1.Time complexity: O(j + log N)To report the string Ci, …, Ci + j − 1, find the node u that contains Ci and weight(u) >= j, and then traverse T starting at node u. Output Ci, …, Ci + j − 1 by doing an in-order traversal of T starting at node u.
Comparison with monolithic arrays
Advantages:
Disadvantages:
This table compares the algorithmic traits of string and rope implementations, not their raw speed. Array-based strings have smaller overhead, so (for example) concatenation and split operations are faster on small datasets. However, when array-based strings are used for longer strings, time complexity and memory use for inserting and deleting characters become unacceptably large. In contrast, a rope data structure has stable performance regardless of data size. Further, the space complexity for ropes and arrays are both O(n). In summary, ropes are preferable when the data is large and modified often.