
Paradigm SPMD and MPMD Typing discipline Dynamic | Developer pbdR Core Team | |
 | ||
Designed by Wei-Chen Chen, George Ostrouchov, Pragneshkumar Patel, and Drew Schmidt First appeared September 2012; 4 years ago (2012-09) Preview release Through GitHub at RBigData | ||
Programming with Big Data in R (pbdR) is a series of R packages and an environment for statistical computing with Big Data by using high-performance statistical computation. The pbdR uses the same programming language as R with S3/S4 classes and methods which is used among statisticians and data miners for developing statistical software. The significant difference between pbdR and R code is that pbdR mainly focuses on distributed memory systems, where data are distributed across several processors and analyzed in a batch mode, while communications between processors are based on MPI that is easily used in large high-performance computing (HPC) systems. R system mainly focuses on single multi-core machines for data analysis via an interactive mode such as GUI interface.
Contents
Two main implementations in R using MPI are Rmpi and pbdMPI of pbdR.
The idea of SPMD parallelism is to let every processor do the same amount of work, but on different parts of a large data set. For example, a modern GPU is a large collection of slower co-processors that can simply apply the same computation on different parts of relatively smaller data, but the SPMD parallelism ends up with an efficient way to obtain final solutions (i.e. time to solution is shorter). It is clear that pbdR is not only suitable for small clusters, but is also more stable for analyzing Big data and more scalable for supercomputers. In short, pbdR
Package design
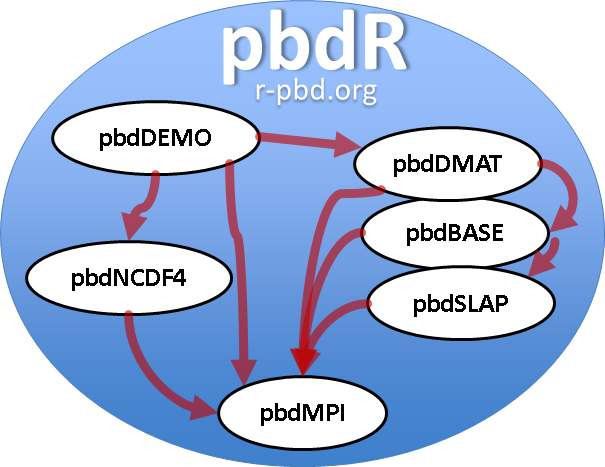
Programming with pbdR requires usage of various packages developed by pbdR core team. Packages developed are the following.
Among these packages, pbdMPI provides wrapper functions to MPI library, and it also produces a shared library and a configuration file for MPI environments. All other packages rely on this configuration for installation and library loading that avoids difficulty of library linking and compiling. All other packages can directly use MPI functions easily.
Among those packages, the pbdDEMO package is a collection of 20+ package demos which offer example uses of the various pbdR packages, and contains a vignette that offers detailed explanations for the demos and provides some mathematical or statistical insight.
Example 1
Hello World! Save the following code in a file called "demo.r"
and use the command
to execute the code where Rscript is one of command line executable program.
Example 2
The following example modified from pbdMPI illustrates the basic syntax of the language of pbdR. Since pbdR is designed in SPMD, all the R scripts are stored in files and executed from the command line via mpiexec, mpirun, etc. Save the following code in a file called "demo.r"
and use the command
to execute the code where Rscript is one of command line executable program.
Example 3
The following example modified from pbdDEMO illustrates the basic ddmatrix computation of pbdR which performs singular value decomposition on a given matrix. Save the following code in a file called "demo.r"
and use the command
to execute the code where Rscript is one of command line executable program.