
 | ||
In computer science, parallel tree contraction is a broadly applicable technique for the parallel solution of a large number of tree problems, and is used as an algorithm design technique for the design of a large number of parallel graph algorithms. Parallel tree contraction was introduced by Gary L. Miller and John H. Reif, and has subsequently been modified to improve efficiency by X. He and Y. Yesha, Hillel Gazit, Gary L. Miller and Shang-Hua Teng and many others.
Contents
Tree contraction has been used in designing many efficient parallel algorithms, including expression evaluation, finding lowest common ancestors, tree isomorphism, graph isomorphism, maximal subtree isomorphism, common subexpression elimination, computing the 3-connected components of a graph, and finding an explicit planar embedding of a planar graph
Based on the research and work on parallel tree contraction, various algorithms have been proposed targeting to improve the efficiency or simplicity of this topic. This article hereby focuses on a particular solution, which is a variant of the algorithm by Miller and Reif, and its application.
Introduction
Over the past several decades there has been significant research on deriving new parallel algorithms for a variety of problems, with the goal of designing highly parallel (polylogarithmic depth), work-efficient (linear in the sequential running time) algorithms. For some problems, tree turns out to be a nice solution. Addressing these problems, we can sometimes get more parallelism simply by representing our problem as a tree.
Considering a generic definition of a tree, there is a root vertex, and several child vertices attached to the root. And the child vertices might have children themselves, and so on so forth. Eventually, the paths come down to leaves, which are defined to be the terminal of a tree. Then based on this generic tree, we can further come up with some special cases: (1) balanced binary tree; (2) linked list. A balanced binary tree has exactly two branches for each vertex except for leaves. This gives a O(log n) bound on the depth of the tree. A linked list is also a tree where every vertex has only one child. We can also achieve O(log n) depth using symmetry breaking.
Given the general case of a tree, we would like to keep the bound at O(log n) no matter it is unbalanced or list-like or a mix of both. To address this problem, we make use of an algorithm called prefix sum by using the Euler tour technique. With the Euler tour technique, a tree could be represented in a flat style, and thus prefix sum could be applied to an arbitrary tree in this format. In fact, prefix sum can be used on any set of values and binary operation which form a group: the binary operation must be associative, every value must have an inverse, and there exists an identity value.
With a bit of thought, we can find some exceptional cases where prefix sum becomes incapable or inefficient. Consider the example of multiplication when the set of values includes 0. Or there are some commonly desired operations are max() and min() which do not have inverses. The goal is to seek an algorithm which works on all trees, in expected O(n) work and O(log n) depth. In the following sections, a Rake/Compress algorithm will be proposed to fulfill this goal.
Definitions
Before going into the algorithm itself, we first look at a few terminologies that will be used later.
And in order to solve actual problems using tree contraction, the algorithm has a structure:
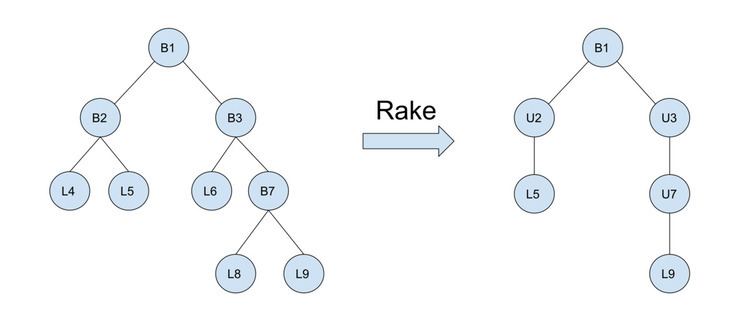
Repeat until tree becomes a unary node { Rake; Compress; }Analysis
For the moment, let us assume that all nodes have less than three children, namely binary. Generally speaking, as long as the degree is bounded, the bounds will hold. But we will analyze the binary case for simplicity. In the two “degenerate” cases listed above, the rake is the best tool for dealing with balanced binary trees, and compress is the best for linked lists. However, arbitrary trees will have to require a combination of these operations. By this combination, we claim a theorem that
Now rephrase the tree contraction algorithm as follows:
To approach the theorem, we first take a look at a property of a binary tree. Given a binary tree T, we can partition the nodes of T into 3 groups:
This claim can be proved by strong induction on the number of nodes. It is easy to see that the base case of n=1 trivially holds. And we further assume the claim also holds for any tree with at most n nodes. Then given a tree with n+1 nodes rooted at r, there appears to be two cases:
- If r has only one subtree, consider the subtree of r. We know that the subtree has the same number of binary nodes and the same number of leaf nodes as the whole tree itself. This is true since the root is a unary node. And based the previous assumption, a unary node does not change either
T 0 T 2 - If r has two subtrees, we define
T 0 L , T 2 L T 0 R , T 2 R | T 0 L | = | T 2 L | + 1 and| T 0 R | = | T 2 R | + 1 . Also we know that T has| T 0 L | + | T 0 R | leaf nodes and| T 2 L | + | T 2 R | + 1 binary nodes. Thus, we can derive:
which proves the claim.
Following the claim, we then prove a lemma, which leads us to the theorem.
Assume the number of nodes before the contraction to be m, and m' after the contraction. By definition, the rake operation deletes all
Finally, based on this lemma, we can conclude that if the nodes are reduced by a constant factor in each iteration, after
Expression Evaluation
To evaluate an expression given as a binary tree (this problem also known as binary expression tree), consider that: An arithmetic expression is a tree where the leaves have values from some domain and each internal vertex has two children and a label from {+, x, %}. And further assume that these binary operations can be performed in constant time.
We now show the evaluation can be done with parallel tree contraction.
In a node with 2 children, the operands in the expression are f(L) and g(R), where f and g are linear functions, and in a node with 1 child, the expression is h(x), where h is a linear function and x is either L or R. We prove this invariant by induction. At the beginning, the invariant is clearly satisfied. There are three types of merges that result in a not fully evaluated expression. (1) A 1-child node is merged into a 2-children node. (2) A leaf is merged into a 2-children node. (3) A 1-child node is merged into a 1-child node. All three types of merges do not change the invariant. Therefore, every merge simply evaluates or composes linear functions, which takes constant time