
 | ||
In statistics, one-way analysis of variance (abbreviated one-way ANOVA) is a technique used to compare means of three or more samples (using the F distribution). This technique can be used only for numerical data.
Contents
- Assumptions
- Departures from population normality
- The model
- The data and statistical summaries of the data
- The hypothesis test
- Analysis summary
- Example
- References
The ANOVA tests the null hypothesis that samples in two or more groups are drawn from populations with the same mean values. To do this, two estimates are made of the population variance. These estimates rely on various assumptions (see below). The ANOVA produces an F-statistic, the ratio of the variance calculated among the means to the variance within the samples. If the group means are drawn from populations with the same mean values, the variance between the group means should be lower than the variance of the samples, following the central limit theorem. A higher ratio therefore implies that the samples were drawn from populations with different mean values.
Typically, however, the one-way ANOVA is used to test for differences among at least three groups, since the two-group case can be covered by a t-test (Gosset, 1908). When there are only two means to compare, the t-test and the F-test are equivalent; the relation between ANOVA and t is given by F = t2. An extension of one-way ANOVA is two-way analysis of variance that examines the influence of two different categorical independent variables on one dependent variable.
Assumptions
The results of a one-way ANOVA can be considered reliable as long as the following assumptions are met:
If data are ordinal, a non-parametric alternative to this test should be used such as Kruskal–Wallis one-way analysis of variance. If the variances are not known to be equal, a generalization of 2-sample Welch's t-test can be used.
Departures from population normality
ANOVA is a relatively robust procedure with respect to violations of the normality assumption.
The one-way ANOVA can be generalized to the factorial and multivariate layouts, as well as to the analysis of covariance.
It is often stated in popular literature that none of these F-tests are robust when there are severe violations of the assumption that each population follows the normal distribution, particularly for small alpha levels and unbalanced layouts. Furthermore, it is also claimed that if the underlying assumption of homoscedasticity is violated, the Type I error properties degenerate much more severely.
However, this is a misconception, based on work done in the 1950s and earlier. The first comprehensive investigation of the issue by Monte Carlo simulation was Donaldson (1966). He showed that under the usual departures (positive skew, unequal variances) "the F-test is conservative" so is less likely than it should be to find that a variable is significant. However, as either the sample size or the number of cells increases, "the power curves seem to converge to that based on the normal distribution". Tiku (1971) found that "the non-normal theory power of F is found to differ from the normal theory power by a correction term which decreases sharply with increasing sample size." The problem of non-normality, especially in large samples, is far less serious than popular articles would suggest.
The current view is that "Monte-Carlo studies were used extensively with normal distribution-based tests to determine how sensitive they are to violations of the assumption of normal distribution of the analyzed variables in the population. The general conclusion from these studies is that the consequences of such violations are less severe than previously thought. Although these conclusions should not entirely discourage anyone from being concerned about the normality assumption, they have increased the overall popularity of the distribution-dependent statistical tests in all areas of research."
For nonparametric alternatives in the factorial layout, see Sawilowsky. For more discussion see ANOVA on ranks.
The model
The normal linear model describes treatment groups with probability distributions which are identically bell-shaped (normal) curves with different means. Thus fitting the models requires only the means of each treatment group and a variance calculation (an average variance within the treatment groups is used). Calculations of the means and the variance are performed as part of the hypothesis test.
The commonly used normal linear models for a completely randomized experiment are:
or
where
The index i over the experimental units can be interpreted several ways. In some experiments, the same experimental unit is subject to a range of treatments; i may point to a particular unit. In others, each treatment group has a distinct set of experimental units; i may simply be an index into the
The data and statistical summaries of the data
One form of organizing experimental observations
Comparing model to summaries:
The hypothesis test
Given the summary statistics, the calculations of the hypothesis test are shown in tabular form. While two columns of SS are shown for their explanatory value, only one column is required to display results.
Analysis summary
The core ANOVA analysis consists of a series of calculations. The data is collected in tabular form. Then
If the experiment is balanced, all of the
In a more complex experiment, where the experimental units (or environmental effects) are not homogeneous, row statistics are also used in the analysis. The model includes terms dependent on
Example
Consider an experiment to study the effect of three different levels of a factor on a response (e.g. three levels of a fertilizer on plant growth). If we had 6 observations for each level, we could write the outcome of the experiment in a table like this, where a1, a2, and a3 are the three levels of the factor being studied.
The null hypothesis, denoted H0, for the overall F-test for this experiment would be that all three levels of the factor produce the same response, on average. To calculate the F-ratio:
Step 1: Calculate the mean within each group:
Step 2: Calculate the overall mean:
Step 3: Calculate the "between-group" sum of squared differences:
where n is the number of data values per group.
The between-group degrees of freedom is one less than the number of groups
so the between-group mean square value is
Step 4: Calculate the "within-group" sum of squares. Begin by centering the data in each group
The within-group sum of squares is the sum of squares of all 18 values in this table
The within-group degrees of freedom is
Thus the within-group mean square value is
Step 5: The F-ratio is
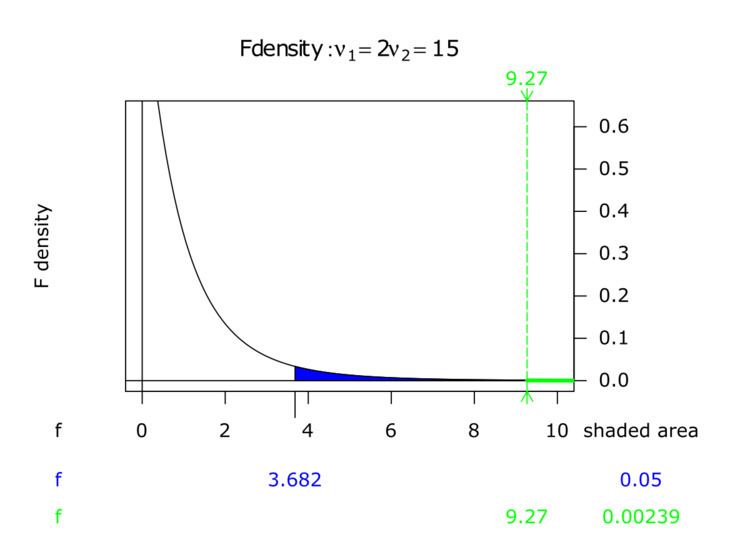
The critical value is the number that the test statistic must exceed to reject the test. In this case, Fcrit(2,15) = 3.68 at α = 0.05. Since F=9.3 > 3.68, the results are significant at the 5% significance level. One would reject the null hypothesis, concluding that there is strong evidence that the expected values in the three groups differ. The p-value for this test is 0.002.
After performing the F-test, it is common to carry out some "post-hoc" analysis of the group means. In this case, the first two group means differ by 4 units, the first and third group means differ by 5 units, and the second and third group means differ by only 1 unit. The standard error of each of these differences is
Note F(x, y) denotes an F-distribution cumulative distribution function with x degrees of freedom in the numerator and y degrees of freedom in the denominator.