
 | ||
Digital signal processing (DSP) is a ubiquitous methodology in scientific and engineering computations. However, practically, DSP problems are often not only 1-D. For instance, image data are 2-D signals and radar signals are 3-D signals. While the number of dimension increases, the time and/or storage complexity of processing digital signals grow dramatically. Therefore, solving DSP problems in real-time is extremely difficult in reality.
Contents
- Motivation
- Existing Approaches
- Lower Sampling Rate
- Digital Signal Processors DSPs
- Supercomputer Assistance
- GPU Acceleration
- GPGPU Computations
- GPU Programming Languages
- CUDA
- OpenCL
- C Amp
- OpenAcc
- m m Matrix Multiplication
- Multidimensional Convolution M D Convolution
- Multidimensional Discrete Time Fourier Transform M D DTFT
- Digital Filter Design
- Radar Signal Reconstruction and Analysis
- Self Driving Car
- Medical Image Processing
- References
Modern general purpose graphics processing units (GPGPUs) are considered as having an excellent throughput on vector operations and numeric manipulations through a high degree of parallel computations. While processing digital signals, particularly multidimensional signals, often involves a series of vector operations on massive amount of independent data samples, GPGPUs are now widely employed to accelerate multidimensional DSP, such as image processing, video codecs, radar signal analysis, sonar signal processing, and ultrasound scanning. Conceptually, using GPGPU devices to perform multidimensional DSP is able to dramatically reduce the computation complexity compared with central processing units (CPUs), digital signal processors (DSPs), or other FPGA accelerators.
Motivation
Processing multidimensional signals is a common problem in scientific research and/or engineering computations. Typically, a DSP problem's computation complexity grows exponentially with the number of dimensions. Notwithstanding, with a high degree of time and storage complexity, it is extremely difficult to process multidimensional signals in real-time. Although many fast algorithms (e.g. FFT) have been proposed for 1-D DSP problems, they are still not efficient enough to be adapted in high dimensional DSP problems. Therefore, it is still hard to obtain the desired computation results with digital signal processors (DSPs). Hence, better algorithms and hardware architecture are needed to accelerate multidimensional DSP computations.
Existing Approaches
Practically, to accelerate multidimensional DSP, some common approaches have been proposed and developed in the past decades.
Lower Sampling Rate
A makeshift to achieve real-time requirement in multidimensional DSP applications is to use a lower sampling rate, which can efficiently reduce the number of samples to be processed at one time and thereby decrease the total processing time. However, this can lead to the aliasing problem due to the sampling theorem and poor-quality outputs. In some applications, such as military radars and medical images, we are eager to have highly precise and accurate results. In such cases, using a lower sampling rate to reduce the amount of computation in the multidimensional DSP domain is not always allowable.
Digital Signal Processors (DSPs)
Digital signal processors are designed specifically to process vector operations. They have been widely used in DSP computations for decades. However, most digital signal processors are only capable of manipulating few operations in parallel. This kind of designs is sufficient to accelerate audio processing (1-D signals) and image processing (2-D signals). However, with a large amount of data samples in multidimensional signals, this is still not powerful enough to retrieve computation results in real-time.
Supercomputer Assistance
In order to accelerate multidimensional DSP computations, using dedicated supercomputers or cluster computers is required in some circumstances, e.g., weather forecasting and military radars. Nevertheless, using supercomputers designated to simply perform DSP operations takes considerable money cost and energy consumption. Also, it is not practical and suitable for all multidimensional DSP applications.
GPU Acceleration
GPUs are originally devised to accelerate image processing and video stream rendering. Moreover, since modern GPUs have good ability to perform numeric computations in parallel with a relatively low cost and better energy efficiency, GPUs are becoming a popular alternative to replace supercomputers performing multidimensional DSP.
GPGPU Computations
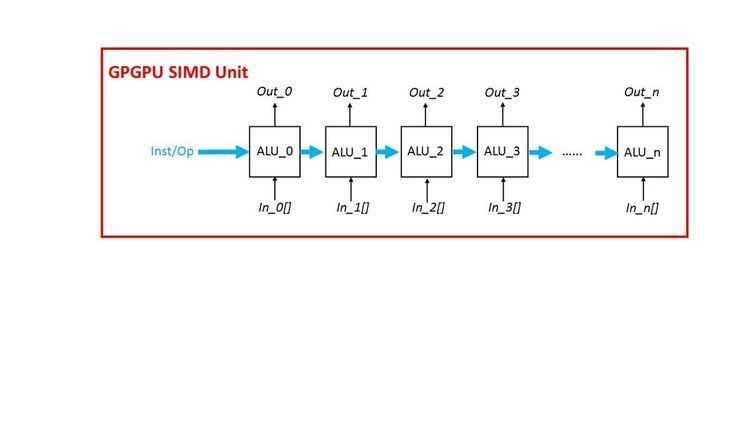
Modern GPU designs are mainly based on the SIMD (Single Instruction Multiple Data) computation paradigm. This type of GPU devices is so-called general-purpose GPUs (GPGPUs).
GPGPUs are able to perform an operation on multiple independent data concurrently with their vector or SIMD functional units. A modern GPGPU can spawn thousands of concurrent threads and process all threads in a batch manner. With this nature, GPGPUs can be employed as DSP accelerators easily while many DSP problems can be solved by divide-and-conquer algorithms. A large scale and complex DSP problem can be divided into a bunch of small numeric problems and be processed altogether at one time so that the overall time complexity can be reduced significantly. For example, multiplying two M × M matrices can be processed by M × M concurrent threads on a GPGPU device without any output data dependency. Therefore, theoretically, by means of GPGPU acceleration, we can gain up to M × M speedup compared with a traditional CPU or digital signal processor.
GPU Programming Languages
Currently, there are several existing programming languages or interfaces which support GPGPU programming.
CUDA
CUDA is the standard interface to program NVIDIA GPUs. NVIDIA also provides many CUDA libraries to support DSP acceleration on NVIDIA GPU devices.
OpenCL
OpenCL is an industrial standard which was originally proposed by Apple Inc. and is maintained and developed by the Khronos Group now. OpenCL provides C++ like APIs for programming different devices universally, including GPGPUs.
The following figure illustrates the execution flow of launching an OpenCL program on a GPU device. The CPU first detects OpenCL devices (GPU in this case) and than invokes a just-in-time compiler to translate the OpenCL source code into target binary. CPU then sends data to GPU to perform computations. When the GPU is processing data, CPU is free to process its own tasks.
C++ Amp
C++ Amp is a programming model proposed by Microsoft. C++ Amp is a C++ based library designed for programming SIMD processors
OpenAcc
OpenAcc is a programming standard for parallel computing developed by Cray, CAPS, NVIDIA and PGI. OpenAcc targets programming for CPU and GPU heterogeneous systems with C, C++, and Fortran extensions.
m × m Matrix Multiplication
Suppose A and B are two m × m matrices and we would like to compute C = A × B.
To compute each element in C takes m multiplications and (m – 1) additions. Therefore, with a CPU implementation, the time complexity to achieve this computation is Θ(n3) in the following C example. However, we have known that elements in C are independent of each other. Hence, the computation can be fully parallelized by SIMD processors, such as GPGPU devices. With a GPGPU implementation, the time complexity significantly reduces to Θ(n) by unrolling the for-loop as shown in the following OpenCL example.
Multidimensional Convolution (M-D Convolution)
Convolution is a frequently used operation in DSP. To compute the 2-D convolution of two m × m signals, it requires m2 multiplications and m × (m – 1) additions for an output element. That is, the overall time complexity is Θ(n4) for the entire output signal. As the following OpenCL example shows, with GPGPU acceleration, the total computation time effectively decreases to Θ(n2) since all output elements are data independent.
2-D convolution equation:
Note that, although the example demonstrated above is a 2-D convolution, a similar approach can be adopted for a higher dimension system. Overall, for a s-D convolution, a GPGPU implementation has time complexity Θ(ns), whereas a CPU implementation has time complexity Θ(n2s).
M-D convolution equation:
Multidimensional Discrete Time Fourier Transform (M-D DTFT)
In addition to convolution, the discrete-time Fourier transform (DTFT) is another technique which is often used in system analysis.
Practically, to implement an M-D DTFT, we can perform M times 1-D DFTF and matrix transpose with respect to each dimension. With a 1-D DTFT operation, GPGPU can conceptually reduce the complexity from Θ(n2) to Θ(n) as illustrated by the following example of OpenCL implementation. That is, an M-D DTFT the complexity of GPGPU can be computed on a GPU with a complexity of Θ(n2). While some GPGPUs are also equipped with hardware FFT accelerators internally, this implementation might be also optimized by invoking the FFT APIs or libraries provided by GPU manufacture.
Digital Filter Design
Designing a multidimensional digital filter is a big challenge, especially IIR filters. Typically it relies on computers to solve difference equations and obtain a set of approximated solutions. While GPGPU computation is becoming popular, several adaptive algorithms have been proposed to design multidimensional FIR and/or IIR filters by means of GPGPUs.
Radar Signal Reconstruction and Analysis
Radar systems usually require to reconstruct a numerous amount of 3-D or 4-D data samples in real-time. Traditionally, particularly in military, this needs supercomputers' support. Nowadays, GPGPUs are also employed to replace supercomputers to process radar signals. For example, to process synthetic aperture radar (SAR) signals, it usually involves multidimensional FFT computations. GPGPUs can be used to rapidly perform FFT and/or iFFT in this kind of applications.
Self-Driving Car
Many self-driving cars apply 3-D image recognition techniques to auto control the vehicles. Clearly, to accommodate the fast changing exterior environment, the recognition and decision processes must be done in real-time. GPGPUs are excellent devices to achieve the goal.
Medical Image Processing
In order to have accurate diagnosis, 2-D or 3-D medical signals, such as ultrasound, X-ray, MRI, and CT, often require very high sampling rate and image resolutions to reconstruct images. By applying GPGPUs' superior computation power, it was shown that we can acquire better-quality medical images