
 | ||
The Mokken Scale is a psychometric method of data reduction. A Mokken scale is a unidimensional scale that consists of hierarchically-ordered items that measure the same underlying, latent concept. This method is named after the political scientist Rob Mokken who suggested it in 1971.
Contents
Mokken Scales have been used in psychology, education, political science, public opinion and medicine.
Overview
Mokken scaling belongs to Item response theory. In essence, a Mokken scale is a non-parametric, probabilistic version of Guttman scale. Both Guttman and Mokken scaling can be used to assess whether a number of items measure the same underlying concept. Both Guttman and Mokken scaling are based on the assumption that the items are hierarchically ordered: this means that they are ordered by degree of "difficulty". Difficulty here means the percentage of respondents that answers the question affirmatively. The hierarchical order means that a respondent who answered a difficult question correctly is assumed to answer an easy question correctly. The key difference between a Guttman and Mokken scale is that Mokken scaling is probabilistic in nature. The assumption is not that every respondent who answered a difficult question affirmatively will necessarily answer an easy question affirmatively. Violations of this are called Guttman errors. Instead, the assumption is that respondents who answered a difficult question affirmatively are more likely answer an easy question affirmatively. The scalability of the scale is measured by Loevinger's coefficient H. H compares the actual Guttman errors to the expected number of errors if the items would be unrelated.
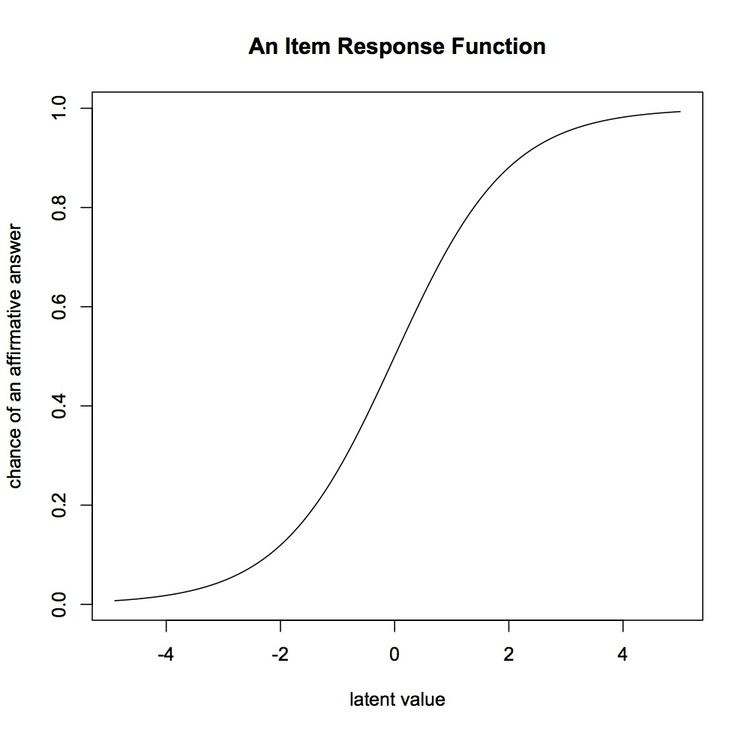
The chance that a respondent will answer an item correctly is described by an Item Response Function. Mokken scales are similar to Rasch scales, in that they both adapted Guttman scales to a probabilistic model. The key difference between Mokken scales and Rasch scales is that the latter assumes that all items have the same Item Response Function. In Mokken scaling the Item Response Functions differ for different items.
Mokken scales can come in two forms: first as the Double Monotonicity model, where the items can differ in their difficulty. It is essentially, is an ordinal version of Rasch scale; and second, as the Monotone Homogeneity model, where items differ in their discrimination parameter, which means that there can be a weaker relationship between some items and the latent variable and other items and the latent variable. Double Monotonicity models are used most often.
Double Monotonicity models are based on three assumptions.
- There is a unidimensional latent trait on which subject and items can be ordered.
- The item response function is monotonically nondecreasing. This means that as one moves from one side of the latent variable to the other, the chance of giving a positive response should never decrease.
- The items are locally stochastically independent: this means that responses to any two items by the same respondent should not be the function any other aspect of the respondent or the item, but his or her position on the latent trait.
Extensions
While Mokken scaling analysis was originally developed to measure the extent to which individual dichotomous items form a scale, it has since been extended for polytomous items. Moreover, while Mokken scaling analysis is a confirmatory method, meant to test whether a number of items form a coherent scale (like Confirmatory factor analysis), an Automatic Item Selection Procedure has been developed to explore which latent dimensions structure responses on a number of observable items (like Factor analysis).