
 | ||
Mode choice analysis is the third step in the conventional four-step transportation forecasting model. The steps, in order, are trip generation, trip distribution, mode choice analysis, and route assignment. Trip distribution's zonal interchange analysis yields a set of origin destination tables that tells where the trips will be made. Mode choice analysis allows the modeler to determine what mode of transport will be used, and what modal share results.
Contents
- Diversion curve techniques
- Disaggregate travel demand models
- Psychological roots
- Econometric formulation
- Econometric estimation
- Additional topics
- Returning to roots
- References
The early transportation planning model developed by the Chicago Area Transportation Study (CATS) focused on transit. It wanted to know how much travel would continue by transit. The CATS divided transit trips into two classes: trips to the Central Business District, or CBD (mainly by subway/elevated transit, express buses, and commuter trains) and other (mainly on the local bus system). For the latter, increases in auto ownership and use were a trade-off against bus use; trend data were used. CBD travel was analyzed using historic mode choice data together with projections of CBD land uses. Somewhat similar techniques were used in many studies. Two decades after CATS, for example, the London study followed essentially the same procedure, but in this case, researchers first divided trips into those made in the inner part of the city and those in the outer part. This procedure was followed because it was thought that income (resulting in the purchase and use of automobiles) drove mode choice.
Diversion curve techniques
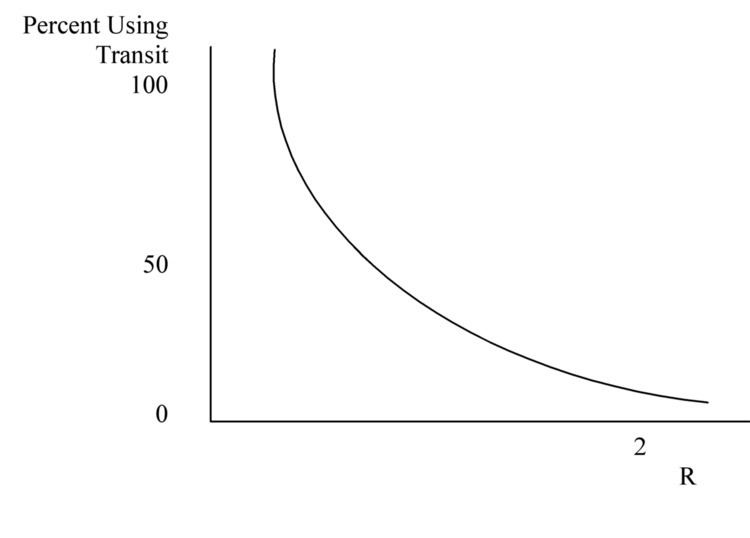
The CATS had diversion curve techniques available and used them for some tasks. At first, the CATS studied the diversion of auto traffic from streets and arterial roads to proposed expressways. Diversion curves were also used for bypasses built around cities to find out what percent of traffic would use the bypass. The mode choice version of diversion curve analysis proceeds this way: one forms a ratio, say:
where:
cm = travel time by mode m andR is empirical data in the form:Given the R that we have calculated, the graph tells us the percent of users in the market that will choose transit. A variation on the technique is to use costs rather than time in the diversion ratio. The decision to use a time or cost ratio turns on the problem at hand. Transit agencies developed diversion curves for different kinds of situations, so variables like income and population density entered implicitly.
Diversion curves are based on empirical observations, and their improvement has resulted from better (more and more pointed) data. Curves are available for many markets. It is not difficult to obtain data and array results. Expansion of transit has motivated data development by operators and planners. Yacov Zahavi’s UMOT studies, discussed earlier, contain many examples of diversion curves.
In a sense, diversion curve analysis is expert system analysis. Planners could "eyeball" neighborhoods and estimate transit ridership by routes and time of day. Instead, diversion is observed empirically and charts drawn.
Disaggregate travel demand models
Travel demand theory was introduced in the appendix on traffic generation. The core of the field is the set of models developed following work by Stan Warner in 1962 (Strategic Choice of Mode in Urban Travel: A Study of Binary Choice). Using data from the CATS, Warner investigated classification techniques using models from biology and psychology. Building from Warner and other early investigators, disaggregate demand models emerged. Analysis is disaggregate in that individuals are the basic units of observation, yet aggregate because models yield a single set of parameters describing the choice behavior of the population. Behavior enters because the theory made use of consumer behavior concepts from economics and parts of choice behavior concepts from psychology. Researchers at the University of California, Berkeley (especially Daniel McFadden, who won a Nobel Prize in Economics for his efforts) and the Massachusetts Institute of Technology (Moshe Ben-Akiva) (and in MIT associated consulting firms, especially Cambridge Systematics) developed what has become known as choice models, direct demand models (DDM), Random Utility Models (RUM) or, in its most used form, the multinomial logit model (MNL).
Choice models have attracted a lot of attention and work; the Proceedings of the International Association for Travel Behavior Research chronicles the evolution of the models. The models are treated in modern transportation planning and transportation engineering textbooks.
One reason for rapid model development was a felt need. Systems were being proposed (especially transit systems) where no empirical experience of the type used in diversion curves was available. Choice models permit comparison of more than two alternatives and the importance of attributes of alternatives. There was the general desire for an analysis technique that depended less on aggregate analysis and with a greater behavioral content. And there was attraction, too, because choice models have logical and behavioral roots extended back to the 1920s as well as roots in Kelvin Lancaster’s consumer behavior theory, in utility theory, and in modern statistical methods.
Psychological roots
Early psychology work involved the typical experiment: Here are two objects with weights, w1 and w2, which is heavier? The finding from such an experiment would be that the greater the difference in weight, the greater the probability of choosing correctly. Graphs similar to the one on the right result.
Louis Leon Thurstone proposed (in the 1920s) that perceived weight,
w = v + e,where v is the true weight and e is random with
E(e) = 0.The assumption that e is normally and identically distributed (NID) yields the binary probit model.
Econometric formulation
Economists deal with utility rather than physical weights, and say that
observed utility = mean utility + random term.The characteristics of the object, x, must be considered, so we have
u(x) = v(x) + e(x).If we follow Thurston's assumption, we again have a probit model.
An alternative is to assume that the error terms are independently and identically distributed with a Weibull, Gumbel Type I, or double exponential distribution. (They are much the same, and differ slightly in their tails (thicker) from the normal distribution). This yields the multinomial logit model (MNL). Daniel McFadden argued that the Weibull had desirable properties compared to other distributions that might be used. Among other things, the error terms are normally and identically distributed. The logit model is simply a log ratio of the probability of choosing a mode to the probability of not choosing a mode.
Observe the mathematical similarity between the logit model and the S-curves we estimated earlier, although here share increases with utility rather than time. With a choice model we are explaining the share of travelers using a mode (or the probability that an individual traveler uses a mode multiplied by the number of travelers).
The comparison with S-curves is suggestive that modes (or technologies) get adopted as their utility increases, which happens over time for several reasons. First, because the utility itself is a function of network effects, the more users, the more valuable the service, higher the utility associated with joining the network. Second because utility increases as user costs drop, which happens when fixed costs can be spread over more users (another network effect). Third technological advances, which occur over time and as the number of users increases, drive down relative cost.
An illustration of a utility expression is given:
where
Pi = Probability of choosing mode i.PA = Probability of taking autocA,cT = cost of auto, transittA,tT = travel time of auto, transitI = incomeN = Number of travelersWith algebra, the model can be translated to its most widely used form:
It is fair to make two conflicting statements about the estimation and use of this model:
- it's a "house of cards", and
- used by a technically competent and thoughtful analyst, it's useful.
The "house of cards" problem largely arises from the utility theory basis of the model specification. Broadly, utility theory assumes that (1) users and suppliers have perfect information about the market; (2) they have deterministic functions (faced with the same options, they will always make the same choices); and (3) switching between alternatives is costless. These assumptions don’t fit very well with what is known about behavior. Furthermore, the aggregation of utility across the population is impossible since there is no universal utility scale.
Suppose an option has a net utility ujk (option k, person j). We can imagine that having a systematic part vjk that is a function of the characteristics of an object and person j, plus a random part ejk, which represents tastes, observational errors and a bunch of other things (it gets murky here). (An object such as a vehicle does not have utility, it is characteristics of a vehicle that have utility.) The introduction of e lets us do some aggregation. As noted above, we think of observable utility as being a function:
where each variable represents a characteristic of the auto trip. The value β0 is termed an alternative specific constant. Most modelers say it represents characteristics left out of the equation (e.g., the political correctness of a mode, if I take transit I feel morally righteous, so β0 may be negative for the automobile), but it includes whatever is needed to make error terms NID.
Econometric estimation
Turning now to some technical matters, how do we estimate v(x)? Utility (v(x)) isn’t observable. All we can observe are choices (say, measured as 0 or 1), and we want to talk about probabilities of choices that range from 0 to 1. (If we do a regression on 0s and 1s we might measure for j a probability of 1.4 or −0.2 of taking an auto.) Further, the distribution of the error terms wouldn’t have appropriate statistical characteristics.
The MNL approach is to make a maximum likelihood estimate of this functional form. The likelihood function is:
we solve for the estimated parameters
that max L*. This happens when:
The log-likelihood is easier to work with, as the products turn to sums:
Consider an example adopted from John Bitzan’s Transportation Economics Notes. Let X be a binary variable that is γ and 0 with probability (1 − gamma). Then f(0) = (1 − γ) and f(1) = γ. Suppose that we have 5 observations of X, giving the sample {1,1,1,0,1}. To find the maximum likelihood estimator of γ examine various values of γ, and for these values determine the probability of drawing the sample {1,1,1,0,1} If γ takes the value 0, the probability of drawing our sample is 0. If γ is 0.1, then the probability of getting our sample is: f(1,1,1,0,1) = f(1)f(1)f(1)f(0)f(1) = 0.1×0.1×0.1×0.9×0.1 = 0.00009 We can compute the probability of obtaining our sample over a range of γ – this is our likelihood function. The likelihood function for n independent observations in a logit model is
where: Yi = 1 or 0 (choosing e.g. auto or not-auto) and Pi = the probability of observing Yi = 1
The log likelihood is thus:
In the binomial (two alternative) logit model,
The log-likelihood function is maximized setting the partial derivatives to zero:
The above gives the essence of modern MNL choice modeling.
Additional topics
Topics not touched on include the “red bus, blue bus” problem; the use of nested models (e.g., estimate choice between auto and transit, and then estimate choice between rail and bus transit); how consumers’ surplus measurements may be obtained; and model estimation, goodness of fit, etc. For these topics see a textbook such as Ortuzar and Willumsen (2001).
Returning to roots
The discussion above is based on the economist’s utility formulation. At the time MNL modeling was developed there was some attention to psychologist's choice work (e.g., Luce’s choice axioms discussed in his Individual Choice Behavior, 1959). It has an analytic side in computational process modeling. Emphasis is on how people think when they make choices or solve problems (see Newell and Simon 1972). Put another way, in contrast to utility theory, it stresses not the choice but the way the choice was made. It provides a conceptual framework for travel choices and agendas of activities involving considerations of long and short term memory, effectors, and other aspects of thought and decision processes. It takes the form of rules dealing with the way information is searched and acted on. Although there is a lot of attention to behavioral analysis in transportation work, the best of modern psychological ideas are only beginning to enter the field. (e.g. Golledge, Kwan and Garling 1984; Garling, Kwan, and Golledge 1994).