
 | ||
MateCat is a web-based computer-assisted translation (CAT) tool, of which there are several on the current market. MateCat is released as open source software under the Lesser General Public License (LGPL) from the Free Software Foundation.
Contents
The project
MateCat, acronym of Machine Translation Enhanced Computer Assisted Translation, is a 3-year research project (11/2011-10/2014) funded by the European Union’s Seventh Framework Programme for research, technological development and demonstration under grant agreement #287688. It has received already over €2,500,000 of European funds.
The project consortium is led by FBK (Fondazione Bruno Kessler), an international research center based in Trento, Italy.
CAT tools
The objective of MateCat is to improve translation workflow by integrating machine translation (MT) and human translation within the so-called computer aided translation (CAT) framework. CAT tools represent nowadays the dominant technology in the translation industry. They provide translators with text editors that can manage several document formats and suitably arrange their content into text segments ready to be translated.
CAT tools provide access to translation memories (TMs), terminology databases, concordance tools and, more recently, to machine translation (MT) engines. A TM is basically a repository of translated segments. During translation, the CAT tool queries the TM to search for exact or fuzzy matches of the current source segment. These matches are proposed to the user as translation suggestions. Once a segment is translated, its source and target texts are added to the TM for future queries. The integration of suggestions from an MT engine as a complement to TM matches is motivated by recent studies, which have shown that post-editing MT suggestions substantially improves the level of accuracy in translations.
Statistical MT
The MateCat tool runs as a web-server accessible through Chrome. The CAT web-server connects with other services via open APIs: the TM server MyMemory, the commercial Google Translate (GT) MT server, and a list of Moses -based servers specified in a configuration file. While MyMemory’s and GT’s servers are always running and available, customized Moses servers have to be first installed and set-up. Communication with the Moses servers extends the GT API in order to support self-tuning, user-adaptive and informative MT functions. XLIFF is the file format natively supported by the open source version of the MateCat tool; however external file converters can be added in the MateCat configuration file. The tool supports Unicode (UTF-8) encoding, including non-Latin alphabets and right-to-left languages, and handles texts embedding mark-up tags.
MateCat leverages the growing interest and expectations in statistical MT by advancing the state-of-the-art along three directions: Self-tuning MT, User adaptive MT, Informative MT.
Research along these three directions has converged into a new generation CAT software, which is both an enterprise level translation workbench as well as an advanced research platform for integrating new MT functions, running post-editing experiments and measuring user productivity. These include: i) an advanced API for the Moses Toolkit, customizable to languages and domains, ii) ease of use through a clean and intuitive web interface that enables the collaboration of multiple users on the same project, iii) concordances, terminology databases and support for customizable quality estimation components and iv) advanced logging functionalities.
MT support
The tool supports Moses-based servers able to provide an enhanced CAT-MT communication. In particular, the GT API is augmented with feedback information provided to the MT engine every time a segment is post-edited as well as enriched MT output, including confidence scores, word lattices, etc. The developed MT server supports multi-threading to serve multiple translators, handles text segments including tags and adapts from the post-edits performed by each user
Context-aware translation
MateCat also provides suggestions by MT which are consistent with respect not only to the already edited segments but also, in theory, to the whole document. This context information will be embedded in the statistical models and should enable better disambiguation, for instance, between lexical alternatives. The context-based models will combine information about recurring terms and expressions extracted during the document analysis with the corresponding chosen and confirmed translations as soon as they become available. In particular, translation constraints related to inter-sentence and intra-sentence anaphoric expressions, to syntactic concordances, and to lexical coherence will be taken into account by means of specific statistical models.
Real-time processing
The core components of traditional MT systems, that is, the translation and the language models, are generally static: they never change after an initial training phase. This means that they are unsuitable for a dynamic environment like the one that MateCat is designing for translators. In order to model the dynamic changes depicted in the two previous tasks, MateCat developed innovative data-structures that can be rapidly and effectively updated as soon as a new translation is supplied by the user, and innovative, efficient algorithms for performing this adaptation in such a way that the whole process takes place in real time and is transparent to the translator. Moreover, efficiency will be improved by taking advantage of single CPU multithreading, as well as distributed computing facilities running on private clusters or computer clouds.
Edit log
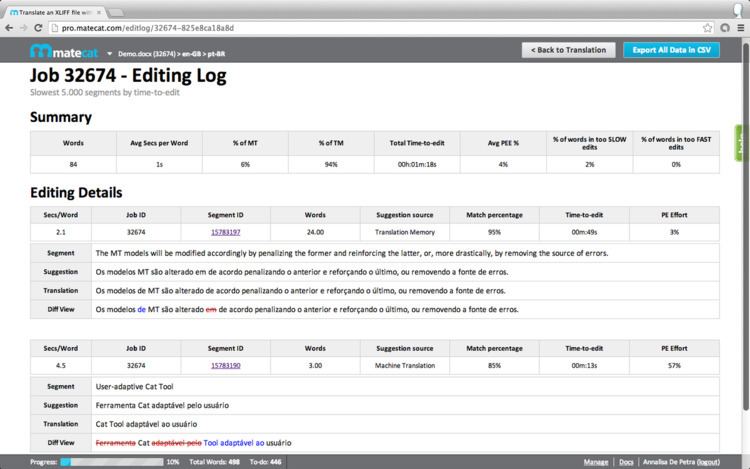
During post-editing the tool collects timing information for each segment, which is updated every time the segment is opened and closed. Moreover, for each segment, information is collected about the generated suggestions and the one that has actually been post-edited. This information is accessible at any time through a link in the Editing Page, named Editing Log. The Editing Log page (Figure 1) shows a summary of the overall editing performed so far on the project, such as the average translation speed and post-editing effort and the percentage of top suggestions coming from MT or the TM. Moreover, for each segment, sorted from the slowest to the fastest in terms of translation speed, detailed statistics about the performed edit operations are reported. This information, with even more details, can be also downloaded as a CSV file to perform a more detailed post-editing analysis. While the information shown in the Edit Log page is very useful to monitor progress of a translation project in real time, the CSV file is a fundamental source of information for detailed productivity analyses once the project is ended.
Applications
MateCat has been exploited by the MateCat project to investigate new MT functions and to evaluate them in a real professional setting, in which translators have at disposal all the sources of information they are used to work with. Moreover, taking advantage of its flexibility and ease of use, the tool has been recently exploited for data collection and education purposes (a course on CAT technology for students in translation studies). An initial version of the tool has also been leveraged by the CasmaCat project to create a workbench, particularly suitable for investigating advanced interaction modalities such as interactive MT, eye tracking, and handwritten input. Currently the tool is employed by Translated.net for their internal translation projects and is being tested by several international companies, both language service providers and IT companies. This has made possible to collect continuous feedback from hundreds of translators, which besides helping us to improve the robustness of the tool is also influencing the way new MT functions will be integrated to supply the best help to the final user.